การไฮไลท์ใจความสำคัญภาษาไทยแบบอัตโนมัติด้วย Bert Model และ PageRank Algorithm

บทความโดย ผศ.ดร.ณัฐโชติ พรหมฤทธิ์ และ อ.ดร.สัจจาภรณ์ ไวจรรยา
ภาควิชาคอมพิวเตอร์
คณะวิทยาศาสตร์
มหาวิทยาลัยศิลปากร
Text Summarization คือ การสรุปเนื้อหาในเอกสารให้สั้นลงโดยยังคงได้ความหมายหลักเหมือนเอกสารต้นฉบับ การทำ Text Summarization ด้วยมือเป็นงานที่ใช้เวลาและแรงกายค่อนข้างมาก ดังนั้นการทำ Text Summarization แบบอัตโนมัติจึงได้รับความสนใจอย่างมากในปัจจุบัน
เราสามารถแบ่งการทำ Text Summarization ออกเป็น 2 แบบหลัก ๆ คือ แบบ Extraction-based Summarization และแบบ Abstraction-based Summarization
Extraction-based จะเป็นการเลือกคำ หรือประโยคจากเอกสารต้นฉบับ คล้าย ๆ กับการ ไฮไลท์ข้อความในเอกสารด้วยปากกา โดยมากจะใช้เทคนิคพวก Unsupervised Learning เพื่อเลือกประโยคในเอกสาร ขณะที่เทคนิค Abstraction-based จะเป็นการสรุปความโดยใช้ Model พวก Deep Learning เพื่อถอดความและสร้างเอกสารใหม่ที่สั้นกว่าเอกสารต้นฉบับ
การทำ Text Summarization แบบ Abstraction-based เพื่อให้ได้ทั้งใจความสำคัญและข้อความที่ถูกต้องตามหลักไวยกรณ์ในแต่ละภาษา ยังคงเป็นสิ่งท้าทายในปัจจุบัน ขณะที่การทำ Text Summarization แบบ Extraction-based จะใช้ความพยายามที่น้อยกว่าแต่ก็สามารถได้ผลลัพธ์ที่สามารถใช้งานได้ดีระดับหนึ่ง
ในบทความนี้เราจะใช้เทคนิคแบบ Extraction-based เพื่อไฮไลท์ใจความสำคัญของบทความภาษาไทย ด้วยการสร้างกราฟของเอกสารทั้งเอกสาร ที่มีการแทนค่า Weight บนเส้นเชื่อม (Edge) ระหว่างประโยค (Node หรือ Vertex) ด้วยค่า Sentence Similarity (1 - Cosine Distance) โดยใช้ Sentence Vector ที่ได้จาก Wangchanberta แล้วคำนวณค่า PageRank (PR) จากกราฟ โดยเราจะเลือกประโยคที่มีค่า PR มากที่สุด จำนวน 20% ของประโยคทั้งหมดเป็นตัวแทนของเอกสารต้นฉบับครับ
ดึง Vector ของประโยคภาษาไทยจาก Wangchanberta
ผู้เขียนใช้ Colab PRO+ ในการทดลอง โดยก่อนอื่นให้เปลี่ยน Runtime Type ไปใช้ GPU และติดตั้ง Library หลัก 6 ตัว
- เมื่อเปลี่ยน Runtime Type แล้วให้ตรวจสอบการใช้ GPU
!nvidia-smi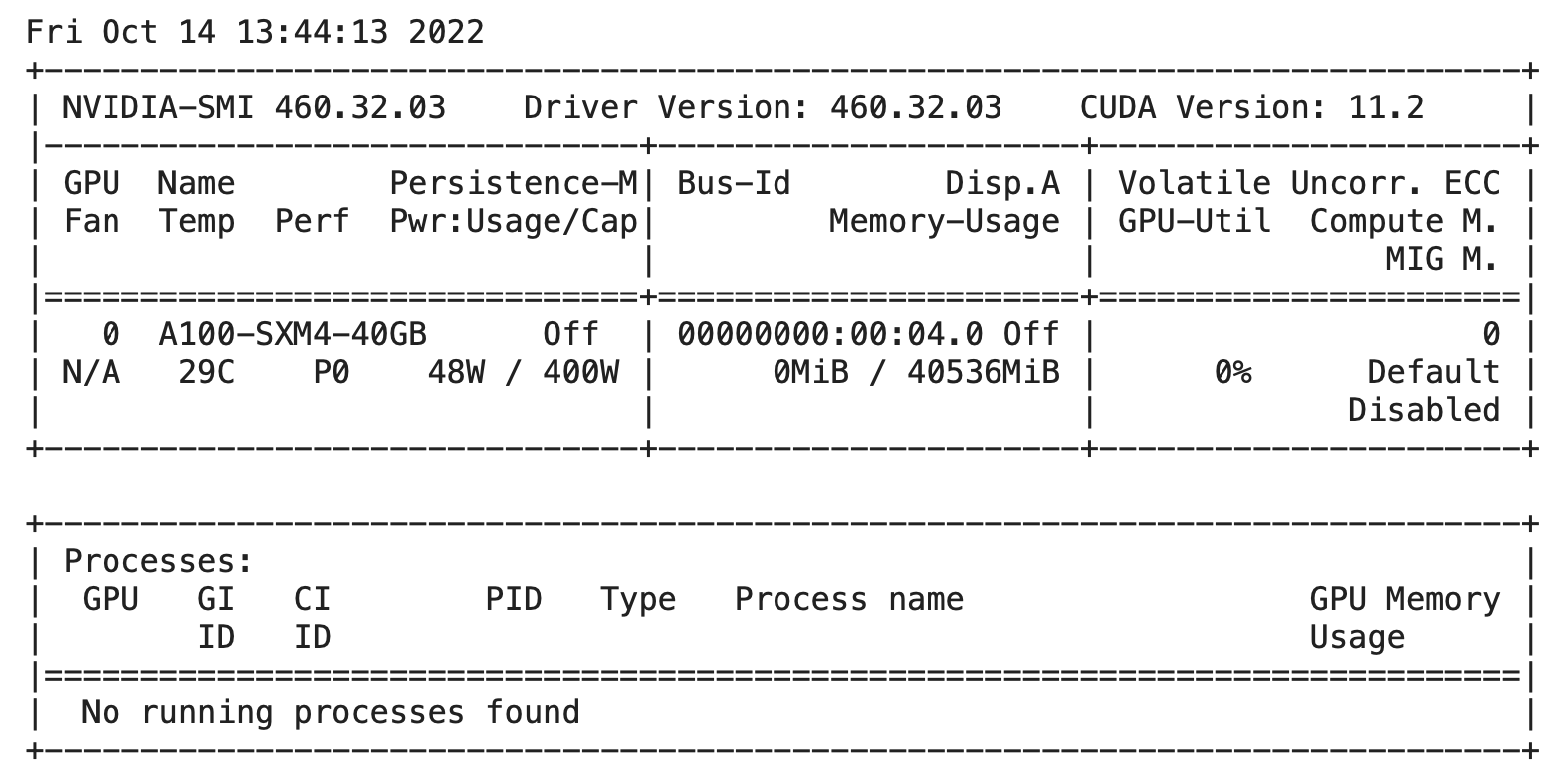
- ติดตั้ง Library หลัก และ Import Library ต่าง ๆ
pip install nltkpip install python-docxpip install transformers sentencepiecepip install rougepip install pythainlpfrom nltk.cluster.util import cosine_distance
import numpy as np
import networkx as nx
import pandas as pd
import docx
from docx.enum.text import WD_COLOR_INDEX
import rouge
from transformers import AutoTokenizer, AutoModel
from pythainlp.tokenize import word_tokenizeเราจะสร้าง Vector ของประโยคจาก Wangchanberta ซึ่งเป็น Pre-Train Model ทางภาษา (Language Model) แบบ Transformer (RoBERTa) ที่ถูก Train ด้วยชุดข้อมูลภาษาไทยจากแหล่งต่าง ๆ เช่น ข่าว วิกิพีเดีย ข้อความในโซเชียลมีเดีย รวมทั้งข้อมูลที่ได้จากการ Crawl เว็บไซต์ ที่มีขนาดถึง 78.5 GB
ในการนำข้อมูลเข้า Wangchanberta ซึ่งเป็น Transformer Model แบบ RoBERTa จะต้องมีการแบ่งประโยคเป็นหน่วยคำย่อยที่เรียกว่า Subword ด้วยไลบรารี่ SentencePiece ดังนั้นเราจึงต้องติดตั้ง Library Transformers และ Sentencepiece ในตอนต้น
- Load Wangchanberta Model
model_name = "airesearch/wangchanberta-base-att-spm-uncased"
model = AutoModel.from_pretrained(model_name)
- Load ตัวตัดหน่วยคำย่อยสำหรับ Wangchanberta Model
tokenizer = AutoTokenizer.from_pretrained(model_name)
- ดึง Subword ของ Wangchanberta Model มาดู
subword = list(tokenizer.vocab.keys())
df = pd.DataFrame(subword, columns =['subword'])
df.shape(25004, 1)
df.head(10)
พบว่ามี Subword ทั้งหมด 25,004 Subword
- ทดลองตัดหน่วยคำย่อยสำหรับ Wangchanberta Model ด้วย Sentencepiece
tokenizer.tokenize('สวัสดีครับชาวโลก')['▁', 'สวัสดีครับ', 'ชาวโลก']
จะได้ Subword ทั้งหมด 3 Subword รวม Space ที่แทนด้วยเครื่องหมาย (_)
- ทดลองเข้ารหัสหน่วยคำย่อย โดยให้ Return Tensors แบบ Pytorch (Wangchanberta จะรับ Input ID และ Attention Mask แบบ Pytorch เข้า Model) ซึ่งจะพบว่า Sentencepiece ได้ใส่ Code 5 (Start Tag) และ Code 6 (Stop Tag) ด้านหน้าและท้ายข้อความที่มีการเข้ารหัส
inputs = tokenizer('สวัสดีครับชาวโลก', return_tensors='pt')
inputs{'input_ids': tensor([[ 5, 10, 5533, 15873, 6]]), 'attention_mask': tensor([[1, 1, 1, 1, 1]])}
inputs['input_ids']tensor([[ 5, 10, 5533, 15873, 6]])
- Decode ข้อความกลับ จะพบ Start Tag <s> และ Stop Tag </s> รวมทั้ง Space ที่ Sentencepiece ได้ใส่มาให้ด้วย
tokenizer.decode(inputs['input_ids'][0])'<s> สวัสดีครับชาวโลก</s>'
- นำเข้าใน Wangchanberta Model
outputs = model(**inputs)
outputs[1].shapetorch.Size([1, 768])
เราจะนำ Sentence Vector ขนาด 768 Dimension จาก Output ของ Wangchanberta Model ไปคำนวณ Sentence Similarity
outputs[1]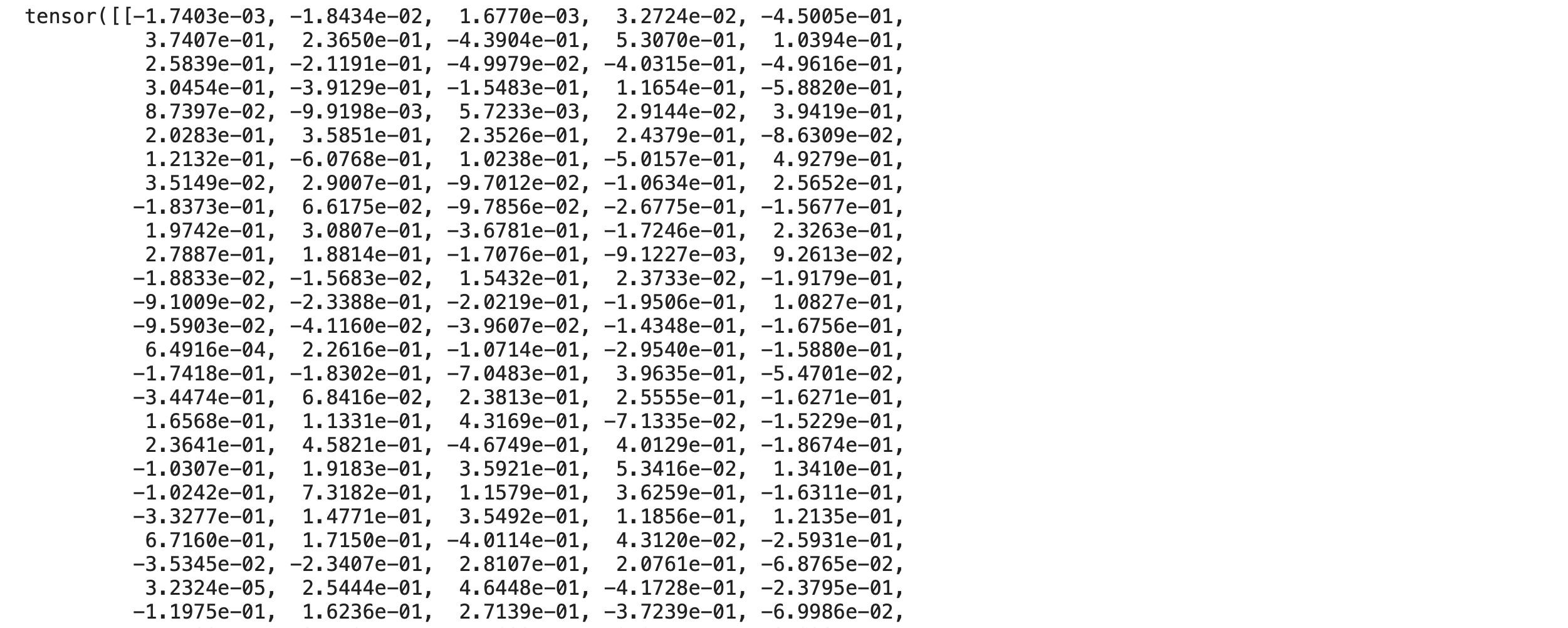
คำนวณ Similarity Matrix จาก Sentence Vector
Similarity Matrix คือ Matrix ที่แสดงค่า Sentence Similarity ของคู่ประโยคแต่ละคู่ในเอกสารที่นำมา Cross กัน ถ้าประโยค 2 ประโยคมีความเหมือนกัน Sentence Similarity จะมีค่าที่มาก
Sentence Similarity เกิดจากการนำ 1 ลบด้วย Cosine Distance ซึ่งเราจะต้องนำ Sentence Vector มาคำนวณค่า Cosine Distance ครับ
เพื่อให้ได้ Vector ที่เป็นตัวแทนที่ดีของประโยคภาษาไทย เราจึงใช้ Wangchanberta Model (ซึ่งเป็น State of the art ทางด้าน Thai Language Model ในปัจจุบัน) ในการสร้าง Sentence Vector
ผู้อ่านสามารถนำข้อความภาษาไทยที่มีการตัดประโยคไว้แล้วของตัวเอง มาใช้ในการไฮไลท์ใจความสำคัญ (แต่ละประโยคจะถูกแบ่งด้วยการขึ้นบรรทัดใหม่) หรือจะ Download มาจากตัวอย่างต่อไปนี้ Text Summarization Dataset ก็ได้
- เมื่อ Dowload มาแล้ว ให้อ่านไฟล์แล้วแบ่งประโยคโดยใช้ฟังก์ชัน splitlines() เพื่อเก็บลงใน List
file_name = 'test_project.txt'
with open(file_name, 'r') as file:
corpus = file.read().splitlines()
print(corpus)
- Remove Space Character ที่ตอนต้นและท้ายประโยค
sentences = [s.strip() for s in corpus]- หาจำนวนประโยคทั้งหมด
sentence_size = len(sentences)
sentence_size74
- แบ่งหน่วยคำย่อยและเข้ารหัส
sentences_tokens = [tokenizer(s, return_tensors="pt") for s in sentences]- นำเข้า Wangchanberta Model
sentences_encode = [model(**token) for token in sentences_tokens]
len(sentences_encode)74
sentences_encode[0][1].shapetorch.Size([1, 768])
โดยผลจากการ Predict จะเป็น Sentence Vector
- ดึงออกจาก Pytorch Tensors แล้วแปลงเป็น Array ด้วยฟังก์ชัน detach().numpy() และลดจำนวน Dimension ของผลลัพธ์ด้วยฟังก์ชัน np.squeeze()
sentences_vec = [np.squeeze(vec[1].detach().numpy()) for vec in sentences_encode]
sentences_vec[0].shape(768,)
- สร้าง Similarity Matrix จากค่า Sentence Similarity (1 - Cosine Distance)
def build_similarity_matrix(sentences):
similarity_matrix = np.zeros((len(sentences), len(sentences)))
for idx1 in range(len(sentences)):
for idx2 in range(len(sentences)):
if idx1 == idx2: #ignore if both are same sentences
continue
similarity_matrix[idx1][idx2] = sentence_similarity(sentences[idx1], sentences[idx2])
return similarity_matrixdef sentence_similarity(sent1, sent2):
return 1 - cosine_distance(sent1, sent2)sentence_similarity_martix = build_similarity_matrix(sentences_vec)
sentence_similarity_martix.shape(74, 74)
sentence_similarity_martix
สร้างกราฟจาก Similarity Matrix
เราจะใช้ Library NetworkX แปลงค่า Sentence Similarity ใน Matrix แถวที่ i และคอลัมน์ที่ j ไปเป็น Weight ที่อยู่บนเส้นเชื่อม (Edge) ของประโยค i และประโยค j ก่อนที่จะนำไปคำนวณค่า PageRank
เราสามารถสร้างกราฟอย่างง่ายด้วยฟังก์ชัน add_edge() ที่มีจำนวน Node 4 Node (A, B, C และ D) รวมทั้งเส้นเชื่อม 4 เส้น โดยกำหนด Weight ให้แก่เส้นเชื่อมแต่ละเส้น และใช้ฟังก์ชัน shortest_path() หาเส้นทางที่สั้นที่สุดได้ดังตัวอย่างต่อไปนี้
G = nx.Graph()
G.add_edge('A', 'B', weight=4)
G.add_edge('B', 'D', weight=2)
G.add_edge('A', 'C', weight=3)
G.add_edge('C', 'D', weight=4)pos = nx.spring_layout(G, seed=4321)
nx.draw(G,
pos=pos,
node_size=500,
node_color='#f86e00',
edge_color='blue',
with_labels=True)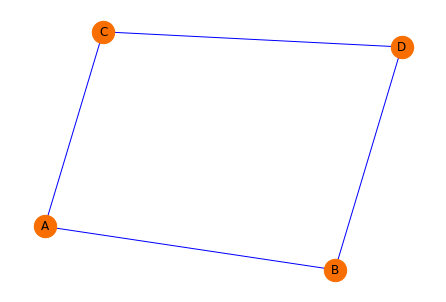
nx.shortest_path(G, 'A', 'D', weight='weight')['A', 'B', 'D']
นอกจาก add_edge() แล้ว เรายังสามารถนำข้อมูลแบบ Matrix มาสร้างกราฟได้ด้วยฟังก์ชันอื่น ๆ เช่น from_numpy_array()
matrixA = np.array([[0., 1., 1.],
[0., 0., 0.],
[0., 0., 0.]])
g1 = nx.from_numpy_array(matrixA)pos = nx.spiral_layout(g1)
nx.draw(g1,
pos=pos,
with_labels = True,
node_color="#f86e00")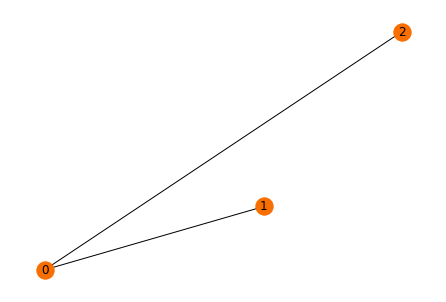
อย่างไรก็ตาม เมื่อใช้ from_numpy_array() มันจะสร้างกราฟแบบมีทิศทาง (Direct Graph) 2 ทิศทางบนทุกเส้นเชื่อมที่มี Weight เท่ากับ 1 ให้โดยอัตโนมัติ สังเกตได้จาก Array หรือ Matrix ที่เรา Dump ออกมาครับ
nx.to_numpy_array(g1)
- จาก Similarity Matrix ที่ได้ก่อนหน้า กราฟของเอกสารจะถูกสร้างด้วยฟังก์ชัน from_numpy_array()
sentence_similarity_graph = nx.from_numpy_array(sentence_similarity_martix)pos = nx.spring_layout(sentence_similarity_graph, seed=999)
nx.draw(sentence_similarity_graph,
pos=pos, node_size=500,
node_color='#f86e00',
edge_color='blue',
with_labels=True,
width=1)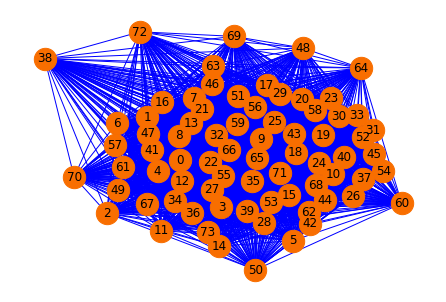
nx.get_edge_attributes(sentence_similarity_graph,'weight')
Edge Attribute หรือ Weight ของกราฟ ก็คือ ค่าจาก Sentence Similarity Matrix ครับ
คำนวณค่า PageRank และไฮไลท์ประโยค
PageRank เป็นอัลกอริทึมของ Google เพื่อจัดอันดับหน้าเว็บ (Web Page) ที่เป็นผลลัพธ์จาก Google Search Engine ซึ่งอัลกอริทึม PageRank ดั้งเดิมมีการคำนวณขนาดของ Web Page หรือเรียกว่าค่า PR จากโครงสร้างของ Link ในกราฟโดย Web Page ที่มีค่า PR มากที่สุดจะถูกนำมาจัดเรียงไว้ด้านบนเมื่อมีการค้นหาด้วย Google Search
จะขอยกตัวอย่างแนวคิดพื้นฐานของอัลกอริทึม PageRank ดังต่อไปนี้
- สร้างกราฟแบบมีทิศทางที่ประกอบด้วย Web Page ทั้งหมด 7 หน้า (A, B, C, D, E, F, G)
G = nx.DiGraph()
[G.add_node(k) for k in ['A', 'B', 'C', 'D', 'E', 'F', 'G']]
G.add_edges_from([('G','A'), ('A','G'),('B','A'),
('C','A'),('A','C'),('A','D'),
('E','A'),('F','A'),('D','B'),
('D','F')])pos = nx.spiral_layout(G)
nx.draw(G,
pos=pos,
with_labels = True,
node_color="#f86e00")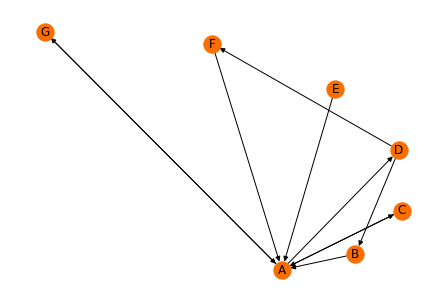
- ใช้ฟังก์ชัน pagerank() คำนวณค่า PR
pr1 = nx.pagerank(G)
pr1
ค่า PR ของทุก Node ในกราฟรวมกันจะเท่ากับ 1
- แสดงค่า PR เป็นเปอร์เซ็นต์
PR = [str(round(v * 100, 2)) + '%' for v in pr1.values()]
PR['40.81%', '7.97%', '13.7%', '13.7%', '2.14%', '7.97%', '13.7%']
- ดึงชื่อ Node จากกราฟ
name = [k for k in G._node.keys()]
name['A', 'B', 'C', 'D', 'E', 'F', 'G']
- แสดงค่า PR ของ Node ในกราฟเป็นเปอร์เซ็นต์
dict(zip(name, PR))
- ขยายค่า PR ของ Node ในกราฟ เพื่อให้ Plot ได้อย่างชัดเจน
size = [v * 6000 for v in pr1.values()]- Plot กราฟ โดยปรับขนาดของ Node ตามค่า PR ที่ถูกขยาย
pos = nx.spiral_layout(G)
nx.draw(G,
pos=pos,
with_labels = True,
node_color="#f86e00",
node_size=size)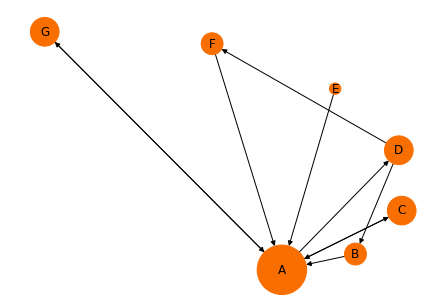
จากกราฟด้านบนพบว่า Web Page A ซึ่งมี Web Page อื่น ๆ Connect เข้าหามันมากที่สุด จะมีขนาดใหญ่ที่สุด (PR = 40.81%)
อย่างไรก็ตาม Web Page C, D, G (PR = 13.7%) จะมีขนาดใหญ่กว่า Web Page F (PR = 7.97%) ทั้ง ๆ ที่พวกมันมีจำนวน Link ขาเข้าเท่าๆ กัน ก็เพราะ Link ขาเข้า Web Page F นั้นมาจาก Web Page D (PR = 13.7%) ซึ่งมีขนาดเล็ก ขณะที่ Link ขาเข้า Web Page C, D, G มาจาก Web Page A (PR = 40.81%) ที่มีขนาดใหญ่ที่สุด
- Dump Matrix ออกจากกราฟ
nx.to_numpy_array(G)
- ทดลองสร้างกราฟแบบมีทิศทาง ที่มีทั้งหมด 4 Node
G = nx.DiGraph()
G.add_edge('B', 'A')
G.add_edge('C', 'A')
G.add_edge('D', 'A')
G.add_edge('B', 'C')
G.add_edge('D', 'B')
G.add_edge('D', 'C')pos = nx.spring_layout(G, seed=4321)
nx.draw(G,
pos=pos,
node_size=500,
node_color='#f86e00',
edge_color='blue',
with_labels=True)
ก่อนการคำนวณค่า PR อัลกอริทึม PageRank อาจจะกำหนดค่า PR เริ่มต้นของแต่ละ Node เท่ากับ 0.25 (1 หารด้วยจำนวน Node ในกราฟ)
PR(A) = 0.25 PR(B) = 0.25 PR(C) = 0.25 PR(D) = 0.25
สำหรับทุก Web Page q ที่ Connect มายัง Web Page A
PR(A) = (1-d) + d*(PR(B)/On(B) + PR(C)/On(C) + PR(D)/On(D))
โดย d หรือ damping factor = 0.85 และ
On(q) เท่ากับจำนวน Link ขาออก (Outgoing Links) ของ Page q
ดังนั้น PR(A) = 0.15 + 0.85(0.25/2 + 0.25/1 + 0.25/3) = 0.5395833333อัลกอริทึม PageRank จะคำนวณค่า PR ของ Web Page ต่าง ๆ หลายรอบ (max_iter=100) ก่อนจะได้ค่าที่นำไปใช้งาน
PR = nx.pagerank(G)
PR
nx.to_numpy_array(G)
จะเห็นว่าเมื่อไม่มีการกำหนดค่า Weight บน Edge ของกราฟ NetworkX จะกำหนด Weight เท่ากับ 1 เป็นค่า Default
แต่ในการไฮไลท์ใจความสำคัญในเอกสาร เราจะมีการกำหนดค่า Weight บน Edge ของกราฟ เป็นตัวเลขแบบทศนิยม (Sentence Similarity)
- ทดลองสร้างกราฟแบบมีทิศทาง ที่มีทั้งหมด 3 Node
D=nx.DiGraph()
D.add_edge('A', 'B')
D.add_edge('A', 'C')nx.draw(D,
pos=pos,
node_size=500,
node_color='#f86e00',
edge_color='blue',
with_labels=True)
nx.to_numpy_array(D)
Weight บน Edge ของกราฟ จะเท่ากับ 1
nx.pagerank(D){'A': 0.25974050510584634, 'B': 0.37012974744707666, 'C': 0.37012974744707666}
เนื่องจาก Web Page B และ C มีจำนวน Link ขาออกเท่ากับ 0 รวมทั้งมีค่า Weight บน Link จาก A ไป B และจาก A ไป C เท่ากับ 1 เท่ากัน จึงมีค่า PR เท่ากัน
- กำหนดค่า Weight บน Link จาก A ไป B และจาก A ไป C เท่ากับ 0.5
D.add_weighted_edges_from([('A','B',0.5),('A','C',0.5)])
nx.to_numpy_array(D)
nx.pagerank(D){'A': 0.25974050510584634, 'B': 0.37012974744707666, 'C': 0.37012974744707666}
แม้ว่าจะมีการเปลี่ยนค่า Weight บน Link จาก A ไป B และจาก A ไป C เท่ากับ 0.5 แต่เนื่องจากค่า Weight บน Link ทั้ง 2 ยังคงเท่ากันจึงทำให้มีค่า PR เท่าเดิมครับ
- กำหนดค่า Weight บน Link จาก A ไป C เท่ากับ 1
D['A']['C']['weight']=1
nx.to_numpy_array(D)
nx.pagerank(D){'A': 0.25974050510584634, 'B': 0.3333333333333332, 'C': 0.40692616156082007}
แต่เมื่อมีการเปลี่ยนค่า Weight บน Link จาก A ไป C เท่ากับ 1 ซึ่งมากกว่าค่า Weight บน Link จาก A ไป B ค่า PR ที่ Web Page C จึงมากกว่าค่า PR ที่ Web Page B
- ใช้ฟังก์ชัน pagerank() คำนวณค่า PR ของประโยคในเอกสารจาก Sentence Similarity Graph
pos = nx.spring_layout(sentence_similarity_graph, seed=999)
scores = nx.pagerank(sentence_similarity_graph)
scores
- ขยายค่า PR ของ Node ในกราฟ เพื่อให้ Plot ได้อย่างชัดเจน แล้ว Plot กราฟ
size = [v * 20000 for v in scores.values()]
nx.draw(sentence_similarity_graph,
pos=pos,
node_color='#f86e00',
edge_color='blue',
with_labels=True,
width=1,
node_size=size)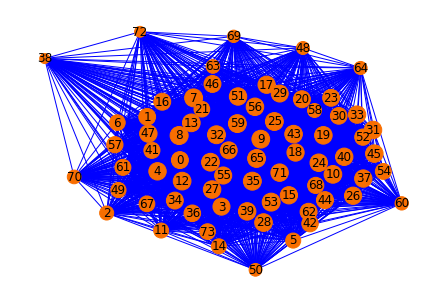
- จับคู่ค่า PR และประโยคในเอกสาร แล้วเรียงลำดับประโยคจากค่า PR มากไปน้อย
ranked_sentence = sorted(((scores[i],s) for i, s in enumerate(sentences)), reverse=True)
ranked_sentence
- แสดงค่า PR ที่มากที่สุด
ranked_sentence[0][0]0.016216306503214054
- แสดงประโยคในเอกสารที่มีค่า PR มากที่สุด
ranked_sentence[0][1]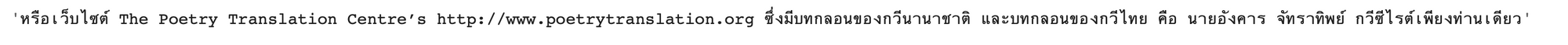
- หาจำนวนประโยค 20% ของเอกสารที่ต้องการไฮไลท์
ซึ่งในการทดลองนี้ เราตั้งสมมติฐานว่าใจความสำคัญของเอกสารน่าจะมีสัดส่วน 20% ของเนื้อหาทั้งหมด
top_n = round(sentence_size*0.2)
top_n15
- รวบรวมประโยค 20% ของเอกสารที่มีค่า PR มากที่สุดเพื่อนำมา Print
sum_text = ''
for i in range(top_n):
sum_text = sum_text + '\n' + ranked_sentence[i][1]- รวบรวมประโยค 20% ของเอกสารที่มีค่า PR มากที่สุดเพื่อนำไปไฮไลท์ และวัดประสิทธิภาพ
sum_list = []
for i in range(top_n):
sum_list.append(ranked_sentence[i][1])- รวบรวมประโยคทั้งเอกสารเพื่อนำมา Print
original_text = ''
for st in sentences:
original_text = original_text + '\n' + st- แสดงประโยคที่จะไฮไลท์
print('\nSummarize Text: \n', sum_text)
- แสดงประโยคทั้งเอกสาร
print('\nOriginal Text: \n', original_text)
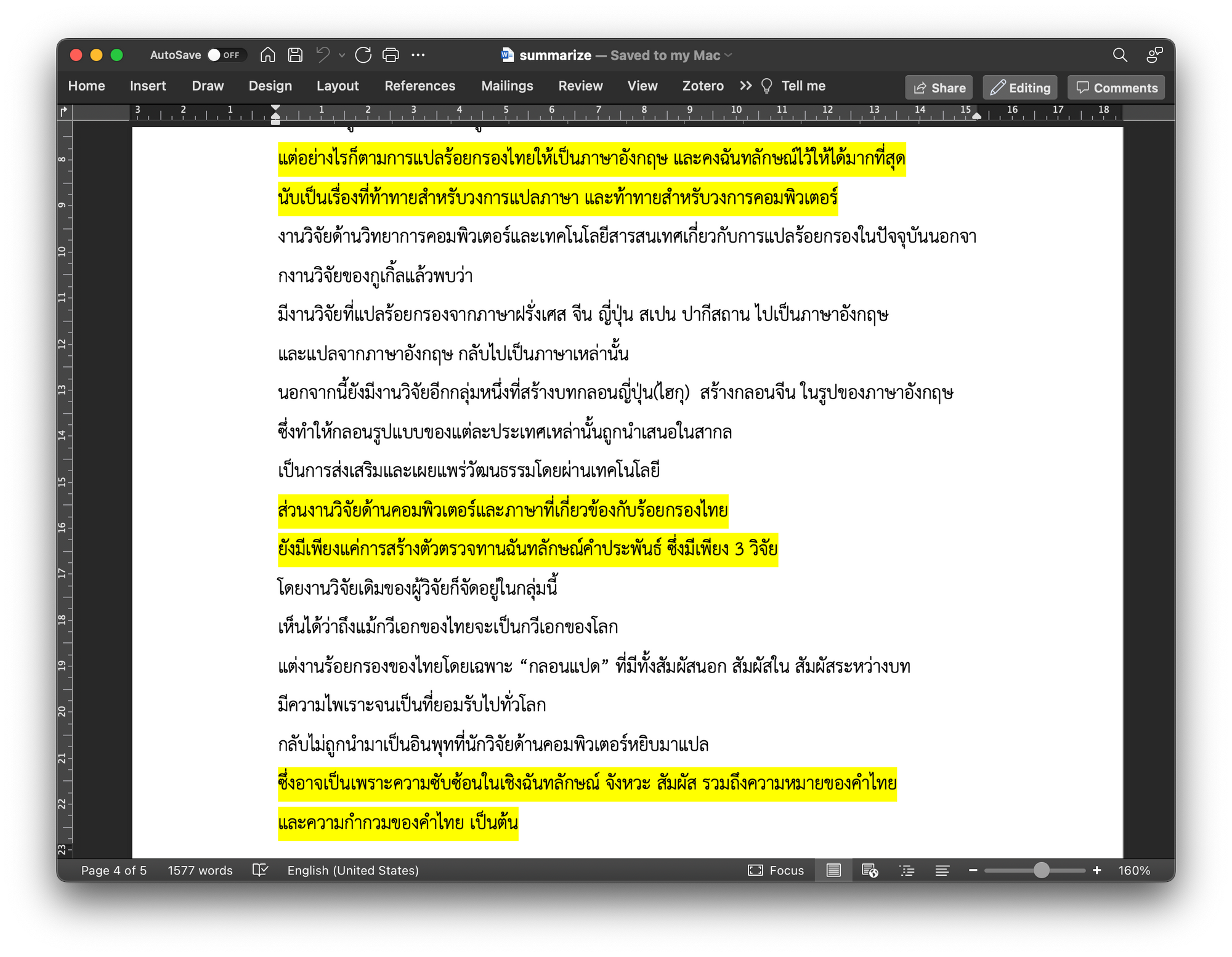
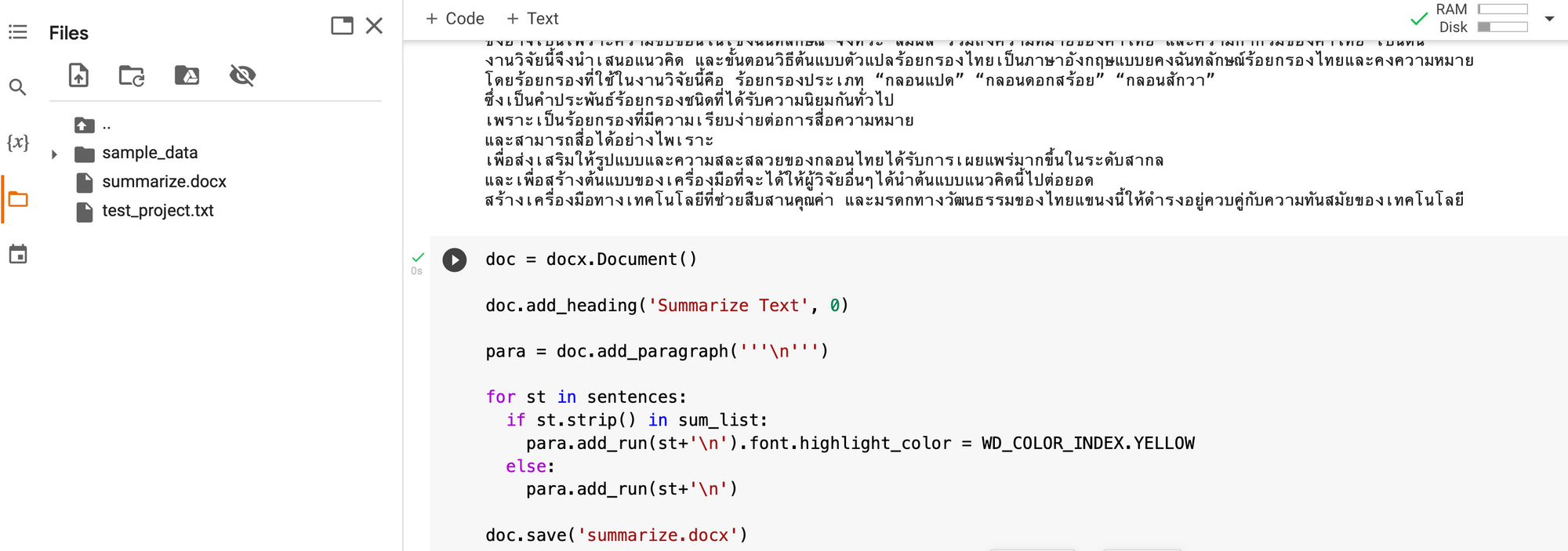
- ไฮไลท์ประโยคในเอกสารและ Save
doc = docx.Document()
doc.add_heading('Summarize Text', 0)
para = doc.add_paragraph('''\n''')
for st in sentences:
if st.strip() in sum_list:
para.add_run(st+'\n').font.highlight_color = WD_COLOR_INDEX.YELLOW
else:
para.add_run(st+'\n')
doc.save('summarize.docx')จะได้ไฟล์ summarize.docx ให้ Download มาเปิดดูด้วย Microsoft Word
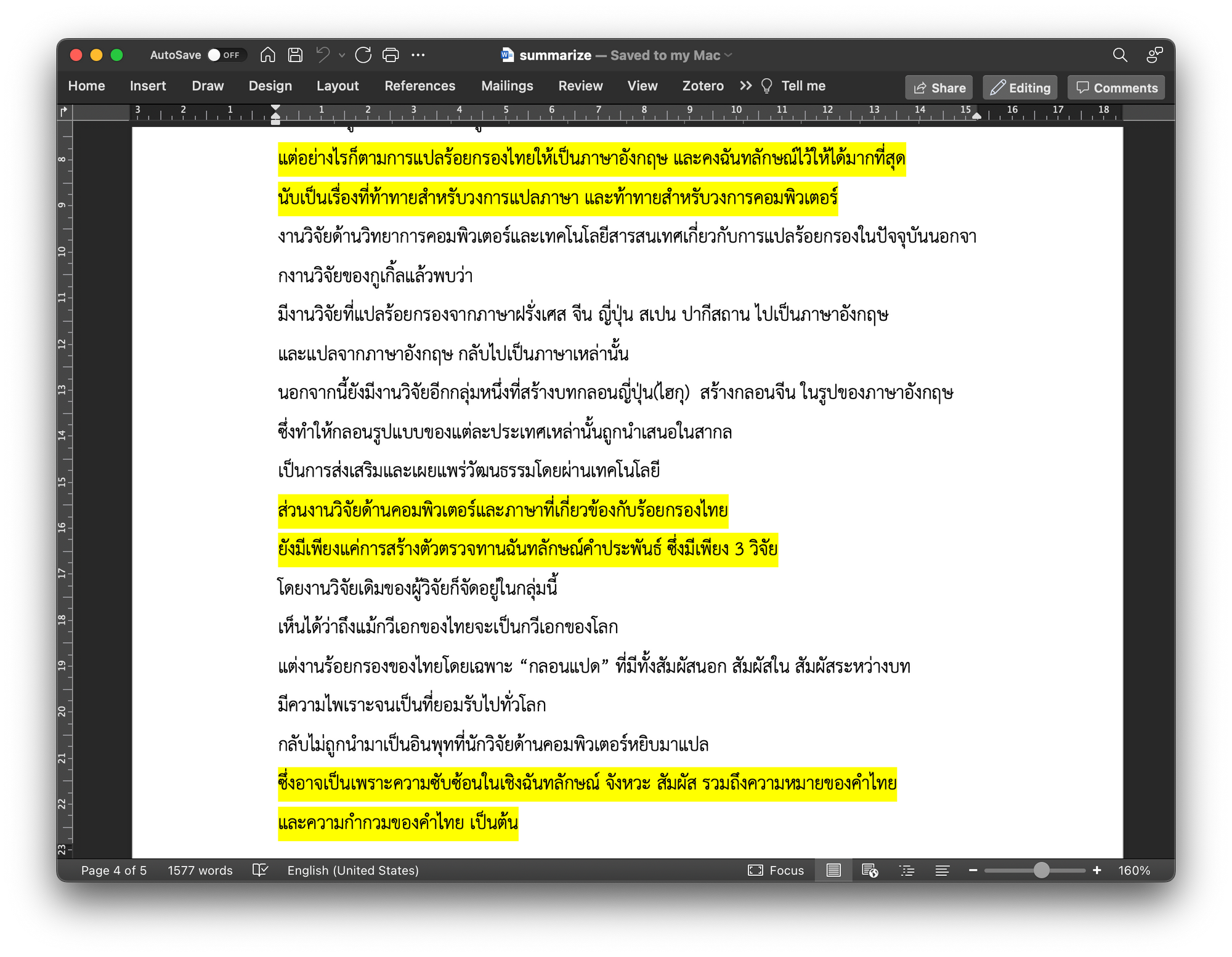
Rouge คือ Metric ตัวหนึ่งที่ใช้ในการวัดประสิทธิภาพการทำ Text Summarization ของ Model เทียบการทำ Text Summarization ด้วยคน โดยการวัดจะนับจำนวนหน่วยที่ทับซ้อนกันแบบ N-gram (Rouge1, Rouge2) และแบบ Longest Common Subsequence (RougeL) ซึ่งค่า Rouge สูง หมายถึง Model มีประสิทธิภาพที่ดี (ค่ามากที่สุดของ Rouge จะเท่ากับ 1.0)
- นิยามฟังก์ชัน evaluate_summary()
def evaluate_summary(y_test, predicted):
rouge_score = rouge.Rouge()
scores = rouge_score.get_scores(y_test, predicted, avg=True)
score_1 = round(scores['rouge-1']['f'], 2)
score_2 = round(scores['rouge-2']['f'], 2)
score_L = round(scores['rouge-l']['f'], 2)
print('Rouge1:', score_1)
print('Rouge2:', score_2)
print('RougeL:', score_L)
print('Avg Rouge:', round(np.mean([score_1, score_2, score_L]), 2))- Dowload ผลเฉลยของการทำ Text Summarization ด้วยคนจาก Text Summarization Dataset
- อ่านไฟล์ แบ่งประโยคโดยใช้ฟังก์ชัน splitlines() เพื่อเก็บลงใน List แล้ว Remove Space Character ที่ตอนต้นและท้ายประโยค
file_name = 'human_summarie.txt'
with open(file_name, 'r') as file:
human_summarie = file.read().splitlines()
human_summarie = [s.strip() for s in human_summarie]
len(human_summarie)16
- ตัดคำโดยใช้ตัวตัดคำแบบ Longest matching จาก Library PyThaiNLP
def tokenizer(st_list):
words = []
for s in st_list:
w = word_tokenize(s)
w = [temp for temp in w if temp != ' ']
if w != []:
words.append(' '.join(w).lower())
return wordshuman_summarie_word = tokenizer(human_summarie)
sum_list_word = tokenizer(sum_list)
test = ' '.join(human_summarie_word)
predicted = ' '.join(sum_list_word)test
predicted
- เรียกใช้ฟังก์ชัน evaluate_summary()
evaluate_summary(test, predicted)
ในการทำ Text Summarization แบบ Extraction-based เพื่อให้ได้ใจความสำคัญของบทความภาษาไทย เราสร้างกราฟของประโยคจากทั้งเอกสาร ที่มีการแทนค่า Weight บนเส้นเชื่อมระหว่างประโยคด้วยค่า Sentence Similarity ที่คำนวณมาจาก Sentence Vector ขนาด 768 Dimension จาก Output ของ Wangchanberta Model แล้วจึงหาค่า PageRank (PR) จากกราฟ ด้วยฟังก์ชันของ NetworkX Library โดยเราเลือกประโยคที่มีค่า PR มากที่สุด จำนวน 20% ของประโยคทั้งหมดเป็นตัวแทนของเอกสารต้นฉบับ และวัดประสิทธิภาพ Model ด้วย Rouge อย่างไรก็ตามการตัดประโยคในเอกสารภาษาไทยยังคงเป็นเรื่องท้าทาย ผู้เขียนจึงตัดประโยคด้วยมือเพื่อใช้เป็นตัวอย่างในการทำ Text Summarization ก่อน
หมายเหตุ บางส่วนของตัวอย่างในการทดลองของบทความนี้ดัดแปลงมากจาก https://towardsdatascience.com/understand-text-summarization-and-create-your-own-summarizer-in-python-b26a9f09fc70