Quickly Text Preprocessing for Beginners using Pandas, Regex and SQLite

บทความโดย ผศ.ดร.ณัฐโชติ พรหมฤทธิ์ และ อ.ดร.สัจจาภรณ์ ไวจรรยา
ภาควิชาคอมพิวเตอร์
คณะวิทยาศาสตร์
มหาวิทยาลัยศิลปากร
Text Preprocessing เป็นกระบวนการทั้งแบบอัตโนมัติหรือกึ่งอัตโนมัติในการเตรียมข้อความให้อยู่ในรูปแบบที่สามารถนำไปวิเคราะห์ ออก Report หรือทำนายได้ด้วย Model
ซึ่งข้อมูลประเภทข้อความ (Text) อาจจะปรากฎ Noise ในหลากหลายรูปแบบ ที่ต้องขจัดออก เช่น เครื่องหมายวรรคตอน การสะกดคำผิด ข้อความที่มีความหมายเดียวกัน แต่เขียนด้วย Style ที่หลากหลาย ฯลฯ นอกจากนี้ในการทำ Text Preprocessing อาจต้องมีการสกัด Information จากข้อความเพื่อจะนำไปใช้งาน
บทความนี้เราจะได้เห็นตัวอย่างการทำ Text Preprocessing ด้วยเครื่องมืออย่างเช่น Pandas, Regular Expression (Regex) และ SQL เพื่อขจัด Noise (Noise Removal) และสกัด Information (Information Extraction) จากข้อความใน AUCC Award 2021 Dataset รวมทั้งการ Query ข้อมูลจาก SQLite เพื่อออก Report ครับ
Understanding Problem Statement
AUCC (ASEAN Undergraduate Conference in Computing) เป็นงานประชุมวิชาการระดับปริญญาตรีด้านคอมพิวเตอร์ภูมิภาคอาเซียน ซึ่งมีการผลัดเปลี่ยนหมุนเวียนมหาวิทยาลัยต่าง ๆ กันเป็นเจ้าภาพ โดยจนถึงปัจจุบัน (2021) มีการจัดงานมาแล้วเป็นปีที่ 9
ในแต่ละปี นักศึกษาของมหาวิทยาลัยในเครือข่ายจะส่งผลงานของตนเองลงใน Track ต่าง ๆ 10 Track ได้แก่
- Business Intelligence (BI)
- Computer Education (CE)
- Computational Intelligence (CI)
- Computer System and Computer Network (CSN)
- Information Technology (IT)
- Knowledge and Data Management (KDM)
- Multimedia Computer Graphics and Games (MCG)
- Software Engineering (SE)
- Internet of Things (IoT)
- Data Science and Analytics (DSA)
ซึ่งในวันสุดท้ายของการประชุม จะมีการคัดเลือกผลงานที่มีคะแนนการนำเสนอและคะแนนการเขียน Paper ที่ผ่านเกณฑ์ เพื่อจัดคุณภาพเป็น 4 ระดับ จากมากไปน้อย คือ
- Best Paper
- Excellent
- Very Good
- Good
สำหรับการเป็นเจ้าภาพ หน้าที่หนึ่งคือการออก Report ในมิติต่าง ๆ เพื่อรายงานให้มหาวิทยาลัยที่เข้าร่วมได้รับทราบ รวมทั้งเพื่อเป็นข้อมูลในการวางแผนการจัดงานประชุมในครั้งต่อ ๆ ไป
ต่อไปนี้เป็นจะคำถาม 11 ข้อ ที่เรา "สมมติ" ขึ้นมาว่าน่าจะเป็น Information ที่เจ้าภาพจะนำไปรายงานให้แก่มหาวิทยาลัยที่เข้าร่วม และเพื่อเป็นข้อมูลในการวางแผนการจัดงานประชุม
- จำนวน Paper ของแต่ละมหาวิทยาลัย รวมทุกวิทยาเขต
- Paper ที่ส่งเป็นของคณะ ภาควิชา สาขา อะไร
- แต่ละมหาวิทยาลัย มีคณะอะไรบ้างที่ส่งผลงาน และส่งจำนวนเท่าไหร่
- แต่ละมหาวิทยาลัยส่ง Paper ใน Track อะไรบ้าง จำนวนเท่าไหร่
- จำนวน Paper ของแต่ละ Track
- จำนวน Paper ภาษาไทย และจำนวน Paper ภาษาอังกฤษ
- จำนวน Paper ที่เกี่ยวข้องกับ Topic ต่าง ๆ
- จำนวนรางวัล แต่ละรางวัลที่มหาวิทยาลัยได้รับ
- จำนวนผู้แต่งในแต่ละ Paper
- รายชื่อผู้แต่งที่มีชื่อในผลงานมากที่สุด 10 อันดับ
- จำนวนผู้แต่งทั้งหมด
AUCC Award 2021 Dataset
จากคำถาม 11 ข้อข้างต้น เราสามารถสกัด และ Query ข้อมูลที่อ่านมาจากไฟล์ CSV (AUCC Award Dataset) ซึ่งผู้เขียนได้มีการ "Blind ชื่อผู้แต่ง" โดยการแทนที่ ชื่อ และนามสกุลจริง ด้วย ชื่อ และนามสกุล ของชาวต่างชาติซึ่งเป็นภาษาอังกฤษ ที่ Fake ขึ้นมา แต่ยังคง Format อื่น ๆ ไว้ตามข้อมูลต้นฉบับ
http://gitlab.cpsudevops.com/nuttachot/aucc_dataset.git
AUCC Award 2021 Dataset จะประกอบด้วยข้อมูลทั้งหมด 338 แถว โดยไม่รวม Header ซึ่งแต่ละแถวมีคอลัมน์ทั้งหมด 6 คอลัมน์ ได้แก่
- University
- Faculty
- Track
- Title
- Author
- Award
Libraries used to deal with problems
เพื่อจะขจัด Noise (Noise Removal) สกัด Information (Information Extraction) และ Query ข้อมูล เราจะใช้เครื่องมือต่างๆ ได้แก่ Pandas, Regular Expression และ SQL โดยจะต้องมีการติดตั้ง SQLAlchemy Version 1.4.4 และ Import Library ที่จำเป็น ดังนี้
pip install sqlalchemy==1.4.4import pandas as pd
import sqlite3
import numpy as np
from collections import Counter
import plotly.express as px
import plotly.graph_objects as goเราเลือกใช้ ipython-sql ในการ Query ข้อมูลจาก SQLite โดยใช้คำสั่ง SQL (Structured Query Language) บน Jupyter Notebook ด้วย Jupyter Magic Function (ขึ้นต้น Magic Function ด้วย % หรือ %% แล้วตามด้วยคำสั่ง SQL) ซึ่งจะต้องมีการติดตั้ง แล้วโหลด ipython-sql ด้วยคำสั่งดังนี้
- ติดตั้ง ipython-sql
pip install ipython-sql- Load ipython-sql
%load_ext sqlIntroduction to Pandas and SQLite
เราจะใช้ Function read_csv ของ Pandas ในการอ่านข้อมูลจากไฟล์
df = pd.read_csv('aucc_award_with_blind_authors.csv')
df.shape(338, 6)
โดย AUCC Award Dataset จะประกอบด้วยคอลัมน์ต่าง ๆ 6 คอลัมน์
df.columnsIndex(['university', 'faculty', 'Track', 'title', 'author', 'award'], dtype='object')
ซึ่งจะเห็นว่าคอลัมน์ต่าง ๆ จาก Dataset นั้นเป็นข้อความภาษาอังกฤษที่ขึ้นต้นด้วยตัวอักษรตัวเล็ก ยกเว้นคอลัมน์ Track ที่ขึ้นต้นด้วยตัวอักษรตัวใหญ่ ดังนั้นจะมีการเปลี่ยนชื่อคอลัมน์ให้มีรูปแบบเหมือน ๆ กันโดยใช้ df.rename
df.rename(columns={'Track':'track'}, inplace=True)
df.columnsโดยเราจะเห็นข้อมูลทั้ง 5 แถวแรก พร้อมชื่อคอลัมน์ที่มีการแก้ไข ดังนี้
df.head()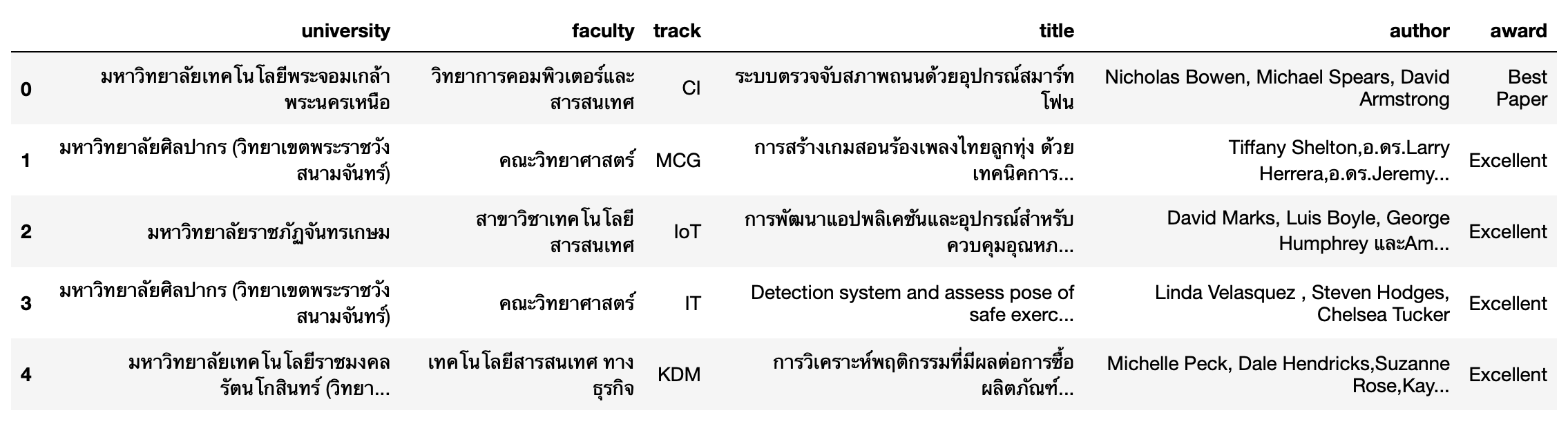
ในลำดับต่อไป เราจะนำข้อมูลแบบ DataFrame ไปเก็บลง SQLite เพื่อใช้ในการ Query และออก Report ซึ่งจะต้องมีการ Connect กับ SQLite เพื่อสร้างไฟล์ Database ใหม่ (aucc2021.db) แล้วบันทึกข้อมูลลงตาราง aucc_award_table
- Connect กับ SQLite
connect = sqlite3.connect('aucc2021.db')- บันทึกข้อมูลลงตาราง aucc_award_table ด้วย
df.to_sql
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)อย่างไรก็ตาม เพื่อจะ Query ข้อมูลด้วยคำสั่ง SQL แบบ Magic Function เราจะต้องเชื่อมต่อ SQLite อีกครั้ง ด้วยคำสั่ง %sql sqlite:/// แล้วจึงทดลอง Query ข้อมูลจากตาราง aucc_award_table
%sql sqlite:///aucc2021.db- ใช้ Magic Function โดยขึ้นต้นคำสั่งด้วย % เพื่อ Query ข้อมูลจากตาราง aucc_award_table
%sql select * from aucc_award_table limit 5* sqlite:///aucc2021.db
Done.

นอกจากนี้เรายังสามารถ Query ข้อมูลได้จาก Table ใน SQLite แล้วแปลงผลลัพธ์เป็นข้อมูลแบบ DataFrame ที่ประกอบด้วยแถวและคอลัมน์ เช่นเดียวกับตารางใน MS Excel
result = %sql select * from aucc_award_table* sqlite:///aucc2021.db
Done.
result.DataFrame().head()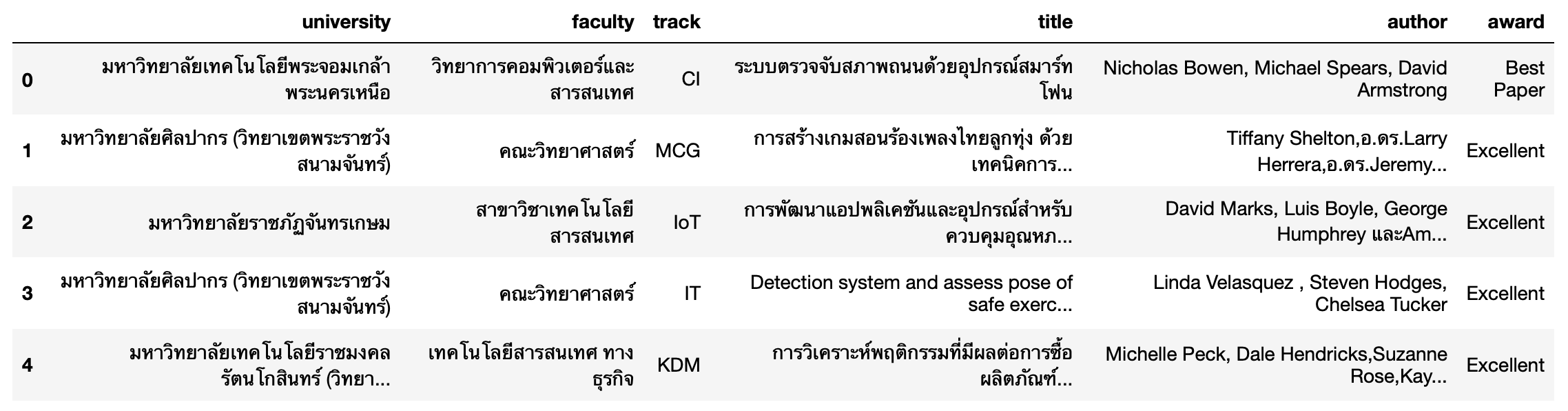
อีกทางเลือกหนึ่งในการใช้ Magic Function นอกจากการขึ้นต้นด้วย % เพื่อ Query ข้อมูลแล้ว เราสามารถขึ้นต้นด้วย %% ได้ด้วย ซึ่งจะทำให้สามารถเขียนคำสังที่แยกบรรทัดได้เพื่อให้เกิดความสวยงาม และ Code ดูมีระเบียบ อ่านง่าย
- ทดลอง Query ข้อมูลจากตาราง aucc_award_table แล้วดึงมาเก็บลงตัวแปร df อีกครั้งด้วย %%
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()pandas.DataFrame and pandas.Series
เพื่อให้สามารถใช้งาน Pandas ได้อย่างคล่องแคล่ว เราจะมาทำความเข้าใจโครงสร้างข้อมูลของมันให้ลึกซึ้งขึ้นครับ
โครงสร้างข้อมูลพื้นฐานของ Pandas มี 2 ชนิด คือ DataFrame และ Series ถ้าจะนิยามแบบง่ายๆ DataFrame ก็คือ Array แบบ 2 มิติ หรือ Matrix ที่มี Label ประกบในแต่ละแถวและคอลัมน์
เราจะเรียก Label ที่ประกบกับแต่ละคอลัมน์ ว่า Column Name และ Label ที่ประกบอยู่กับแต่ละแถว ว่า Index
โดย 1 แถว หรือ 1 คอลัมน์ ของ DataFrame ก็คือโครงสร้างข้อมูลแบบ Series ซึ่งถ้าจะนิยามอย่างง่าย Series ก็คือ Array 1 มิติ ที่มี Label ประกบเช่นกัน
การสร้าง DataFrame ขึ้นมาใหม่โดยไม่ต้องอ่านข้อมูลจากไฟล์ CSV มีหลายรูปแบบ เช่นโดยการสร้าง DataFrame จาก List, Array หรือ Dict
- ตัวอย่างการสร้าง DataFrame จาก List
data_list = [['ณัฐโชติ', 10], ['สัจจาภรณ์', 15], ['จรรยา', 14]]df = pd.DataFrame(data_list, columns = ['Name', 'Age'])
df
- ตัวอย่างการสร้าง DataFrame จาก Array
data_array = np.array([['ณัฐโชติ', 10], ['สัจจาภรณ์', 15], ['จรรยา', 14]])df = pd.DataFrame(data_array, columns = ['Name', 'Age'])
df
- ตัวอย่างการสร้าง DataFrame จาก Dict
data_dict = {'Name':['ณัฐโชติ', 'สัจจาภรณ์', 'จรรยา'],
'Age':[10, 15, 14]}df = pd.DataFrame(data_dict)
df
หรือจะสร้าง DataFrame จาก Tuple ก็ได้ครับ
name = ['ณัฐโชติ', 'สัจจาภรณ์', 'จรรยา']
age = [10, 15, 14]list_of_tuples = list(zip(name, age))
list_of_tuples[('ณัฐโชติ', 10), ('สัจจาภรณ์', 15), ('จรรยา', 14)]
df = pd.DataFrame(list_of_tuples, columns = ['Name', 'Age'])
df
ซึ่งเมื่อไม่ได้มีการกำหนด Index ตอนสร้าง DataFrame มาก่อน Index ชั่วคราวแบบ Integer จะถูกสร้างขึ้นมาโดยอัตโนมัติ
df.indexRangeIndex(start=0, stop=4, step=1)
ในการสร้าง Index ให้กับ DataFrame เราสามารถกำหนด Label แต่ละตัวเป็นข้อมูลแบบ List ดังต่อไปนี้
data = {'Name':['ณัฐโชติ', 'สัจจาภรณ์', 'จรรยา'],
'Age':[10, 15, 14]}df = pd.DataFrame(data, index =['index1',
'index2',
'index3'])
df
df.indexIndex(['index1', 'index2', 'index3'], dtype='object')
ขณะที่ข้อมูลแบบ Series ก็สามารถถูกสร้างขึ้นมาจาก List, Array และ Dict ได้เช่นกัน
- ตัวอย่างการสร้าง Series ด้วย List
data_list = ['a', 'b', 'c', 'd', 'e', 'f']ser = pd.Series(data_list)
ser
- ตัวอย่างการสร้าง Series ด้วย Array
data_array = np.array(['a', 'b', 'c', 'd', 'e', 'f'])ser = pd.Series(data_array, index =[10, 20, 30, 40, 50, 60])
ser
ser.indexInt64Index([10, 20, 30, 40, 50, 60], dtype='int64')
- ตัวอย่างการสร้าง Series ด้วย Dict
data_dict = {10 : 'a',
20 : 'b',
30 : 'c',
40 : 'd',
50 : 'e',
60 : 'f'}ser = pd.Series(data_dict)
ser
ser.indexInt64Index([10, 20, 30, 40, 50, 60], dtype='int64')
เราสามารถสลัด Label ที่ประกบอยู่กับ Series โดยการแปลงข้อมูลไปเป็น List ได้ด้วย list() Constructor ครับ
list(ser)['a', 'b', 'c', 'd', 'e', 'f']
iloc and loc
มีวิธีในการอ้างถึงแถว และคอมลัมน์ของ DataFrame 2 แบบหลัก ๆ คือ การใช้ iloc และ loc
วิธีแบบ iloc จะมีการอ้างถึงแถว และคอลัมน์แบบ Array (เร่ิมต้นด้วย 0) ร่วมกับการอ้างถึงด้วย Column Name

- การอ้างถึงแถวที่ 1 ทั้งแถว ดังคำสั่งด้านล่าง จะได้ข้อมูลกลับมาเป็น Series
df.iloc[1]
- แปลงข้อมมูลแบบ Series เป็น List
list(df.iloc[1])['สัจจาภรณ์', 15]
- การอ้างถึงแถวที่ 1 คอลัมน์ที่ 0 จะได้ข้อมูลเป็น Scalar
df.iloc[1,0]'สัจจาภรณ์'
- การอ้างถึงข้อมูล ทุกแถว ในคอลัมน์ที่ 0 จะได้ข้อมูลกลับมาเป็น Series
df.iloc[:,0]
- ตัวอย่างการอ้างถึงข้อมูลแถวที่ 0 จนถึงแถวที่ 1 ในคอลัมน์ที่ 0 ซึ่งจะได้ข้อมูลกลับมาเป็น Series
df.iloc[:2,0]
- ตัวอย่างการอ้างถึงแถวที่ 0 ถึงแถวที่ 1 และ Column Name เท่ากับ Age
df.iloc[0:2]['Age']
วิธีแบบ loc จะมีการอ้างถึงแถว และคอลัมน์ โดยใช้ Index และ Column Name
- การอ้างถึงแถวที่ 0 ถึงแถวที่มี Index เป็น index2 และ Column Name เท่ากับ Age
df.loc[:'index2','Age']
- การอ้างถึงแถวที่ 0 ถึงแถวที่มี Index เป็น index2 และ Column Name ตั้งแต่ คอลัมน์แรก จนถึงคอลัมน์ Age (จะได้ข้อมูลกลับเป็น DataFrame)
df.loc[:'index2', :'Age']
- การอ้างถึงแถวที่มี Index เป็น index2 และ Column Name เป็น Name
df.loc['index2', :'Name']
- การอ้างถึง ทุกแถว ในคอลัมน์ชื่อ Name
df.loc[:,'Name']
นอกจากนี้เรายังสามารถอ้างถึงคอลัมน์ต่าง ๆ ได้โดยไม่ต้องใช้ iloc หรือ loc อีกด้วย เช่น
df['Name']
Techniques for Text Preprocessing with Pandas
การเข้าถึงข้อมูลใน DataFrame เพื่อทำ Text Preprocessing สามารถทำได้หลายวิธี เช่น ด้วยการใช้ Apply Function หรือใช้ String Function ที่ Built-in มากับ Pandas เอง
- ตัวอย่างการใช้ Apply Function ร่วมกับ Lambda Function ในการหาความยาวของคำแล้วนำไปเก็บใน Column ใหม่
df = pd.DataFrame({'university':['มหาวิทยาลัยศิลปากร (วิทยาเขตพระราชวังสนามจันทร์)','มหาวิทยาลัยเกษตรศาสตร์ (วิทยาเขตกำแพงแสน)', 'มหาวิทยาลัยเทคโนโลยีราชมงคลรัตนโกสินทร์ (พื้นที่ศาลายา)']})
df
df['length'] = df['university'].apply(lambda x: len(x))
df
- ตัวอย่างการใช้ String Function ที่ Built-in มากับ Pandas เพื่อหาความยาวของคำ
df['length'] = df['university'].str.len()
df
ซึ่งเราสามารถ Filter ข้อมูลเฉพาะแถวที่ชื่อมหาวิทยาลัย มีความยาวน้อยกว่าหรือเท่ากับ 50 ตัวอักษร ด้วยการใช้ Boolean Mask
df['length'] <= 50
(df['length'] <= 50).shape(3,)
- การ Filter เฉพาะแถวที่ชื่อมหาวิทยาลัยมีความยาวน้อยกว่าหรือเท่ากับ 50 ตัวอักษร ด้วย Boolean Mask
df[(df['length'] <= 50)]
จะเห็นว่าการใช้ String Function ที่ Built-in จะทำให้คำสั่งสั้นกว่า รวมทั้งอ่านเข้าใจง่ายกว่าการใช้ Apply Function ครับ ดังนั้นในบทความนี้เราจะทำ Text Preprocessing โดยใช้ String Function ที่ Built-in มากับ Pandas เป็นหลัก
Noise Removal and Information Extraction
ก่อนที่จะมีการตอบคำถาม 11 ข้อ ข้อมูลดิบใน Dataset จะต้องมีการขจัด Noise (Noise Removal) และสกัด Information (Information Extraction) จาก Regular Expression Format ดังตัวอย่างต่อไปนี้
. หมายถึง ตัวอักษรอะไรก็ได้
? หมายถึง 0 ถึง 1 ตัวอักษร
* หมายถึง 0 ถึง ∞ ตัวอักษร
+ หมายถึง 1 ถึง ∞ ตัวอักษร
{min,max} หมายถึง min ถึง max ตัวอักษร
[ ] หมายถึง กลุ่มของตัวอักษรที่ต้องการ สามารถใช้ - ช่วยในกรณีที่อักษรที่ต้องการเป็น Range ได้ เช่น [ก-๙]
[^ ] หมายถึง ไม่เอาตัวอักษรในนี้
^ หมายถึง ต้องขึ้นประโยคด้วยคำที่กำหนด เช่น ^มหาวิทยาลัย.*
$ หมายถึง ต้องจบประโยคด้วยคำที่กำหนด
( ) หมายถึง การจัดกลุ่ม Token
| หมายถึง หรือ เช่น a|b
\w หมายถึง [A-Za-z0-9_]
\W หมายถึง [^A-Za-z0-9_]
\a หมายถึง [A-Za-z]
\s หมายถึง [ \t]
_s หมายถึง [ \t\r\n\v\f]
\S หมายถึง [^ \t\r\n\v\f]
\d หมายถึง [0-9]
\D หมายถึง [^0-9]
\l หมายถึง [a-z]
\u หมายถึง [A-Z]
\x หมายถึง [A-Fa-f0-9]
\ หมายถึง Escape Sequence เช่น \( หมายถึง อักขระวงเล็บเปิด ไม่ใช่สัญลักณ์การจัดกลุ่ม Tokenการแยกวิทยาเขต ออกจากชื่อมหาวิทยาลัย
เพื่อจะตอบคำถามเกี่ยวกับ Paper ของแต่ละมหาวิทยาลัย รวมทุกวิทยาเขต เราจะต้องดึงชื่อวิทยาเขตออกมาจากชื่อมหาวิทยาลัย ด้วย str.extract และ str.replace ซึ่งเป็น String Function ที่ Built-in มากับ Pandas
ในการตอบคำถามแต่ละข้อ เราพยายามแบ่งการแก้ปัญหาออกเป็นงาน (Job) ในทำนองเดียวกับการทำ ETL (Extract, Transform และ Load) Pipeline เพื่อให้มั่นใจว่าจะมีการนำข้อมูลที่ Update แล้ว มา Transform แม้ว่าในหลาย Pipeline ของเราจะมีการ Extract และ Load จาก Data Source เดียวกันก็ตาม
*หมายเหต Extract ของ ETL มีความหมายต่างจาก Information Extraction
Example
test_df = pd.DataFrame({'university':['มหาวิทยาลัยศิลปากร (วิทยาเขตพระราชวังสนามจันทร์)','มหาวิทยาลัยเกษตรศาสตร์ (วิทยาเขตกำแพงแสน)', 'มหาวิทยาลัยเทคโนโลยีราชมงคลรัตนโกสินทร์ (พื้นที่ศาลายา)', 'มหาวิทยาลัยเกษตรศาสตร์ (วิทยาเขตเฉลิมพระเกียรติ จังหวัดสกลนคร)']})
test_df
test_df['campus']=test_df['university'].str.extract(r'(\(วิทยาเขต.*\)|\(พื้นที่.*\))')
test_df
Extract
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()Transform
df['campus']=df['university'].str.extract(r'(\(วิทยาเขต.*\)|\(พื้นที่.*\)|พื้นที่บพิตรพิมุข จักรวรรดิ)')
df.sample(5)
Load ลง Database
- Save ข้อมูลลง SQLite แล้วทดลอง Query เพื่อนับจำนวนมหาวิทยาลัยที่สามารถดึงวิทยาเขตออกมาได้
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)%%sql
select count(*)
from aucc_award_table
where campus is not Null* sqlite:///aucc2021.db
Done.

ลบชื่อวิทยาเขตออกจากชื่อมหาวิทยาลัย แล้วลบ Space ออกจากหน้าและหลังข้อความ รวมทั้งลบ () ออกจากวิทยาเขต
Example
S=pd.Series(['มหาวิทยาลัยศิลปากร (วิทยาเขตพระราชวังสนามจันทร์)','มหาวิทยาลัยเกษตรศาสตร์ (วิทยาเขตกำแพงแสน)', 'มหาวิทยาลัยเทคโนโลยีราชมงคลรัตนโกสินทร์ (พื้นที่ศาลายา)', 'มหาวิทยาลัยเกษตรศาสตร์ (วิทยาเขตเฉลิมพระเกียรติ จังหวัดสกลนคร)'])
S
S.replace(r'(\(.*\))', '', regex=True, inplace = True)
S
S[0], S[0].strip() ('มหาวิทยาลัยศิลปากร ', 'มหาวิทยาลัยศิลปากร')
Extract
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()Transform
df['university'] = df['university'].str.replace(r'(\(.*\)|พื้นที่บพิตรพิมุข จักรวรรดิ)', '', regex=True)
df.sample(5)
df['university'] = df['university'].str.strip()
df.sample(5)
df['campus'] = df['campus'].str.replace(r'([\(\)])', '', regex=True)
df.sample(5)
Load ลง Database
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)Problem Statement
จากการขจัด Noise และสกัด Information ในเบื้องต้น เราสามารถตอบคำถามว่าแต่ละมหาวิทยาลัยส่ง Paper เป็นจำนวนเท่าไหร่
จำนวน Paper ของแต่ละมหาวิทยาลัย รวมทุกวิทยาเขต
Report
%%sql
select university, count(*) as paper
from aucc_award_table
group by university
order by paper desc
limit 10* sqlite:///aucc2021.db
Done.

- สร้างไฟล์ CSV เพื่อรายงานจำนวน Paper ของแต่ละมหาวิทยาลัย
%%sql result <<
select university, count(*) as paper
from aucc_award_table
group by university
order by paper desc* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()
df.to_csv('university_paper.csv', encoding='utf8', index=False)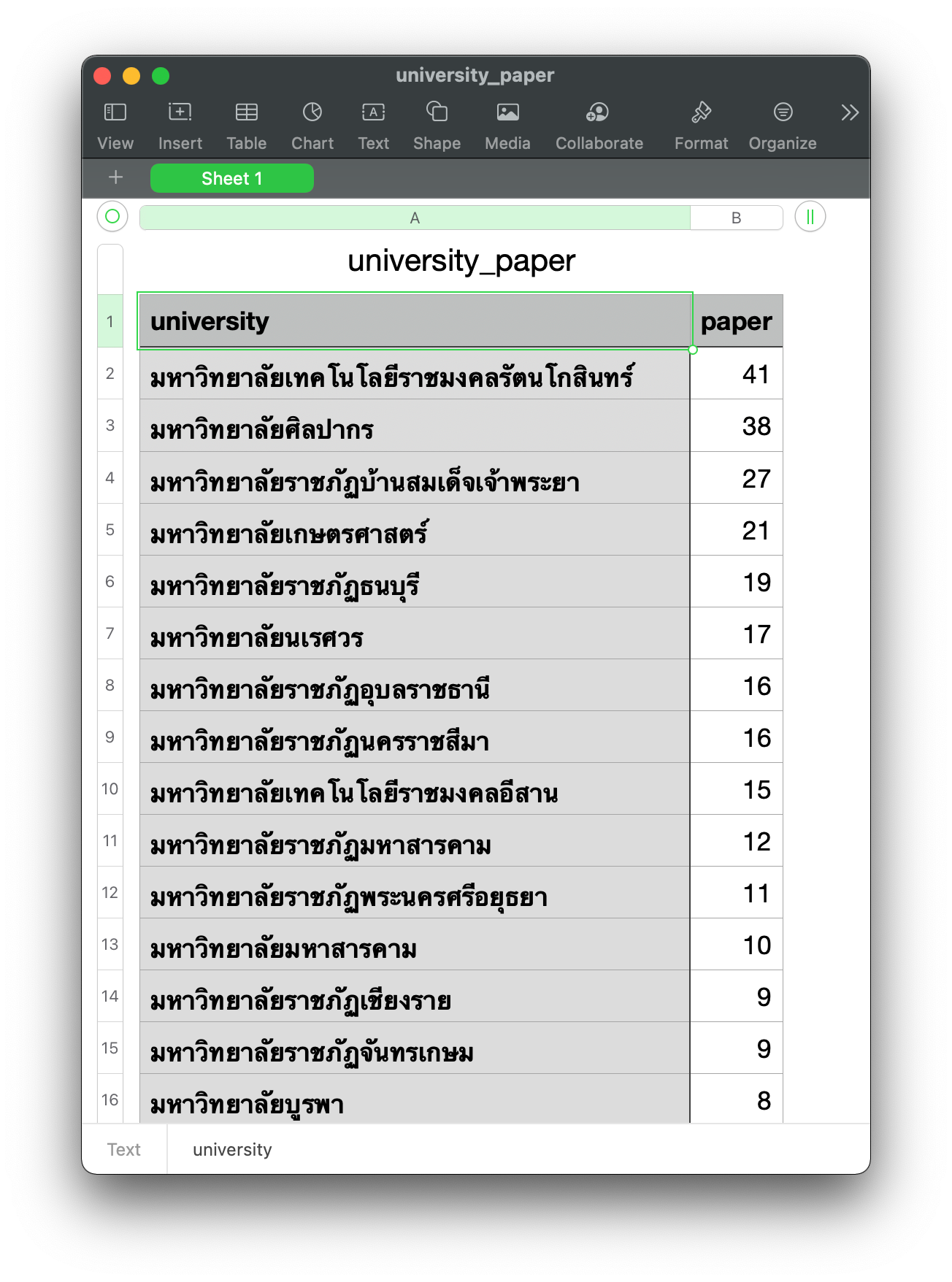
- Plot กราฟ จำนวน Paper ของแต่ละมหาวิทยาลัย โดยในการ Query ด้วย Magic Function จะสามารถใช้ ตัวแปร เป็นส่วนหนึ่งของคำสั่ง (:LIMIT) ได้ดังนี้
LIMIT = 10%%sql result <<
select university, count(*) as paper
from aucc_award_table
group by university
order by paper desc
limit :LIMITfig = px.bar(result.DataFrame(), x='university', y='paper', text='paper', title='AUCC University Paper', height=800)
fig.update_xaxes(tickangle=90)
fig.show()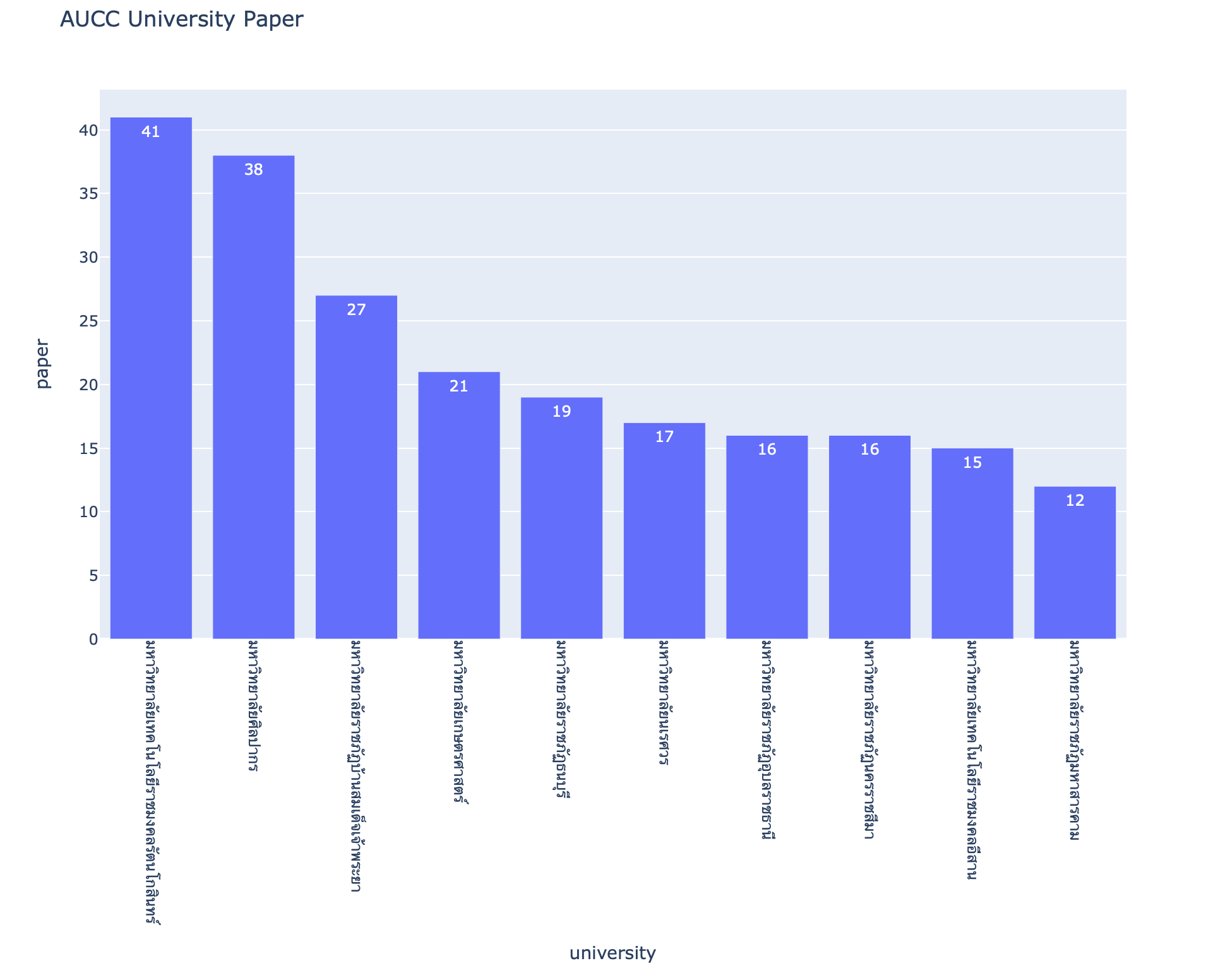
Paper ที่ส่งเป็นของคณะ ภาควิชา สาขา อะไร
เพื่อจะตอบคำถามว่าแต่ละมหาวิทยาลัยมีคณะ ภาควิชา และสาขา อะไรบ้างที่ส่งผลงาน เราจะต้องมีการขจัด Noise (Noise Removal) และสกัด Information (Information Extraction) ด้วยการแยกภาควิชา และสาขา ออกจากคณะ
Example
- ทดลองลบช่องว่างหลังคณะ ภาควิชา สาขา (ถ้ามี)
S=pd.Series(['ภาควิชา คอมพิวเตอร์','สาขา วิทยาการคอมพิวเตอร์', 'สาขาวิชา วิทยาการข้อมูล', 'คณะ บริหารธุรกิจ', 'สำนักวิชา คอมพิวเตอร์และเทคโนโลยีสารสนเทศ', 'หลักสูตร การจัดการเทคโนโลยีสารสนเทศ'])
S
S.replace(r'(ภาควิชา +)', 'ภาควิชา', regex=True, inplace = True)
S.replace(r'(สาขา +)', 'สาขา', regex=True, inplace = True)
S.replace(r'(สาขาวิชา +)', 'สาขาวิชา', regex=True, inplace = True)
S.replace(r'(คณะ +)', 'คณะ', regex=True, inplace = True)
S.replace(r'(สำนักวิชา +)', 'สำนักวิชา', regex=True, inplace = True)
S.replace(r'(หลักสูตร +)', 'หลักสูตร', regex=True, inplace = True)
S
- ทดลองดึงภาควิชาจากคณะไปเก็บใน Column department
test_df = pd.DataFrame({'faculty':['ภาควิชาวิทยาการคอมพิวเตอร์และสารสนเทศ', 'ภาควิชาคอมพิวเตอร์ คณะวิทยาศาสตร์ มหาวิทยาลัยศิลปากร', 'คณะวิทยาศาสตร์ ภาควิชาวิทยาการคอมพิวเตอร์และเทคโนโลยีสารสนเทศ']})
test_df
test_df['department'] = test_df['faculty'].str.extract(r'(ภาควิชา\S+ *)')
test_df
Extract
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()Transform
- ลบช่องว่างหลังคณะ ภาควิชา สาขา คณะ สำนักวิชา หลักสูตร และวิทยาลัย
df['faculty'] = df['faculty'].str.replace(r'(ภาควิชา +)', 'ภาควิชา', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(สาขา +)', 'สาขา', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(สาขาวิชา +)', 'สาขาวิชา', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(คณะ +)', 'คณะ', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(สำนักวิชา +)', 'สำนักวิชา', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(หลักสูตร +)', 'หลักสูตร', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(วิทยาลัย +)', 'วิทยาลัย', regex=True)df.sample(5)
- ดึงภาควิชาจาก Faculty ไปยัง Department
df['department'] = df['faculty'].str.extract(r'(ภาควิชา\S+ *)')df['department'] = df['department'].str.strip()
df.sample(5)
- ลบภาควิชาจาก Faculty
df['faculty'] = df['faculty'].str.replace(r'(ภาควิชา\S+ *)', '', regex=True)
df.sample(5)
Load ลง Database
- Save ข้อมูลลง SQLite แล้วทดลอง Query ข้อมูล
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)%%sql
select * from aucc_award_table
where department is not Null
limit 5* sqlite:///aucc2021.db
Done.

Example
- ทดลองดึง คณะ สำนัก Faculty และวิทยาลัย ออกจาก faculty ไปใส่ใน new_faculty แล้วลบ คณะ สำนัก Faculty และวิทยาลัย ออกจาก faculty เดิม ซึ่งจะทำให้เหลือเฉพาะสาขาวิชาใน faculty เดิม
test_df = pd.DataFrame({'faculty':['คณะวิทยาศาสตร์และเทคโนโลยี สาขาวิทยาการคอมพิวเตอร์', 'สํานักวิชาคอมพิวเตอร์และเทคโนโลยีสารสนเทศ', 'วิทยาศาสตร์', 'วิทยาศาสตร์และเทคโนโลยี','บริหารศาสตร์', 'วิทยาลัยแม่ฮ่องสอน', 'Faculty of Informatics']})
test_df
test_df['new_faculty'] = test_df['faculty'].str.extract(r'(คณะ\S+ *|สํานัก\S+ *|วิทยาลัย\S+ *|วิทยาศาสตร์และเทคโนโลยี *|วิทยาศาสตร์ *|บริหารศาสตร์ *|Faculty +of +\S+ *)')
test_df['new_faculty'] = test_df['new_faculty'].str.strip()
test_df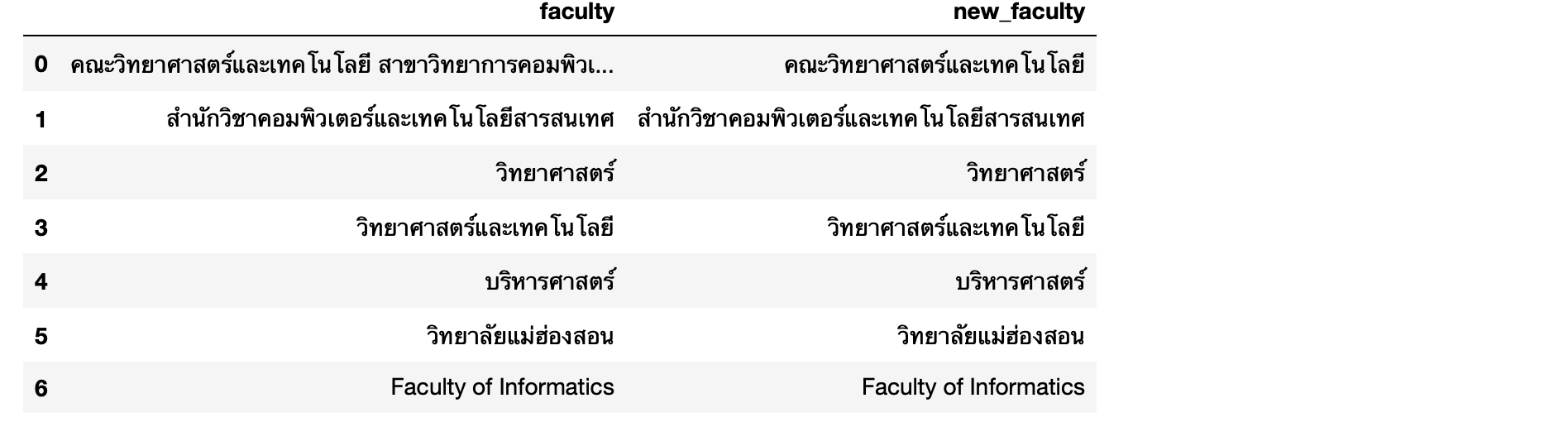
test_df['faculty'] = test_df['faculty'].str.replace(r'(คณะ\S+ *|สํานัก\S+ *|วิทยาลัย\S+ *|วิทยาศาสตร์และเทคโนโลยี *|วิทยาศาสตร์ *|บริหารศาสตร์ *|Faculty +of +\S+ *)', '', regex=True)
test_df['faculty'] = test_df['faculty'].str.strip()
test_df
Extract
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()Transform
- ดึงคณะ สำนัก Faculty และวิทยาลัย ออกจาก faculty ไปใส่ใน new_faculty
df['new_faculty'] = df['faculty'].str.extract(r'(คณะ\S+ *|สํานัก\S+ *|วิทยาลัย\S+ *|วิทยาศาสตร์และเทคโนโลยี *|วิทยาศาสตร์ *|บริหารศาสตร์ *|Faculty +of +\S+ *)')df['new_faculty'] = df['new_faculty'].str.strip()
df.sample(5)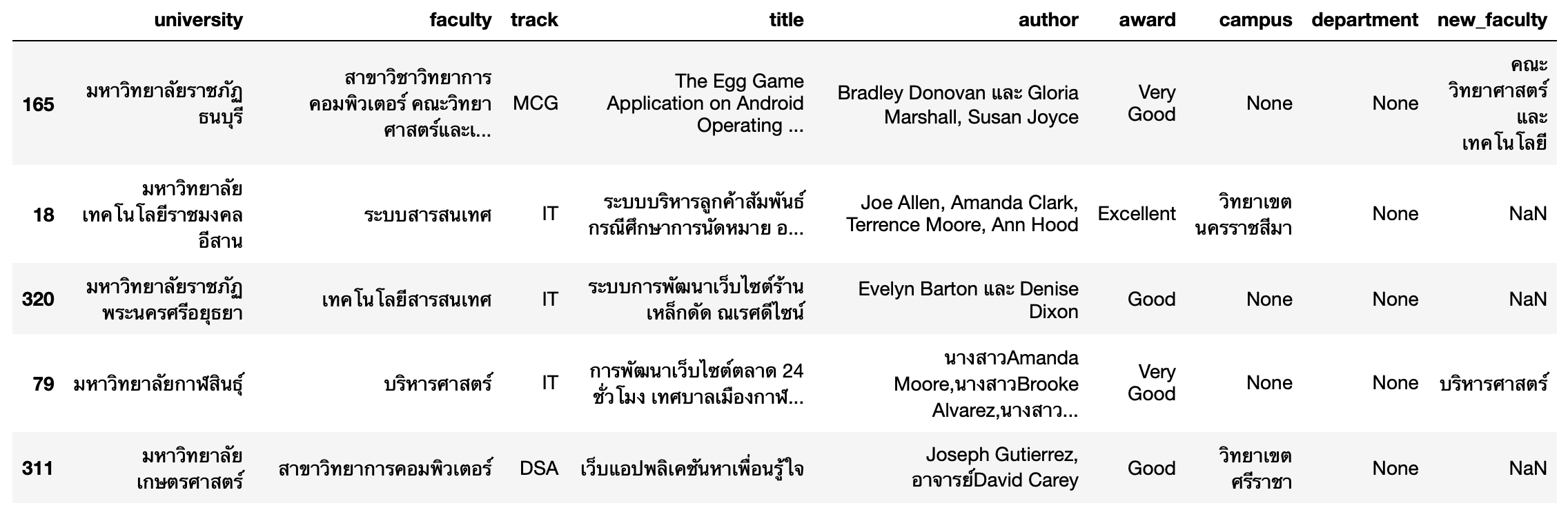
- ลบคณะ สำนัก Faculty และวิทยาลัย ออกจาก faculty เดิม
df['faculty'] = df['faculty'].str.replace(r'(คณะ\S+ *|สํานัก\S+ *|วิทยาลัย\S+ *|วิทยาศาสตร์และเทคโนโลยี *|วิทยาศาสตร์ *|บริหารศาสตร์ *|Faculty +of +\S+ *)', '', regex=True)df['faculty'] = df['faculty'].str.strip()
df.sample(5)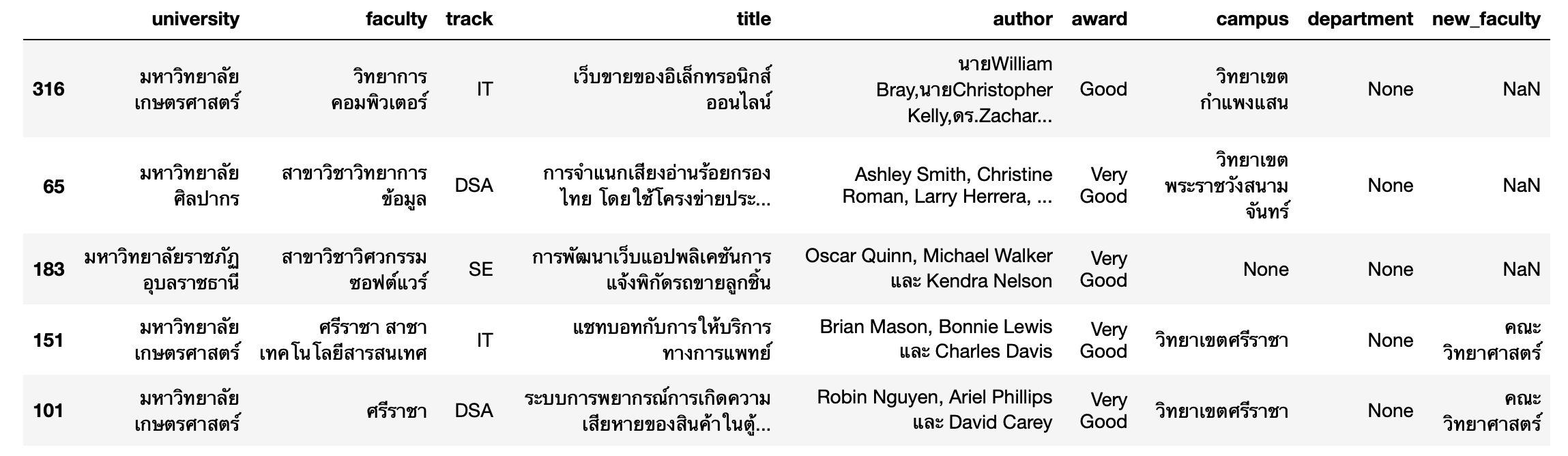
- เปลี่ยนชื่อคอลัมน์ faculty เดิมเป็น program
df.rename(columns={'faculty':'program'}, inplace=True)
df.columnsIndex(['university', 'program', 'track', 'title', 'author', 'award', 'campus', 'department', 'new_faculty'], dtype='object')
- เปลี่ยนชื่อคอลัมน์ new_faculty เป็น faculty
df.rename(columns={'new_faculty':'faculty'}, inplace=True)
df.columnsIndex(['university', 'program', 'track', 'title', 'author', 'award', 'campus', 'department', 'faculty'], dtype='object')
Load ลง Database
- Save ข้อมูลลง SQLite แล้วทดลอง Query ข้อมูล
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)%%sql
select * from aucc_award_table
where program is not ''
limit 5* sqlite:///aucc2021.db
Done.

- ลบ "ศรีราชา" และ "มหา" ออกจาก program
%%sql
update aucc_award_table
set program = ''
where program in ('ศรีราชา', 'มหา')* sqlite:///aucc2021.db
4 rows affected.
[]
แต่ละมหาวิทยาลัย มีคณะอะไรบ้างที่ส่งผลงาน และส่งจำนวนเท่าไหร่
Extract/Transform
- Query ดูคณะทั้งหมด เพื่อแก้ไข
%%sql
select distinct faculty
from aucc_award_table
where faculty is not null* sqlite:///aucc2021.db
Done.

พบว่าชื่อคณะมีการสะกดคำผิด รวมทั้งเขียนด้วย Style ที่หลากหลาย จึงใช้คำสั่ง SQL Update เพื่อแก้ไขข้อมูล ดังนี้
%%sql
update aucc_award_table
set faculty = 'คณะวิทยาศาสตร์'
where faculty in ('วิทยาศาสตร์', 'คณะวิทยาศาสตน์')* sqlite:///aucc2021.db
5 rows affected.
[]
%%sql
update aucc_award_table
set faculty = 'คณะบริหารธุรกิจ'
where faculty in ('คณะบริการธุรกิจ')* sqlite:///aucc2021.db
1 rows affected.
[]
%%sql
update aucc_award_table
set faculty = 'คณะบริหารศาสตร์'
where faculty in ('บริหารศาสตร์')* sqlite:///aucc2021.db
1 rows affected.
[]
%%sql
update aucc_award_table
set faculty = 'คณะวิทยาศาสตร์และเทคโนโลยี'
where faculty in ('วิทยาศาสตร์และเทคโนโลยี', 'คณะวิทยาศาสตร์เเละเทคโนโลยี', 'คณะวิทยาศาตร์และเทคโนโลยี')* sqlite:///aucc2021.db
6 rows affected.
[]
%%sql
update aucc_award_table
set faculty = 'คณะการบัญชีและการจัดการ'
where faculty in ('คณะบัญชีและการจัดการ')* sqlite:///aucc2021.db
1 rows affected.
[]
%%sql
update aucc_award_table
set faculty = 'คณะวิทยาศาสตร์และเทคโนโลยี'
where faculty in ('คณะวิทยาศาสตร์') and university = 'มหาวิทยาลัยราชภัฏนครสวรรค์'* sqlite:///aucc2021.db
1 rows affected.
[]
%%sql
update aucc_award_table
set faculty = 'คณะวิทยาการสารสนเทศ'
where faculty in ('Faculty of Informatics')* sqlite:///aucc2021.db
1 rows affected.
[]
Report
%%sql result <<
select university, faculty, count(*) as paper
from aucc_award_table
where faculty is not null
group by university, facultyfig = px.bar(result.DataFrame(), x='faculty', y='paper', color='university', title='AUCC Paper Faculty', height=1000)
fig.update_xaxes(tickangle=90)
fig.show()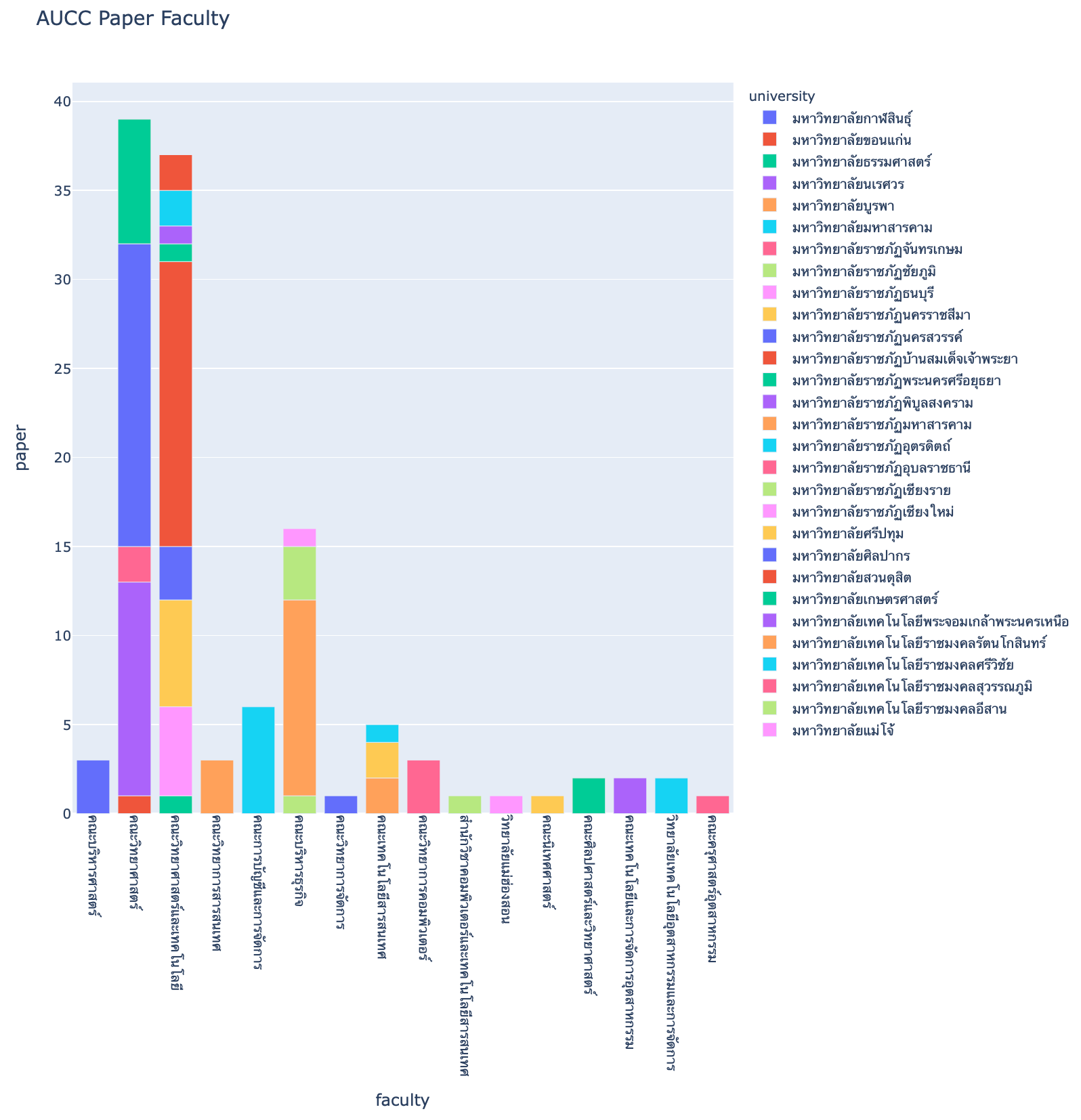
*หมายเหต ผู้อ่านสามารถแก้ไขชื่อ Department และ Program ที่ซ้ำซ้อนกันได้ดังเช่นการแก้ไขชื่อ Faculty ครับ
แต่ละมหาวิทยาลัยส่ง Paper Track อะไรบ้าง จำนวนเท่าไหร่
Extract
%%sql
select university, track, count(*) as paper
from aucc_award_table
group by university, track
limit 10* sqlite:///aucc2021.db
Done.

%%sql result <<
select university, track, count(*) as paper
from aucc_award_table
group by university, track* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()df.shape(101, 3)
Transform
- Pivot ข้อมูลโดยให้แต่ละแถวเป็นชื่อมหาวิทยาลัย คอลัมน์เป็น Track ค่าในแต่ละ Cell คือ จำนวน Papar
matrix = df.pivot(index='university', columns='track', values='paper')matrix.head()
- แทนที่ NaN ด้วย 0
matrix.fillna(0, inplace=True)
matrix.head()
- เปลี่ยนประเภทข้อมูลจาก Float เป็น Integer
matrix = matrix.astype(int)matrix.head()
- Sum จำนวน Paper ของแต่ละมหาวิทยาลัย (axis=1 คือ การกำหนดให้ Sum ข้อมูลตามแถว)
matrix['sum'] = matrix.sum(axis=1)matrix.head()
- เรียงลำดับมหาวิทยาลัยตามจำนวน Paper จากมากไปน้อย
matrix = matrix.sort_values('sum', ascending=False)matrix.head()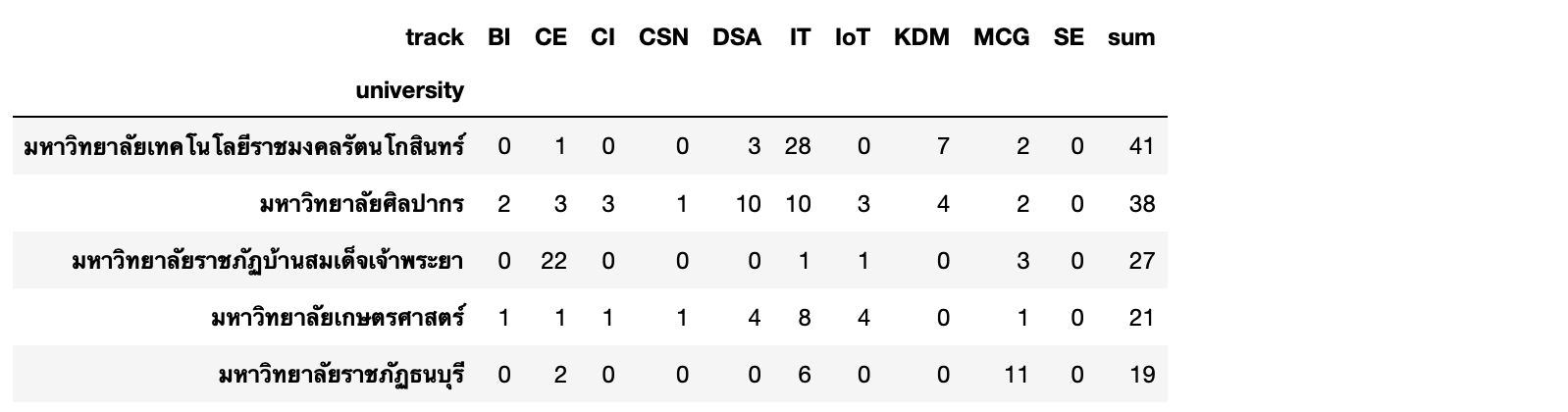
Load/Report
- สร้าง File CSV
matrix.to_csv('track.csv', encoding='utf8')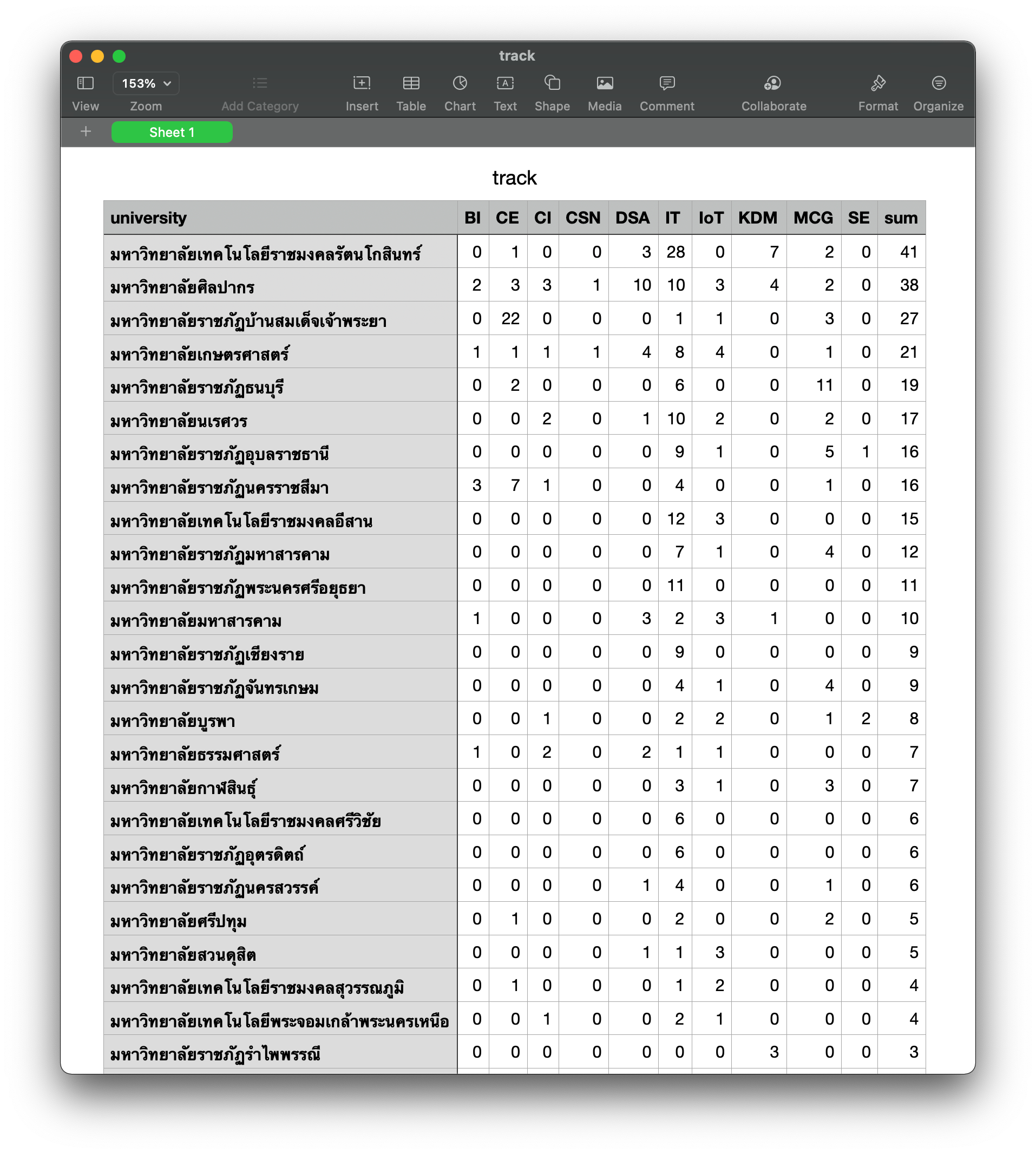
จำนวน Paper ของแต่ละ Track
Report
%%sql
select track, count(*) as paper
from aucc_award_table
group by track* sqlite:///aucc2021.db
Done.

%%sql result <<
select track, count(*) as paper
from aucc_award_table
group by track* sqlite:///aucc2021.db
Done.
Returning data to local variable result
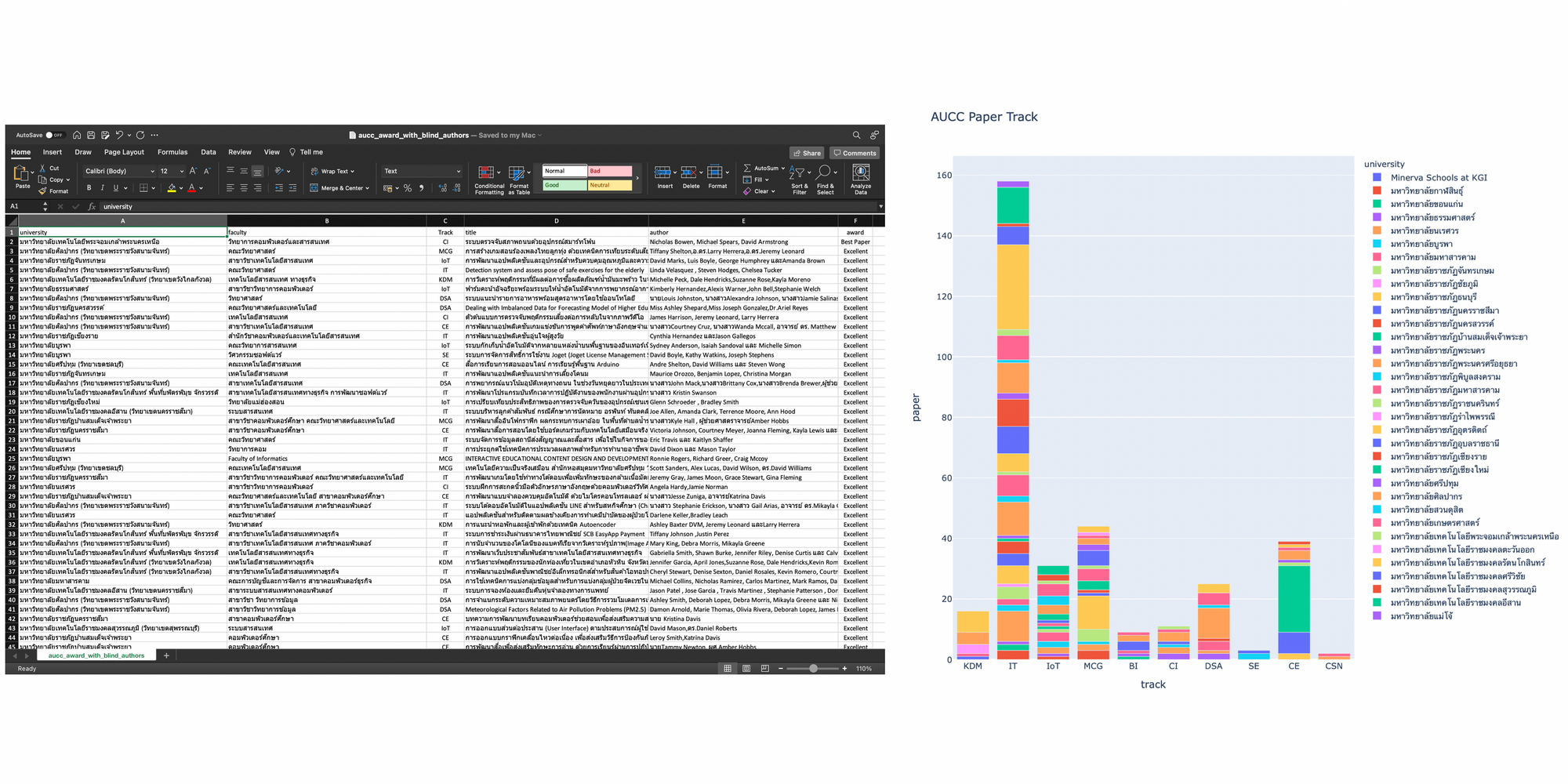
fig = px.bar(result.DataFrame(), x='track', y='paper', text='paper', title='AUCC Paper Track', height=800)
fig.show()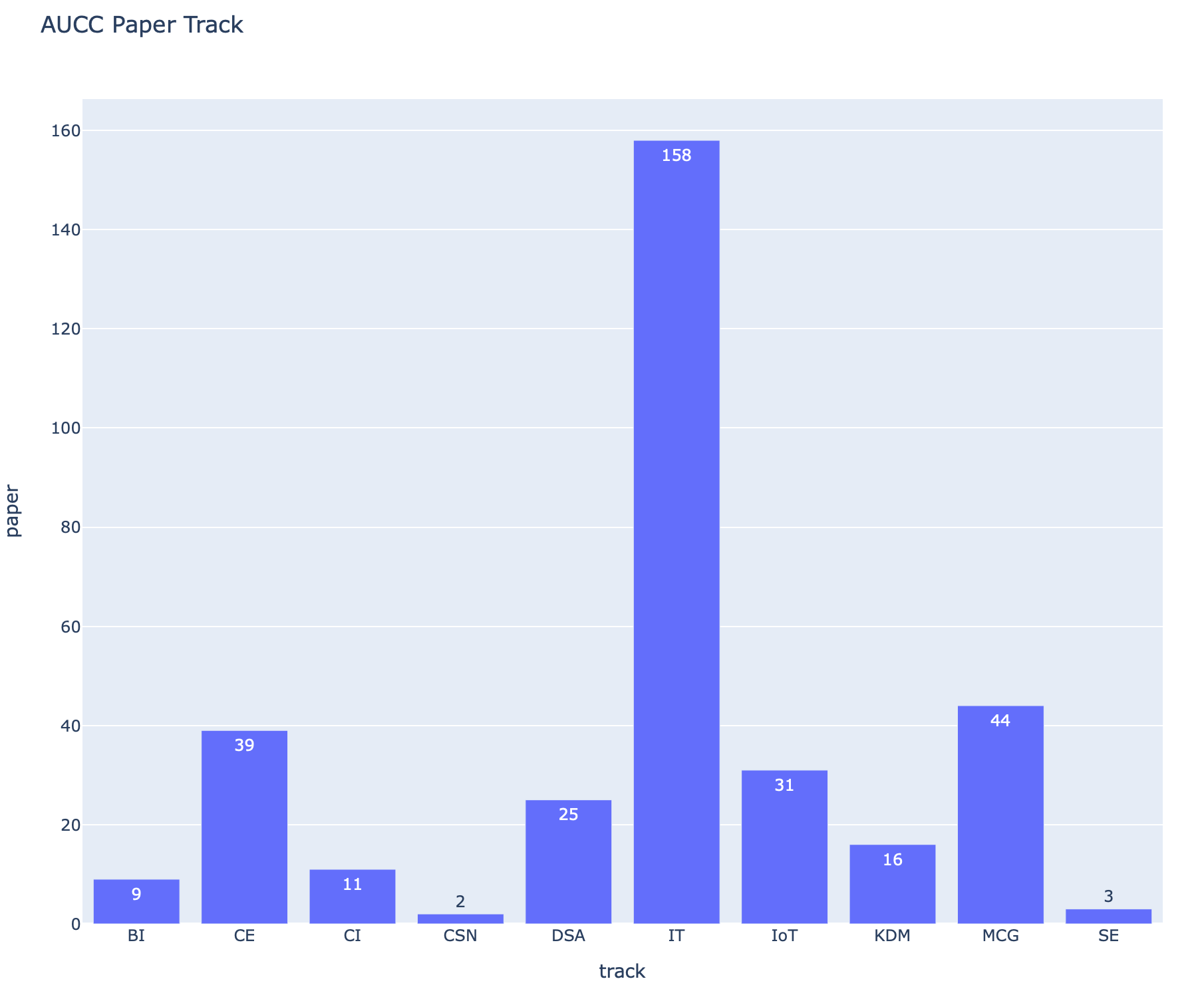
%%sql result <<
select university, track, count(*) as paper
from aucc_award_table
group by university, track* sqlite:///aucc2021.db
Done.
Returning data to local variable result
fig = px.bar(result.DataFrame(), x='track', y='paper', color='university', title='AUCC Paper Track', height=900)
fig.show()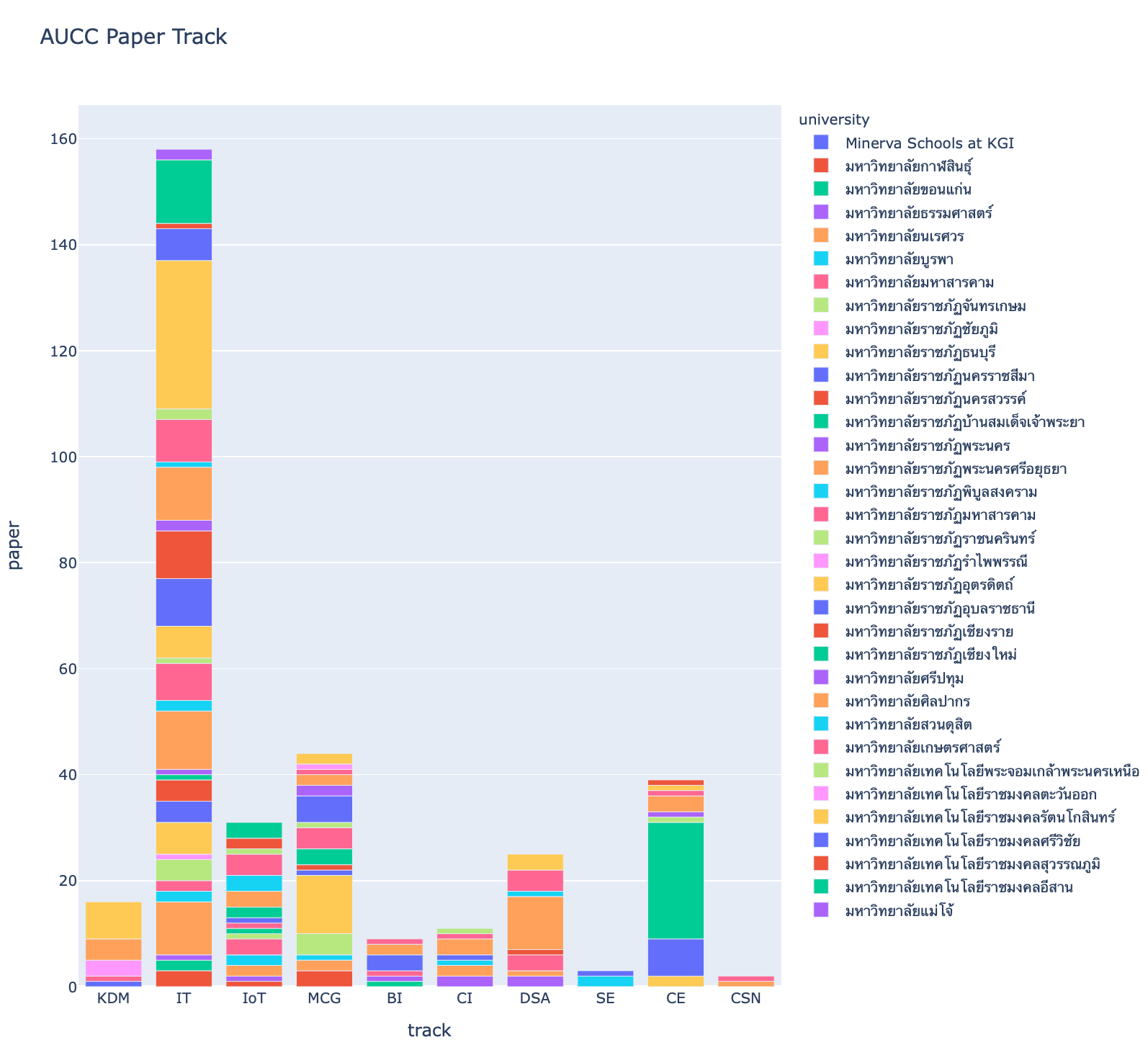
จำนวน Paper ภาษาไทย และจำนวน Paper ภาษาอังกฤษ
ในส่วนนี้ผู้อ่านจะได้เห็นตัวอย่างการใช้ Regular Expression ในการค้นหาภาษาไทยใน Title ของ Paper โดยเรา สมมติ ว่า Paper ที่มี Title เป็นภาษาอังกฤษ คือ Paper ภาษาอังกฤษ
Example
S=pd.Series(['ดูสถานะสุขภาพและแจ้งเตือนสำหรับผู้สูงอายุ','Detection system and assess pose of safe exercises for the elderly','ระบบการชำระเงินผ่านธนาคารไทยพาณิชย์ SCB EasyApp Payment'])
S
- ค้นหาภาษาไทยในชื่อ Paper
S.str.contains('[ก-๙]')
Extract
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()Transform
- สร้างคอลัมน์ th โดยให้ค่าเป็น 1 เมื่อพบข้อความภาษาไทยใน Title และให้ค่าเป็น 0 เมื่อไม่พบข้อความภาษาไทย
df['th'] = df['title'].str.contains('[ก-๙]')Load ลง Database
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)Report
- จำนวน Paper ภาษาอังกฤษ
%%sql
select count(*) as eng
from aucc_award_table
where th=True* sqlite:///aucc2021.db
Done.

- จำนวน Paper ภาษาไทย
%%sql
select count(*)
from aucc_award_table* sqlite:///aucc2021.db
Done.

*ไม่มีชื่อ Paper 1 Paper
จำนวน Paper ที่เกี่ยวข้องกับ Topic ต่างๆ
การพัฒนา Chatbot (โต้ตอบอัตโนมัติ)
Example
S=pd.Series(['การพัฒนาระบบโต้ตอบอัตโนมัติด้วยไดอล็อกโฟลสำหรับเฟซบุ๊กแฟนเพจ','ระบบโต้ตอบอัตโนมัติในแอปพลิเคชัน LINE สำหรับสหกิจศึกษา (Chatbot based on LINE Application for Cooperative Education)','ระบบติดตามสถานการณ์ดำเนินงานของเจ้าหน้าที่ผ่าน Line chatbot', 'การสร้างเกมสอนร้องเพลงไทยลูกทุ่ง ด้วยเทคนิคการเทียบระดับเสียง'])
S
- เราจะทดลองใช้ str.contains ในการค้นหาส่วนหนึ่งของข้อความว่า โต้ตอบอัตโนมัติ หรือ Chatbot หรือ chatbot ในข้อความตัวอย่าง
S.str.contains(r'โต้ตอบอัตโนมัติ|[Cc]hatbot')
Extract
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()Report
- แสดงข้อมูลของ Paper ที่พบส่วนหนึ่งของข้อความว่า โต้ตอบอัตโนมัติ หรือ Chatbot หรือ chatbot ใน Title
df[df['title'].str.contains(r'โต้ตอบอัตโนมัติ|[Cc]hatbot')==True]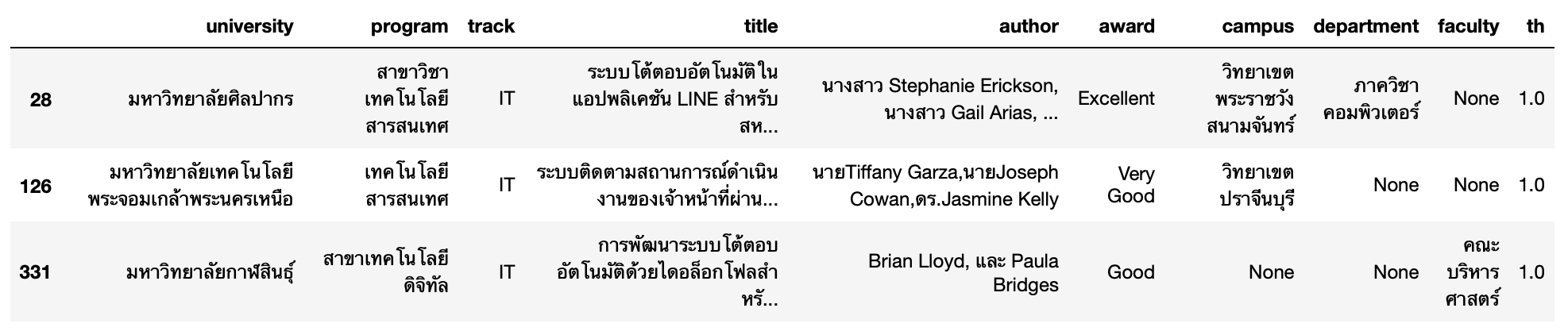
- แสดงจำนวน Papar ที่เกี่ยวข้องกับการพัฒนา Chatbot
df[df['title'].str.contains(r'โต้ตอบอัตโนมัติ|[Cc]hatbot')==True].shape(3, 10)
การจำแนกข้อมูล
Example
S=pd.Series(['การจำแนกเสียงอ่านร้อยกรองไทย โดยใช้โครงข่ายประสาทเทียม (Thai Poetry Reading Sound Classification using Neural Network)','Poisonous Spider Classification using Convolutional Neuron', 'ระบบจัดการร้านรับซื้อ-ขายผ้าอเนกประสงค์'])
S
- ทดลองค้นหาคำว่า จำแนก หรือ Classification หรือ classification ในข้อความตัวอย่าง
S.str.contains(r'จำแนก|[Cc]lassification')
Report
- แสดงข้อมูลของ Paper ที่พบคำว่า จำแนก หรือ Classification หรือ classification ใน Title
df[df['title'].str.contains(r'จำแนก|[Cc]lassification')==True]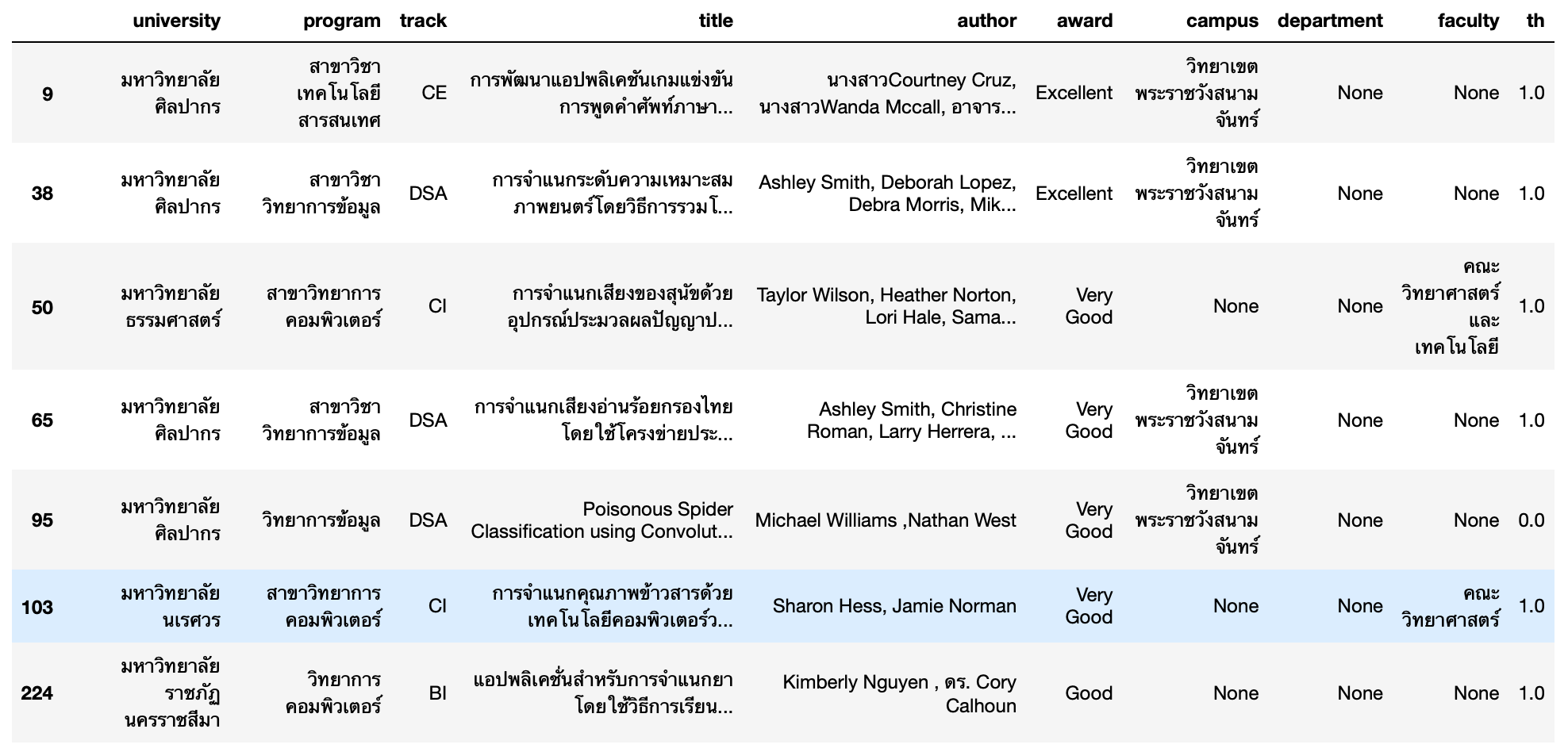
- แสดงจำนวน Paper ที่เกี่ยวข้องกับการจำแนกข้อมูล
df[df['title'].str.contains(r'จำแนก|[Cc]lassification')==True].shape(7, 10)
จำนวนรางวัล แต่ละรางวัลที่แต่ละมหาวิทยาลัยได้รับ
Extract
%%sql
select university, award, count(*) as paper
from aucc_award_table
group by university, award
limit 10* sqlite:///aucc2021.db
Done.

%%sql result <<
select university, award, count(*) as paper
from aucc_award_table
group by university, award* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()df.shape(81, 3)
Transform
- Pivot ข้อมูลโดยให้แต่ละแถวเป็นชื่อมหาวิทยาลัย คอลัมน์เป็น Award ข้อมูลในแต่ละ Cell คือ จำนวน Papar
matrix = df.pivot(index='university', columns='award', values='paper')
matrix.head()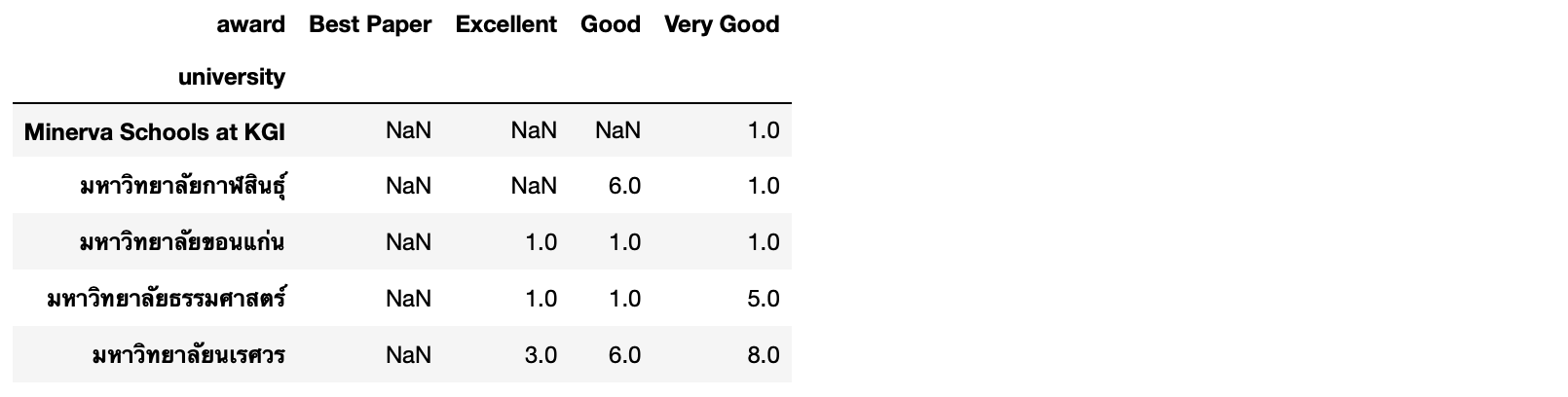
- แทนที่ NaN ด้วย 0 และเปลี่ยนประเภทข้อมูลจาก Float เป็น Integer
matrix.fillna(0, inplace=True)
matrix = matrix.astype(int)
matrix.head()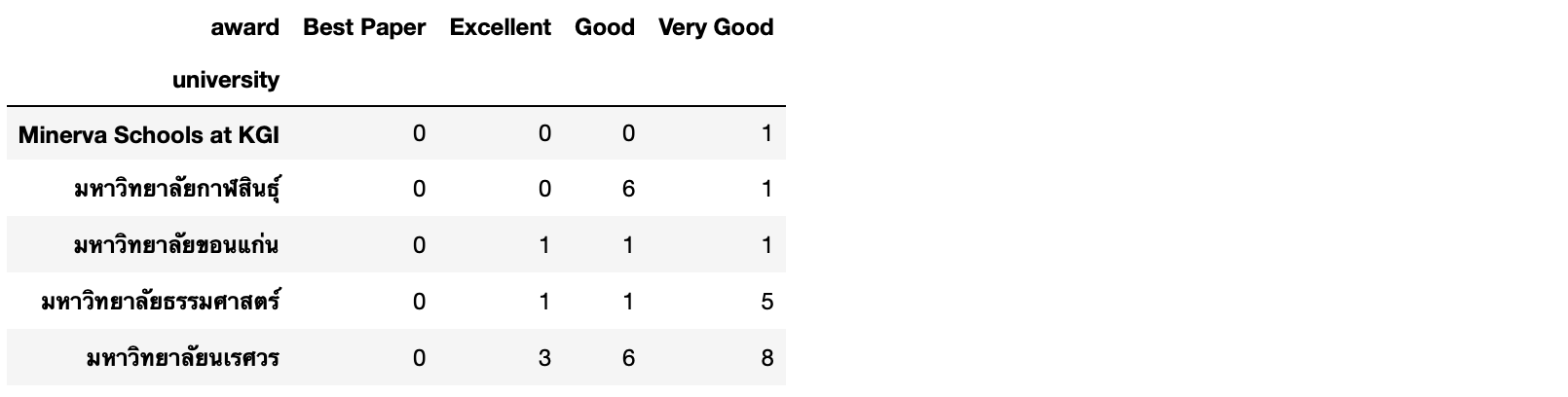
matrix['sum'] = matrix.sum(axis=1)
matrix = matrix.sort_values('sum', ascending=False)
matrix.head()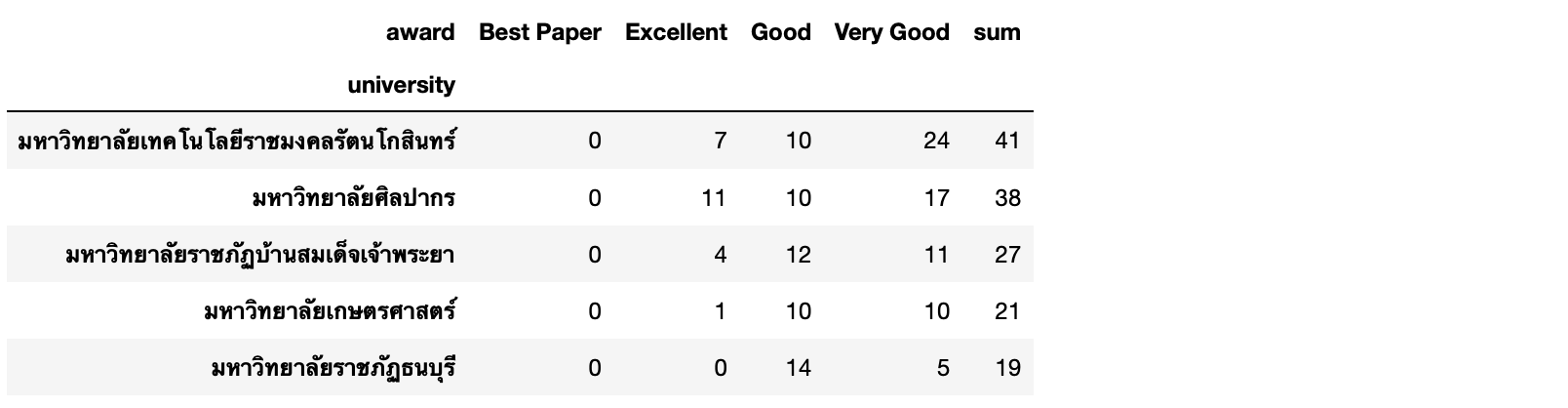
- แก้ชื่อคอลัมน์จาก 'Good ' เป็น 'Good'
matrix.columnsIndex(['Best Paper', 'Excellent', 'Good ', 'Very Good', 'sum'], dtype='object', name='award')
matrix.rename(columns={'Good ':'Good'}, inplace=True)
df.columnsIndex(['university', 'award', 'paper'], dtype='object')
Load/Report
- สร้าง File CSV
matrix.to_csv('award.csv', encoding='utf8', columns=['Best Paper', 'Excellent', 'Very Good', 'Good', 'sum'])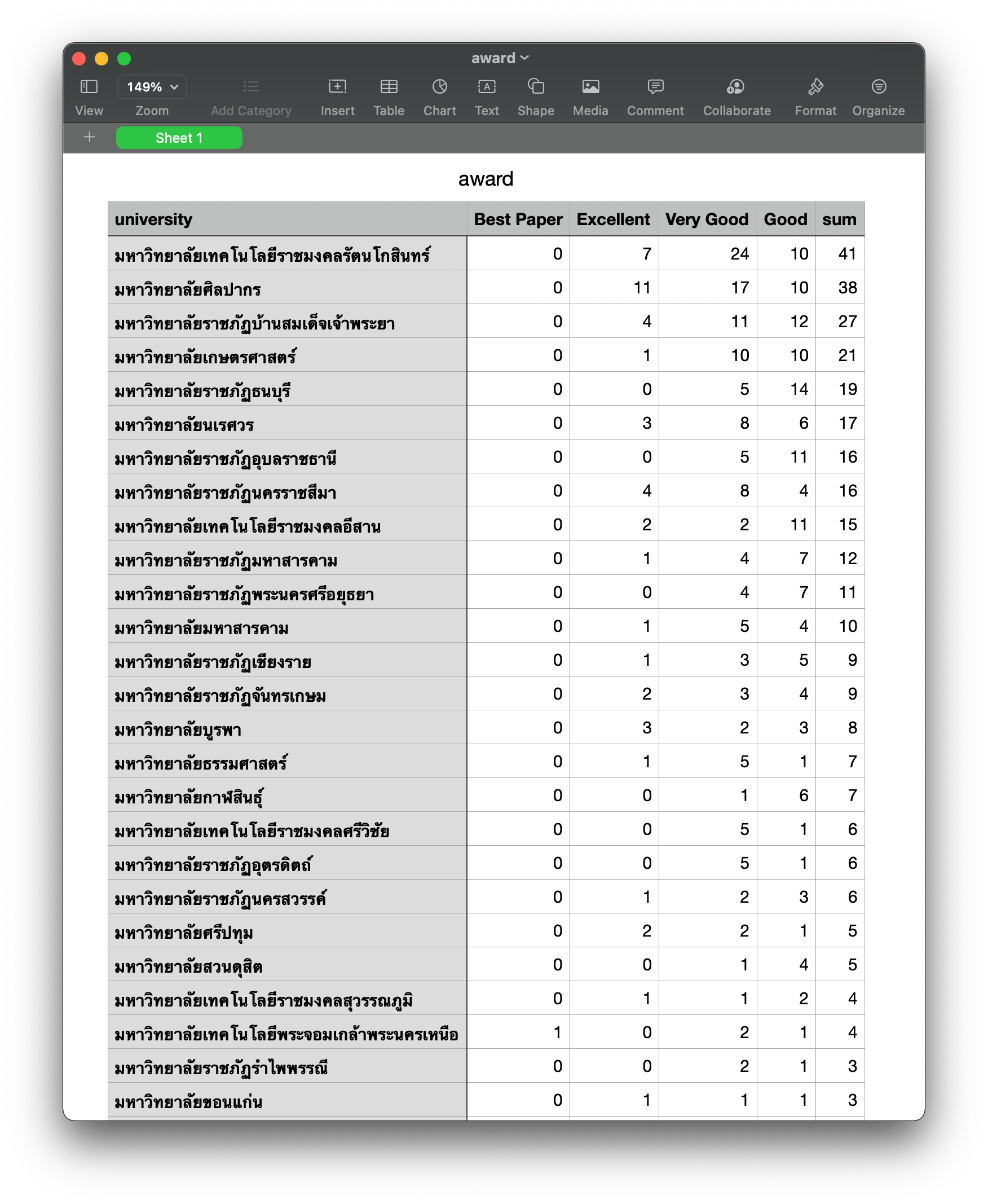
x = matrix.index[:10]
fig = go.Figure(go.Bar(x=x, y=matrix.iloc[:10]['Good'], name='Good'))
fig.add_trace(go.Bar(x=x, y=matrix.iloc[:10]['Very Good'], name='Very Good'))
fig.add_trace(go.Bar(x=x, y=matrix.iloc[:10]['Excellent'], name='Excellent'))
fig.add_trace(go.Bar(x=x, y=matrix.iloc[:10]['Best Paper'], name='Best Paper'))
fig.update_layout(barmode='stack', height=800, title='AUCC Paper Award')
fig.update_xaxes(tickangle=90)
fig.show()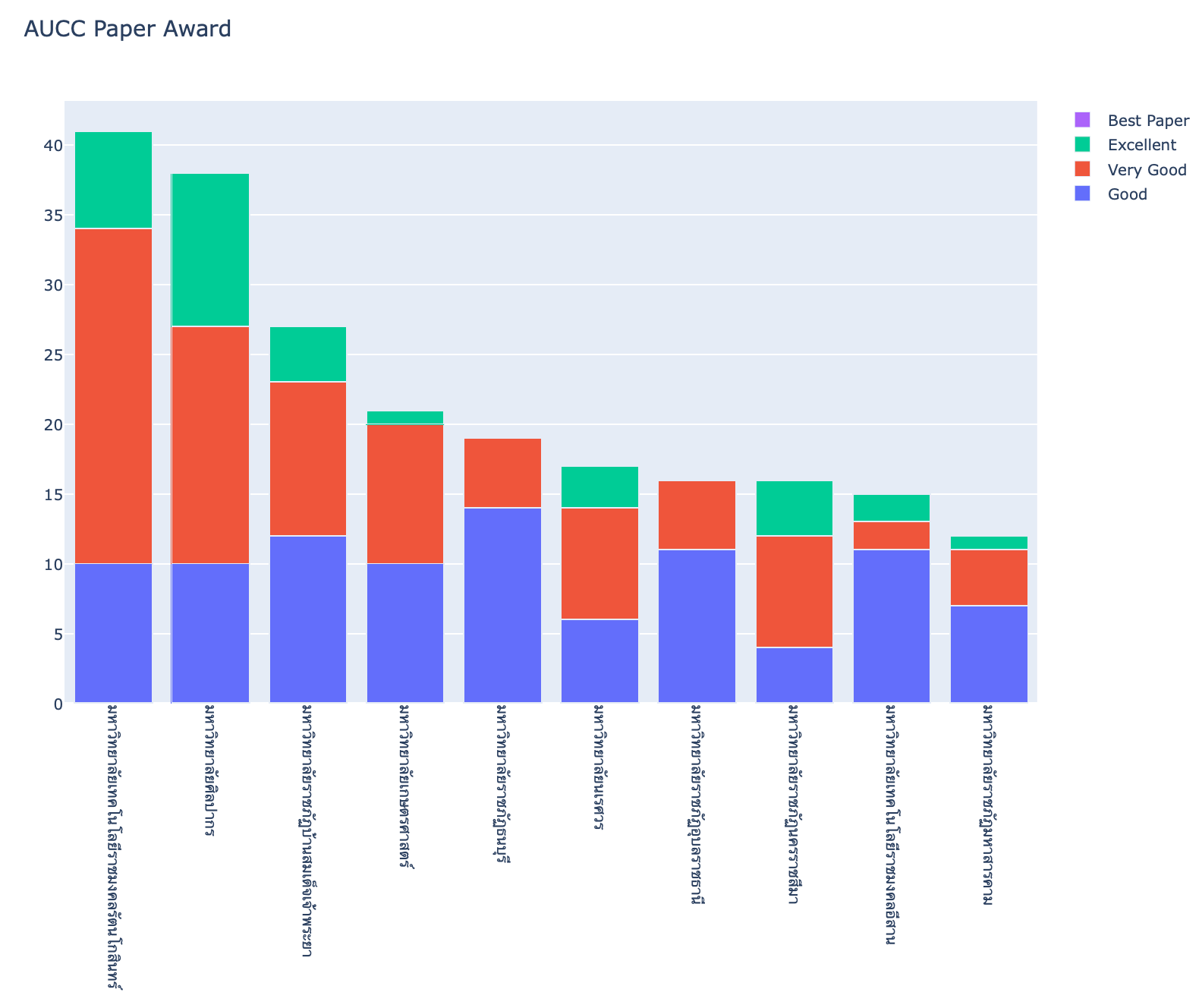
จำนวนผู้แต่งในแต่ละ paper
Example
S=pd.Series([' David Marks, Luis Boyle, George Humphrey และAmanda Brown', '*สัจจาภรณ์ ไวจรรยา และนายณัฐโชติ พรหมฤทธิ์ (Nuttachot Promrit)'])
S
- ทดลองขจัด Noise ต่างๆ ใน Author
S.replace(r'( *, *)',' , ',regex=True, inplace = True)
S
S.replace(r'(นางสาว|นาย|\S+\.\S+\.|\S+\.|อาจารย์|ผู้ช่วยศาสตราจารย์|รองศาสตราจารย์|Miss|Mister|Misses|\(.*\)|\d+|\*)','',regex=True, inplace = True)
S
S.replace(r'(และ| +and +)',',',regex=True, inplace = True)
S
S.replace(r'( *, *)',',',regex=True, inplace = True)
S
S = S.str.strip()
S.replace(r'( +)', ' ',regex=True, inplace = True)
S
- ทดลอง Split ชื่อผู้แต่งออกจากกัน
S = S.str.split(',')
S
Extract
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()Transform
- ขจัด Noise ต่าง ๆ ใน Author
df['author'] = df['author'].str.replace(r'( *, *)',' , ', regex=True)
df.sample(5)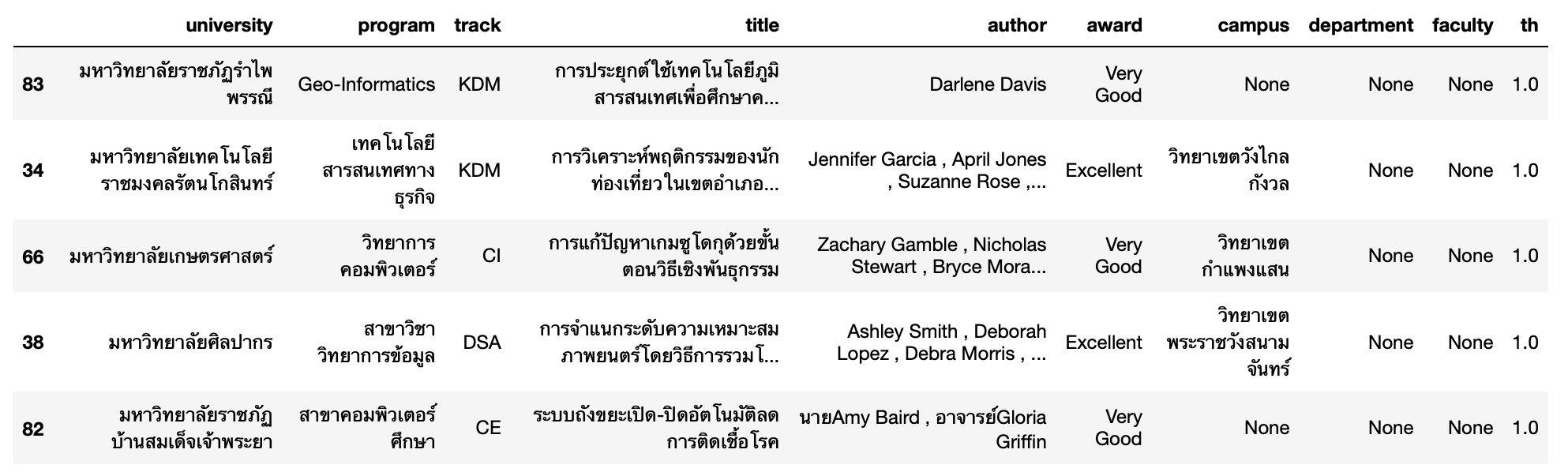
df['author'] = df['author'].str.replace(r'(นางสาว|นาย|\S+\.\S+\.|\S+\.|อาจารย์|ผู้ช่วยศาสตราจารย์|รองศาสตราจารย์|Miss|Mister|Misses|\(.*\)|\d+|\*)','', regex=True)
df.sample(5)
df['author'] = df['author'].str.replace(r'(และ| +and +)',',', regex=True)
df.sample(5)
df['author'] = df['author'].str.replace(r'( *, *)',',', regex=True)
df.sample(5)
df['author'] = df['author'].str.strip()
df.sample(5)
df['author'] = df['author'].str.replace(r'( +)', ' ', regex=True)
df.sample(5)
- Split ชื่อผู้แต่งออกจากกัน แล้วเก็บลงในคอลัมน์ new_author
df['new_author'] = df['author'].str.split(',')
df.sample(5)
- แปลงชื่อผู้แต่งที่ Split แล้วเป็น Array
paper_author = df.new_author.to_numpy()- แทนที่ Empty Array ด้วย '' (สำหรับ Paper ที่ไม่พบ Author)
convert = lambda i : i or ''
paper_author = [convert(author_list) for author_list in paper_author]- นับจำนวน Author ในแต่ละ Paper
author_number = [len(author_list) for author_list in paper_author]author_number[:10][3, 3, 4, 3, 4, 4, 4, 3, 3, 4]
- สร้าง DataFrame จาก Dict
new_df = pd.DataFrame({'author_number': author_number})
new_df.shape(338, 1)
new_df.head()
- Concat คอลัมน์ author_number กับข้อมูล Paper เดิม
df = pd.concat ([df, new_df], axis=1)
df.shape(338, 12)
df.head()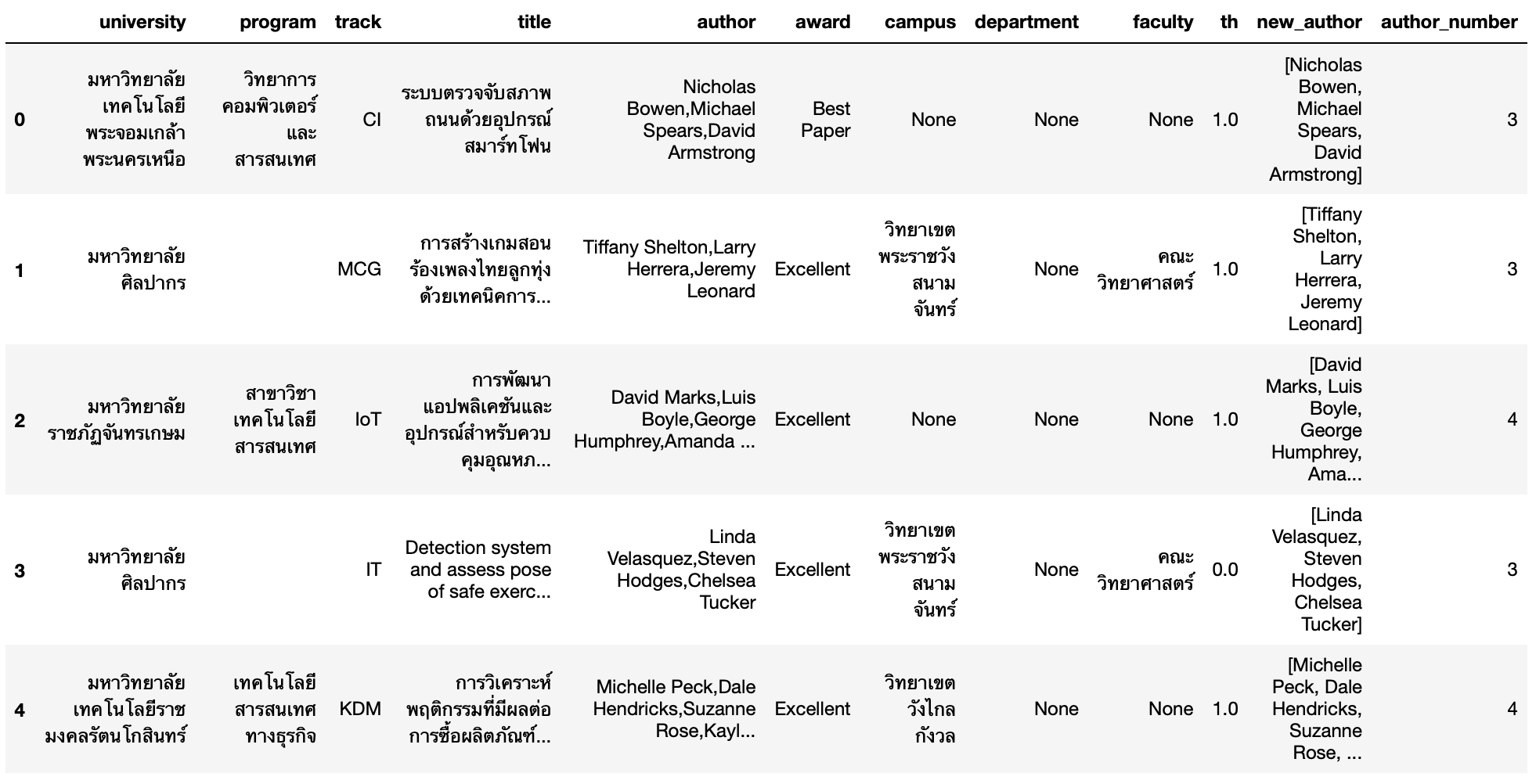
- คอลัมน์ new_author
df.drop(columns=['new_author'], inplace=True)df.columnsIndex(['university', 'program', 'track', 'title', 'author', 'award', 'campus', 'department', 'faculty', 'th', 'author_number'], dtype='object')
Load ลง Database
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)Report
%%sql
select *
from aucc_award_table
order by author_number desc limit 5* sqlite:///aucc2021.db
Done.
รายชื่อผู้แต่งที่มีชื่อในผลงานมากที่สุด 10 อันดับ
Transform
paper_author[:5]
- Flat Array 2 มิติของรายชื่อ Author ในแต่ละ Paper เป็น Array 1 มิติ
flattened_paper_author = [item for sublist in paper_author for item in sublist]- นับจำนวน Paper ของแต่ละ Author
c = Counter(flattened_paper_author)c = dict(c)
c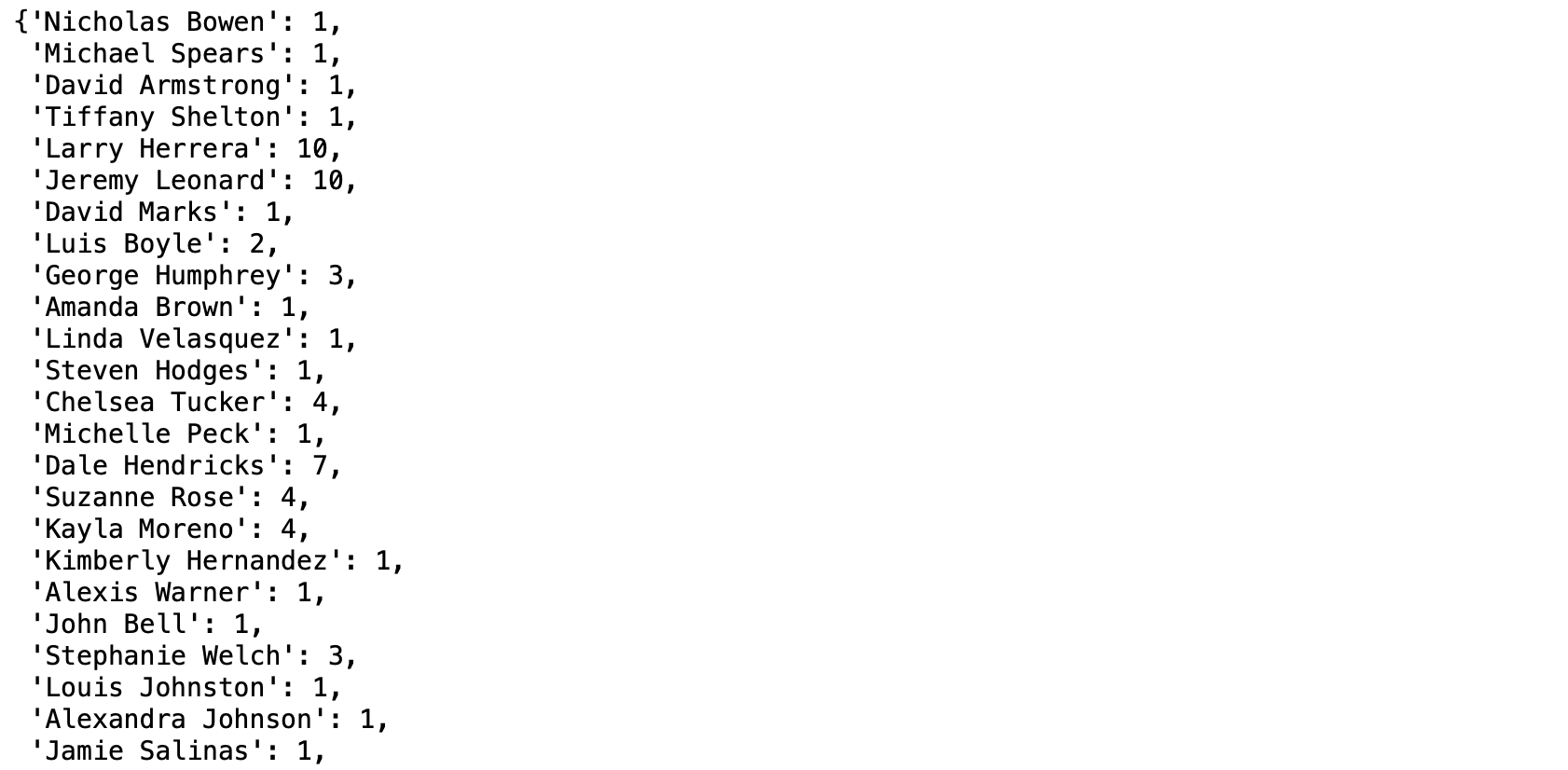
- สร้าง DataFrame จำนวน Paper ของแต่ละ Author จาก Tuple
df = pd.DataFrame(list(c.items()), columns = ['author','paper'])
df.head()
Load ลง Database
- บันทึกข้อมูลจำนวน Paper ของแต่ละ Author ลงตาราง author_table
df.to_sql("author_table", connect, if_exists='replace', index=False)- แสดงตารางทั้งหมดใน Database
%%sql
select name
from sqlite_master
where type = "table"* sqlite:///aucc2021.db
Done.

Report
%%sql
select *
from author_table
where author is not ''
order by paper desc
limit 10* sqlite:///aucc2021.db
Done.

%%sql result <<
select *
from author_table
where author is not ''
order by paper desc
limit 10* sqlite:///aucc2021.db
Done.
Returning data to local variable result
fig = px.bar(result.DataFrame(), x='author', y='paper', text='paper', title='AUCC Paper Author', height=550)
fig.update_xaxes(tickangle=90)
fig.show()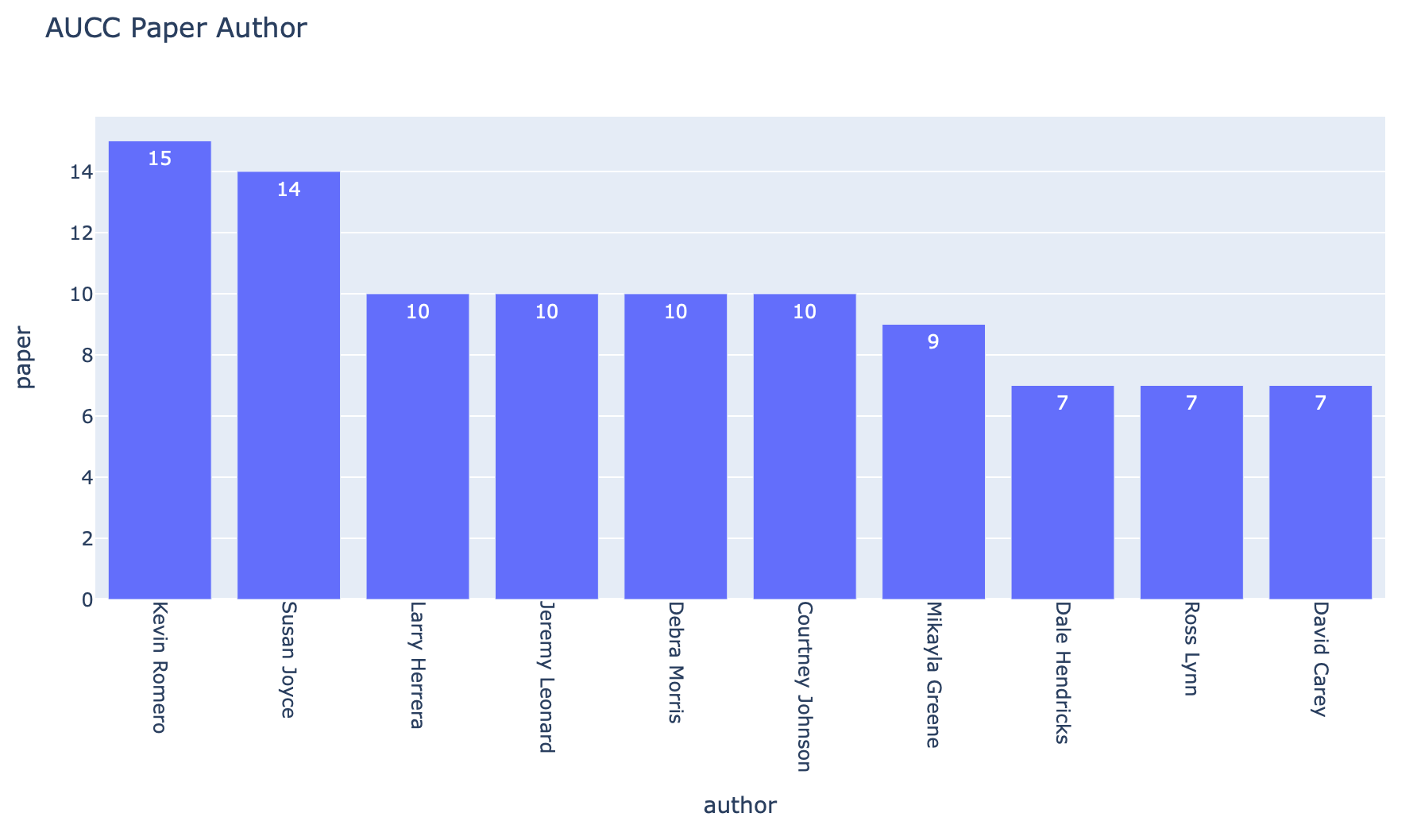
จำนวนผู้แต่งทั้งหมด
Report
%%sql
select count(*) as total_author
from author_table
where author is not ''* sqlite:///aucc2021.db
Done.
