Introduction to Deep Learning (Machine Learning Pipeline)


บทความโดย ผศ.ดร.ณัฐโชติ พรหมฤทธิ์
ภาควิชาคอมพิวเตอร์
คณะวิทยาศาสตร์
มหาวิทยาลัยศิลปากร
Deep Learning เป็น Neural Network แบบหนึ่ง ที่มักจะใช้ในการแก้ปัญหาในงานอย่างเช่น การแยกประเภทภาพ (Image Classification) การตรวจจับใบหน้า (Face Detection) และการวิเคราะห์ความรู้สึก (Sentiment Analysis) ฯลฯ ซึ่งในการ Train ให้ Neural Network Model สามารถเรียนรู้ได้ เราจะต้องนำ Dataset มาเป็น Input ของ Model
Neural Network Types
Neural Network นั้นมีหลากหลายประเภท โดยแต่ละประเภทจะมีประสิทธิภาพและการใช้งานที่แตกต่างกัน
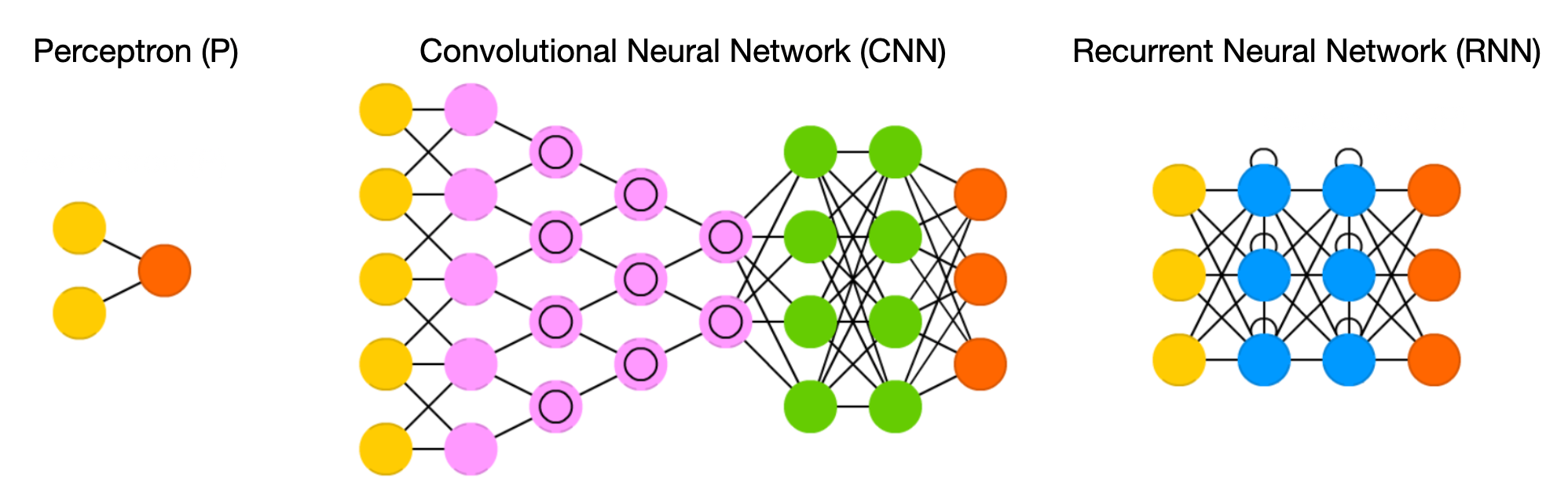
Perceptron (P) เป็น Neural Network อย่างง่าย ที่จำลองการทำงานของเซลล์ประสาทมนุษย์ ซึ่งมี Input Node สำหรับรับข้อมูลจาก Dataset และคำนวณผลลัพธ์ออกทาง Output Node
จากภาพด้านบนซ้ายมือ เราเรียก Input Node ที่มี Cell ประสาท จำนวน 2 Cell ว่า Input Layer และ Output Node ที่มี Cell ประสาท จำนวน 1 Cell ว่า Output Layer แต่เมื่อมีการนับจำนวน Layer ตามธรรมเนียม Input จะไม่ถูกนับเป็น 1 Layer ดังนั้น Perceptron จึงมี Layer ทั้งหมด 1 Layer
Convolutional Neural Network (CNN) เป็น Neural Network ที่มอง Dataset ที่รับผ่าน Input Layer เป็นเหมือนภาพภาพหนึ่ง เช่นเดียวกับที่จอประสาทตาของมนุษย์มีการรับแสงที่ตกกระทบมาจากวัตถุต่างๆ
จากภาพ CNN ด้านบน จะมี Input Node สำหรับรับข้อมูล และ Output Node สำหรับคำนวณผลลัพธ์ รวมทั้ง Hidden Layer อีก 6 Layer ดังนั้นจึงมีจำนวน Layer ทั้งหมด 7 Layer ไม่รวม Input Layer โดยเราจะเรียก Neural Network ที่มีจำนวน Hidden Layer มากๆ ว่า Deep Neural Network หรือ Deep Learning ซึ่งโดยปกติถ้ามันมี Hidden Layer ตั้งแต่ 3 Layer ขึ้นไป เราจะเริ่มเรียกมันว่า Deep Learning
Recurrent Neural Network (RNN) เป็น Neural Network ที่รับ Dataset ผ่าน Input Node แบบ Time Series หรือข้อมูลที่มีลักษณะเป็นลำดับ (Sequence) เช่น ลำดับของคำในประโยค ลำดับของ Frame จาก Video หรือลำดับของราคาทองคำแต่ละวันในตลาดโลก ซึ่งจะต้องถูกประมวลผลตามลำดับเพื่อจะทำนายได้ถูกต้อง เช่น คำว่า "พัดลม" กับ "ลมพัด"
Perceptron, Activation Function, Loss Function and Optimizer
ในบนความนี้เราจะเริ่มต้นศึกษา Neural Network และทำความเข้าใจกระบวนการพัฒนา Model แบบ CNN ในลักษณะของการทำ Workshop แต่ก่อนจะทำ Workshop เราจะกลับมาดู Perceptron แบบละเอียดขึ้นอีกนิดครับ
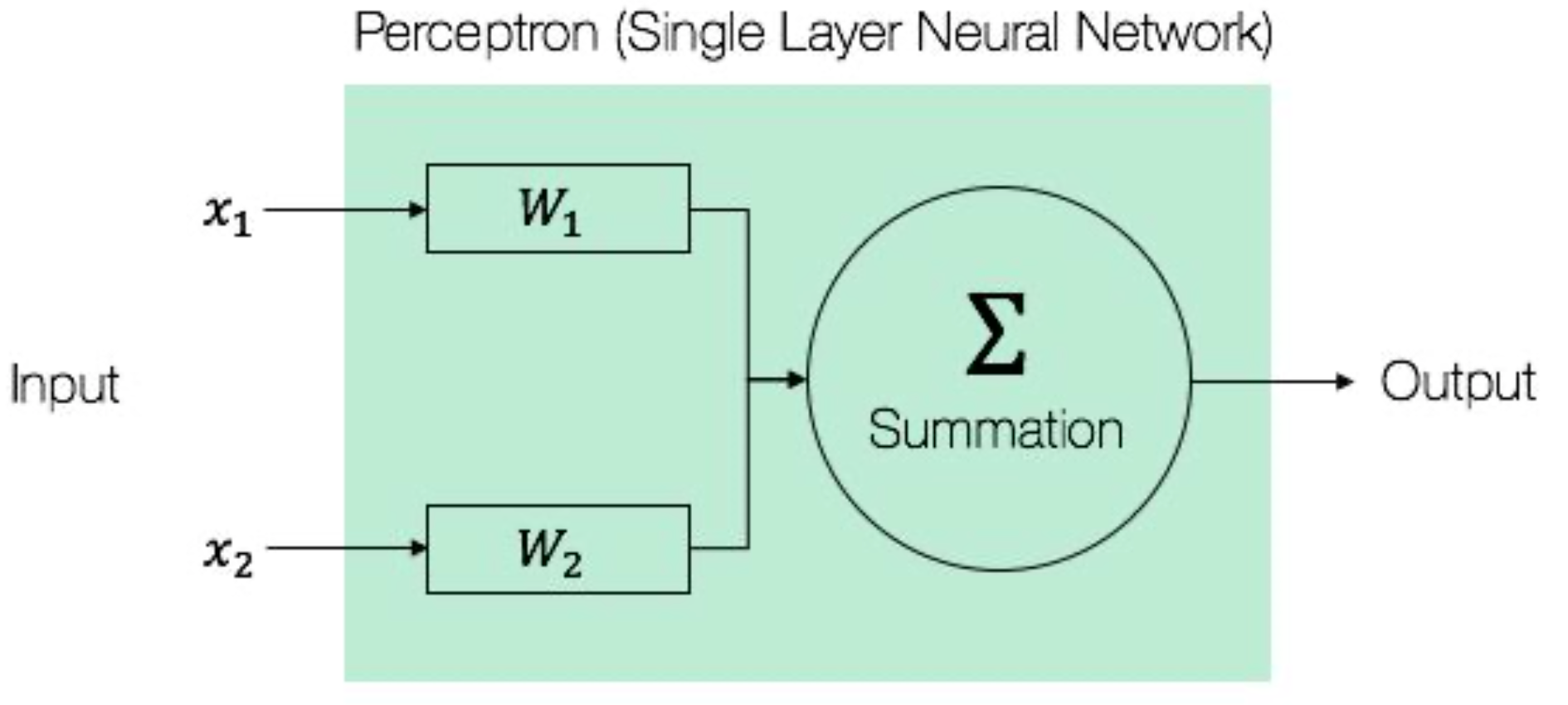
ในการ Train Model แบบ Perceptron นั้น Input ที่เข้ามายังแต่ละ Node จะถูกนำมาคูณกับตัวเลขแบบทศนิยมค่าหนึ่งซึ่งเรียกว่า Weight ที่เกิดจากการสุ่มในช่วงเริ่มต้น โดยจากภาพด้านบน x1 จะถูกนำมาคูณกับ Weight ตัวแรก (W1) และ x2 จะถูกนำมาคูณกับ Weight ตัวที่สอง (W2) แล้วนำผลลัพธ์จากการคูณของตัวเลขทั้ง 2 Node มาบวกกันกลายเป็นผลลัพธ์ ที่จะออกไปยัง Output Node โดยอาจมีการบวกตัวเลขแบบทศนิยมอีกค่า (b หรือเรียกว่า Bias) ที่เกิดจากการสุ่มในตอนแรกด้วย เพื่อทำให้ผลลัพธ์มีความถูกต้องยิ่งขึ้น
t = (x1 x W1) + (x2 x W2) + bแต่ก่อนที่จะส่งผลลัพธ์ออกมา บางครั้งเราจะนำมันมาปรับค่าด้วยฟังก์ชันอย่างเช่น Sigmoid Function เพื่อทำให้มันมีค่าในช่วง 0 - 1 ซึ่งเราเรียกฟังก์ชันสำหรับการปรับค่าอย่างนี้ว่า Activation Function
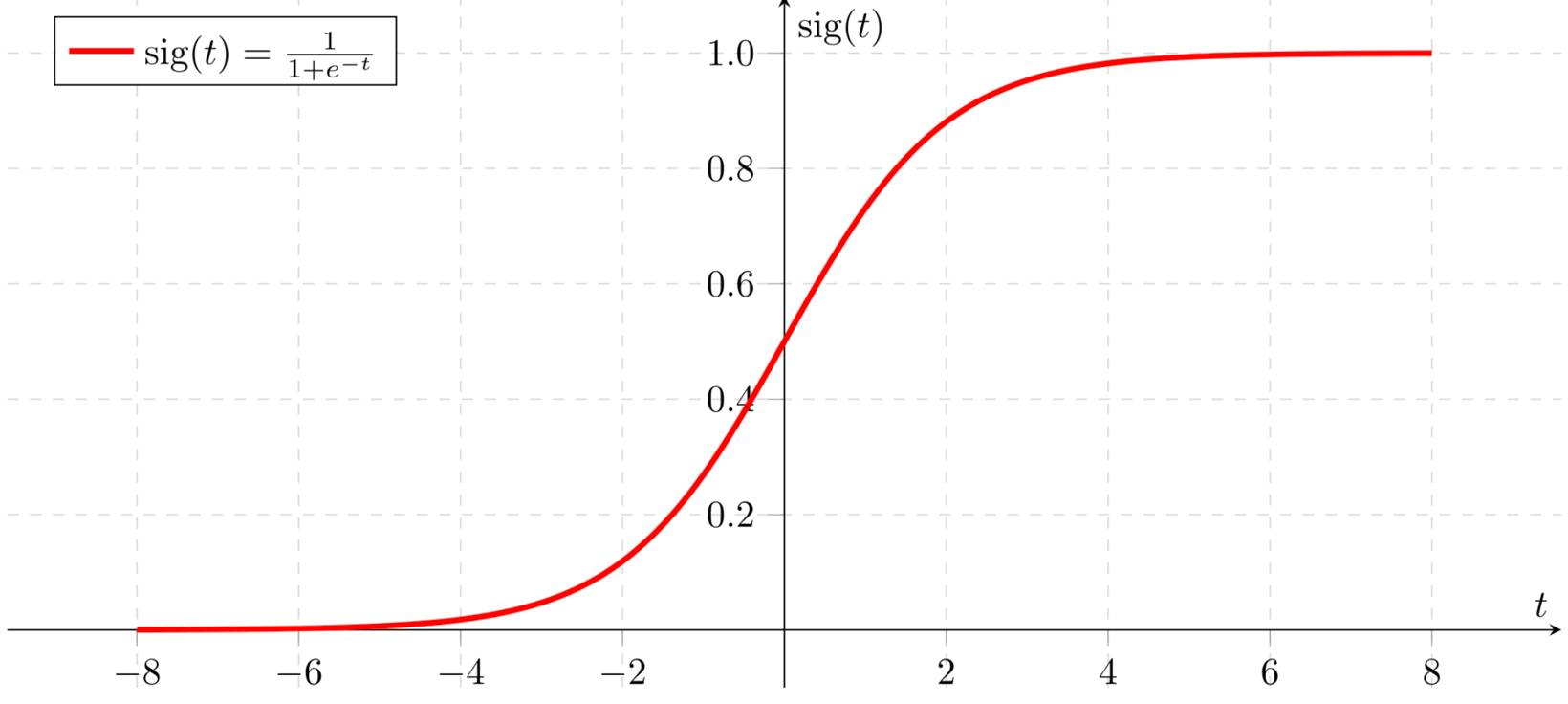
y^ = sig(t)จากการสุ่มค่า Weight ในตอนแรก ค่าจาก Output Node ของ Perceptron จะยังไม่สามารถใช้แก้ปัญหาใดๆ ได้ ดังนั้นเราจะต้องมีการปรับค่า Weight ที่พอนำมาคูณกับ Input Data แล้วทำให้ได้ผลลัพธ์ที่ถูกต้อง (y) ซึ่งเราเรียกผลลัพธ์ที่ถูกต้องที่มีการเตรียมไว้ตั้งแต่ต้นว่า Label Data
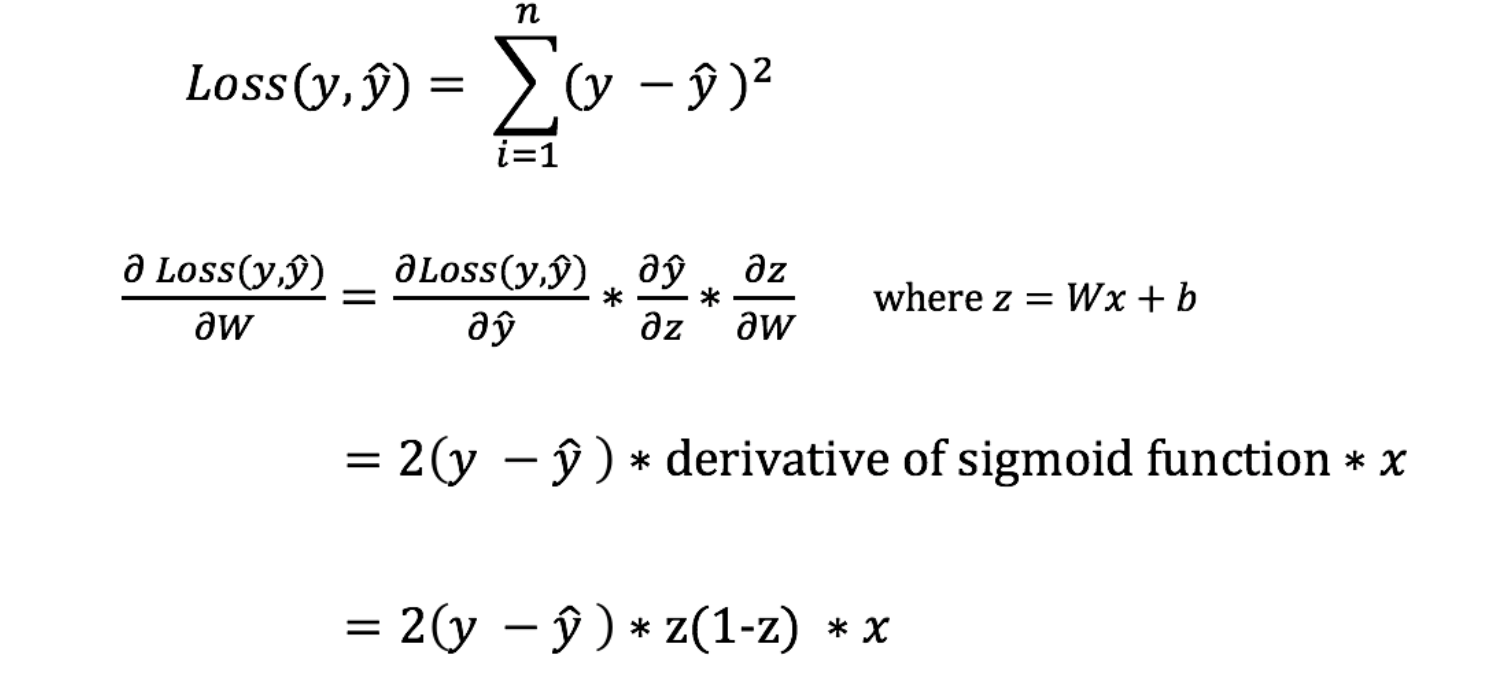
การที่ Model จะรู้ว่าจะต้องปรับค่า Weight เท่าไหร่ที่จะทำให้ได้ผลลัพธ์ที่ถูกต้อง เราจะต้องดูจาก Error หรือดูว่าผลลัพธ์จาก Model หรือ y^ ห่างไกลจากผลลัพธ์ที่ถูกต้อง (y) อย่างไร
ซึ่งเราเรียกฟังก์ชันที่ใช้ในการคำนวณ Error ของ Neural Network ว่า Loss Function โดย Loss Fucntion อย่างง่ายที่อาจจะนำมาใช้กับ Neural Network ที่หลายคนรู้จักก็อย่างเช่น Mean Square Error (MSE) ซึ่งเราจะนำความชันที่เกิดจากการหาอนุพันธ์ของ Loss Function ไปปรับค่า Weight ครับ
นอกจาก Mean Square Error แล้ว ยังมี Loss Function อื่นๆ ให้เลือกใช้งานตามความเหมาะสมอีกหลายฟังก์ชัน เช่น Mean Absolute Error, Categorical Crossentropy และ Binary Crossentropy เป็นต้น
ดังนั้นเพื่อจะให้ได้ผลลัพธ์ที่ถูกต้องมากที่สุด เราจึงต้องมีการปรับค่า Weight หลายๆ ครั้ง แต่นอกจากจำนวนครั้งในการปรับค่า Weight แล้ว วิธีในการปรับก็มีผลต่อความแม่นยำ รวมทั้งความรวดเร็วในการได้ค่า Weight ที่ดีด้วย โดยเราจะกำหนดวิธีปรับค่า Weight ได้โดยการกำหนดตัว Optimizers
Optimizers ที่เรามักจะใช้กันบ่อยๆ ได้แก่ Stochastic Gradient Descent (SGD), Root Mean Square Propagation (RMSprop) และ Adaptive Moment Estimation (Adam)
เพื่อให้เห็นภาพกระบวนการพัฒนา Model ด้วย Deep Learning ได้อย่างรวดเร็ว เราจะเร่ิมต้นเขียน Code โดยใช้ Keras Framework ที่ทำงานบน Tensorflow อีกที ซึ่งผู้อ่านจะได้โฟกัสไปที่แนวคิดสำคัญๆ แทนที่จะลงรายละเอียดมากเกินไปจนมองเห็นภาพรวมได้ยาก
ใน Workshop นี้เราจะพัฒนา Model แบบ Deep Learning (CNN) เพื่อแยกประเภทภาพตัวเลข 0-9 (Image Classification) ที่เขียนด้วยลายมือ จาก MNIST Dataset ซึ่งเป็นภาพตัวเลขแบบ Grayscale จำนวน 70,000 ภาพ ขนาด 28x28 Pixel พร้อมผลเฉลย โดยประกอบด้วยภาพที่จะใช้ในการ Train จำนวน 60,000 ภาพ และภาพที่ใช้ในการ Test จำนวน 10,000 ภาพ

ซึ่งกระบวนการพัฒนา Model จะประกอบไปด้วย
- Data Preparation
- Define Model
- Compile
- Fit (Train)
- Save
- Load
- Prediction
- Evaluation
แต่ก่อนจะทำ Data Preparation เราจะสร้าง Notebook และ Import Package ที่จำเป็น ตามขั้นตอนดังนี้
- ในกรณีที่ใช้จากเครื่อง Computer ของตนเองที่ได้สร้าง environment ไว้จากบทที่แล้ว ให้ใช้คำสั่ง conda activate deep_workshop1
conda activate deep_workshop1- จากนั้น ไปเข้าไปที่ Folder ของ Project ชื่อ deepbasic_pj
cd deepbasic_pj- เปิด Jupyter Notebook โดยใช้คำสั่ง jupyter notebook
jupyter notebook- สร้าง Notebook ใหม่ กดที่ Untitled พิมพ์ชื่อไฟล์ที่ต้องการจะ Save เป็น first_cnn แล้วกด Rename
NVIDIA GPU
สำหรับการ Train Model บน NVIDIA GPU ซึ่งมีการติดตั้ง CUDA Toolkit และ cuDNN Library รวมทั้ง Tensorflow 2.4 บน Windows แล้ว ให้เพิ่ม Code ต่อไปนี้ที่ต้นโปรแกรม เพื่อทดสอบการใช้งาน GPU
- แสดงรุ่นของ NVIDIA GPU ด้วยคำสั่ง nvidia-smi
!nvidia-smi -L
- Import Library ที่ต้องใช้ และแสดง Version ของ Tensorflow
import tensorflow as tf
import tensorflow.python.platform.build_info as build
tf.__version__
- แสดงจำนวน GPU และชื่อ Device
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
print(f'Default GPU Device:{tf.test.gpu_device_name()}')
- แสดง Version ของ CUDA และ cuDNN
print(build.build_info['cuda_version'])
print(build.build_info['cudnn_version'])
Apple M1 GPU
สำหรับการ Train Model บน Apple M1 GPU ซึ่งติดตั้ง TensorFlow เวอร์ชัน Fork แล้ว ให้เพิ่ม Code ต่อไปนี้ที่ต้นโปรแกรม เพื่อให้สามารถใช้งาน GPU ได้
- Import Library ที่ต้องใช้ และแสดง Version ของ Tensorflow
import tensorflow as tf
from tensorflow.python.compiler.mlcompute import mlcompute
from tensorflow.python.framework.ops import disable_eager_execution
tf.__version__
- ตรวจสอบการทำงานของ TensorFlow กับ Apple ML Compute
mlcompute.is_apple_mlc_enabled()
mlcompute.is_tf_compiled_with_apple_mlc()
- Disable TensorFlow ในโหมด Eager Execution ที่ทำให้รันทีละคำสั่งได้เหมือนการรันโปรแกรมปกติ
disable_eager_execution()
tf.executing_eagerly()
- Config ให้ Train Model บน M1 GPU
mlcompute.set_mlc_device(device_name='gpu')Non GPU
- Import Tensorflow
import tensorflow as tfTry it out
import time
import numpy as np
import matplotlib.pyplot as plt
import plotly
import plotly.graph_objs as go
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
import pickle as p
to_categorical = tf.keras.utils.to_categorical
mnist = tf.keras.datasets.mnist
load_model = tf.keras.models.load_model
model_from_json = tf.keras.models.model_from_json
- ถ้าพบว่าเรายังไม่ได้ติดตั้ง Library อย่างเช่น plotly ให้พิมพ์คำสั่ง pip install ใน Cell ถัดไป เพื่อติดตั้ง Library
pip install plotly- กลับไปที่ Cell ก่อนหน้า แล้วกด Shift+Enter เพื่อรันโปรแกรมอีกครั้ง
- Comment Code การติดตั้ง แล้วกด Shift+Enter
# pip install plotlyData Preparation
- กำหนดรูปแบบ Cell เป็น Heading แล้วกด OK เพื่อเขียนคำอธิบาย "Data Preparation" ดังภาพด้านล่าง แล้วกด Shift+Enter

- พิมพ์ Code ตามตัวอย่าง แล้วกด Shift+Enter
batch_size = 128
num_classes = 10
epochs = 5
img_rows, img_cols = 28, 28จาก Code เราได้กำหนดค่าตัวแปรต่างๆ ได้แก่
batch_size ที่เปรียบได้กับจำนวนเม็ดข้าวที่จะตักใน 1 ช้อน สำหรับนำเข้า Model
num_classes คือ จำนวน Output Node ของ Neural Network หรือจำนวน Class ที่ Model จะทำนาย ได้แก่ Class 0 จนถึง Class 9
epochs คือ จำนวนรอบที่จะ Train Model โดยใน 1 รอบ หรือ 1 epoch เปรียบได้ว่า จะมีการตักข้าวช้อนละ 128 เม็ด จำนวน 469 ช้อน จากจานขนาดใหญ่ที่มีข้าวทั้งหมด 60,000 เม็ด
img_rows, img_cols คือ ความสูง และความกว้างของภาพที่นำเข้า Model
- Download MNIST Dataset โดยพิมพ์ Code ตามตัวอย่าง แล้วกด Shift+Enter
(x_train, y_train), (x_test, y_test) = mnist.load_data()- แสดงมิติของ Dataset
print(x_train.shape, x_test.shape)
- แสดงผลเฉลย
y_train[0:10]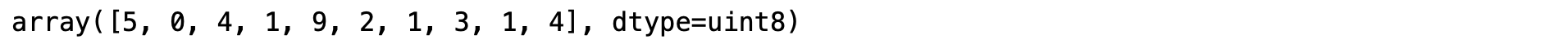
จาก Code เราได้ Download ภาพจาก MNIST Dataset ซึ่งประกอบด้วย Data ที่จะใช้ในการ Train จำนวน 60,000 ภาพ และ Data ที่ใช้ในการ Test จำนวน 10,000 ภาพ พร้อมผลเฉลยที่เป็นตัวเลข 0-9
- แสดงภาพจาก Train Dataset โดยพิมพ์ Code ตามตัวอย่าง แล้วกด Shift+Enter
plt.figure(figsize=(5, 4))
for i in range(20):
plt.subplot(4, 5, i+1)
plt.imshow(x_train[i], cmap='gray')
plt.xticks([])
plt.yticks([])
plt.tight_layout()
plt.savefig('train_mnist.png', dpi=300)
- แสดงค่าต่ำสุด-สุงสุด ของ Pixel ของภาพ
x_train.min(), x_train.max()
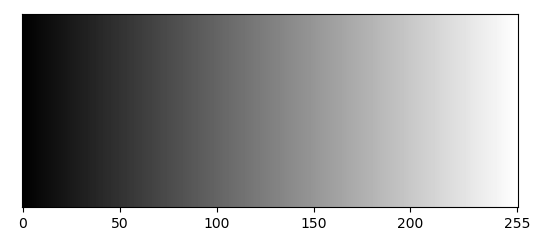
จากภาพด้านบนจะแสดงภาพตัวเลขแบบ Grayscale ทั้งหมด 20 ภาพ ที่เรียงตามลำดับใน Train Dataset โดยแต่ละ Pixel ของภาพแบบ Grayscale จะมีค่าความแข้มของสีดำตั้งแต่ 0-255 เรียงลำดับความเข้มจากมากไปน้อย โดยสีดำมีค่าเท่ากับ 0 และสีขาวมีค่าเท่ากับ 255
- พิมพ์ Code ตามตัวอย่าง แล้วกด Shift+Enter
temp_x_test = x_test
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
print(x_train.min(), x_train.max())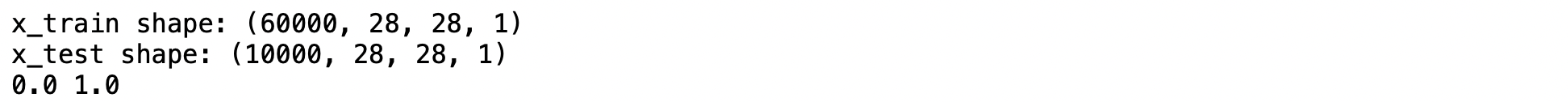
เพื่อจะนำภาพลายมือแบบ Grayscale เข้า Model เราจะต้องเปลี่ยน Dimension ของ Dataset สำหรับการ Train และ Test จาก 60,000 x 28 x 28 และ 10,000 x 28 x 28 เป็น 60,000 x 28 x 28 x 1 และ 10,000 x 28 x 28 x 1 ตามลำดับ โดยตัวเลขในมิติที่ 2-4 (28 x 28 x 1) เป็นค่าที่เราจะต้องกำหนดตอนนิยาม Model (input_shape) เพื่อให้ CNN มอง Input Data เป็นภาพขนาด 28 x 28 แบบ 1 Channel (Grayscale) แต่ถ้าเราส่ง Input Data ที่เป็นภาพสี เราจะต้องนิยาม Model เพื่อให้ CNN มอง Input Data เป็นภาพขนาด 28 x 28 แบบ 3 Channel ในระบบสีแบบ RGB แทนครับ
ถึงแม้ว่าเราจะสามารถนำภาพแบบ Grayscale ที่มีค่าของ Pixel เป็นจำนวนเต็มระหว่าง 0-255 เข้า Model ได้โดยตรง แต่ก็อาจทำให้ Train Model ได้ช้า รวมทั้งอาจส่งผลต่อประสิทธิภาพในการทำนาย ดังนั้นเราจึงต้องมีการทำ Scaling เพื่อปรับค่าของ Pixel เป็นตัวเลขทศนิยม ซึ่งเราจะใช้เทคนิคพื้นฐานในการทำ Scaling ให้มีค่าระหว่าง 0-1 โดยการหารด้วย 255
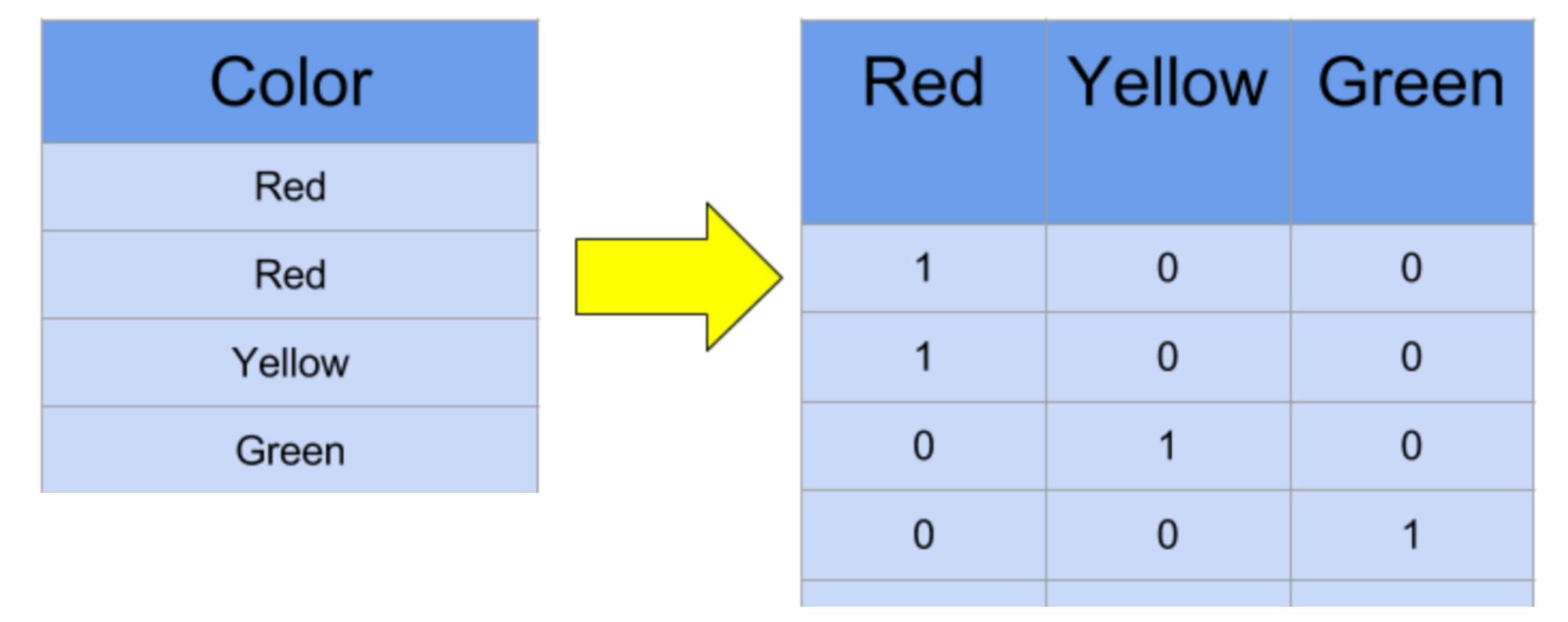
- เข้ารหัสผลเฉลยแบบ One Hot
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)นอกจากนี้เราจะเข้ารหัสผลเฉลย จากตัวเลข 0-9 ให้อยู่ในรูปของ One Hot Encoder ที่จะมีจำนวนตัวเลข 0 และ 1 รวมกันเท่ากับจำนวนของ Class โดยตำแหน่งที่เป็นตัวแทนขอผลเฉลยจะถูกเซ็ตเป็น 1 ขณะที่ตำแหน่งอื่นจะถูกเซ็ตเป็น 0 ซึ่งการเข้ารหัสผลเฉลยให้มีค่าเป็น 0 และ 1 จะทำให้ลดอิทธิพลในการปรับค่า Weight จากตัวเลข 0-9 ได้ครับ
Define model
- กำหนดรูปแบบ Cell เป็น Heading แล้วกด OK เพื่อเขียนคำอธิบาย ดังภาพด้านล่าง กด Shift+Enter แล้วพิมพ์ Code ตามตัวอย่างเพื่อนิยาม CNN Model แล้วกด Shift+Enter
#Feature Extraction
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
#Image Classification
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(num_classes, activation='softmax'))ซึ่งโดยปกติโครงสร้างของ CNN Model จะมี 2 ส่วน คือ Feature Extraction และ Image Classification
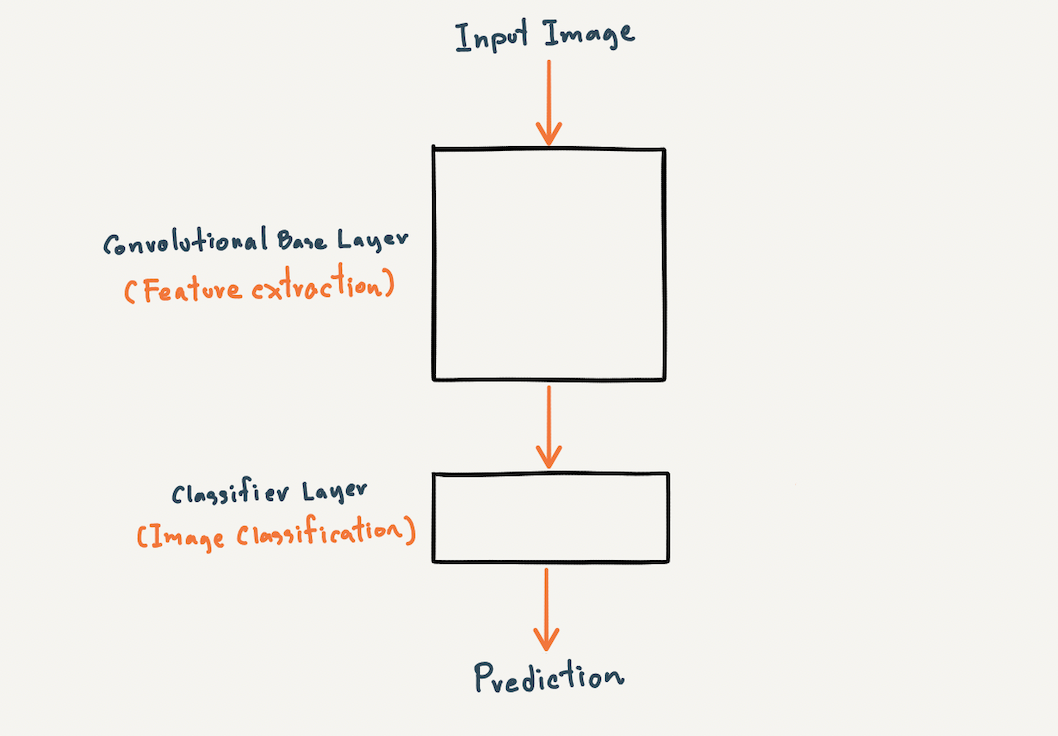
Feature Extraction เป็นส่วนที่มีหน้าที่ในการสกัด Feature ของภาพ
Image Classification เป็นส่วนที่มีหน้าที่ในการแยกประเภทภาพ
ดังนั้นเราจึงนิยาม CNN Model โดยมี input_shape เท่ากับ 28 x 28 x 1 และ Output Node เท่ากับ 10 Node (num_classes เท่ากับ 10) โดยมีส่วนของ Feature Extraction และ Image Classification ดังภาพด้านบน
Compile
- พิมพ์ Code ตามตัวอย่าง เพื่อ Compile สำหรับเริ่มต้นใช้ categorical_crossentropy Loss Function และ adam Optimizer แล้วกด Shift+Enter แล้วดูชนิดของ Layer, Output Shape และจำนวน Parameter (จำนวนตัวแปรที่เก็บค่า Weight และ Bias ของ Model)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()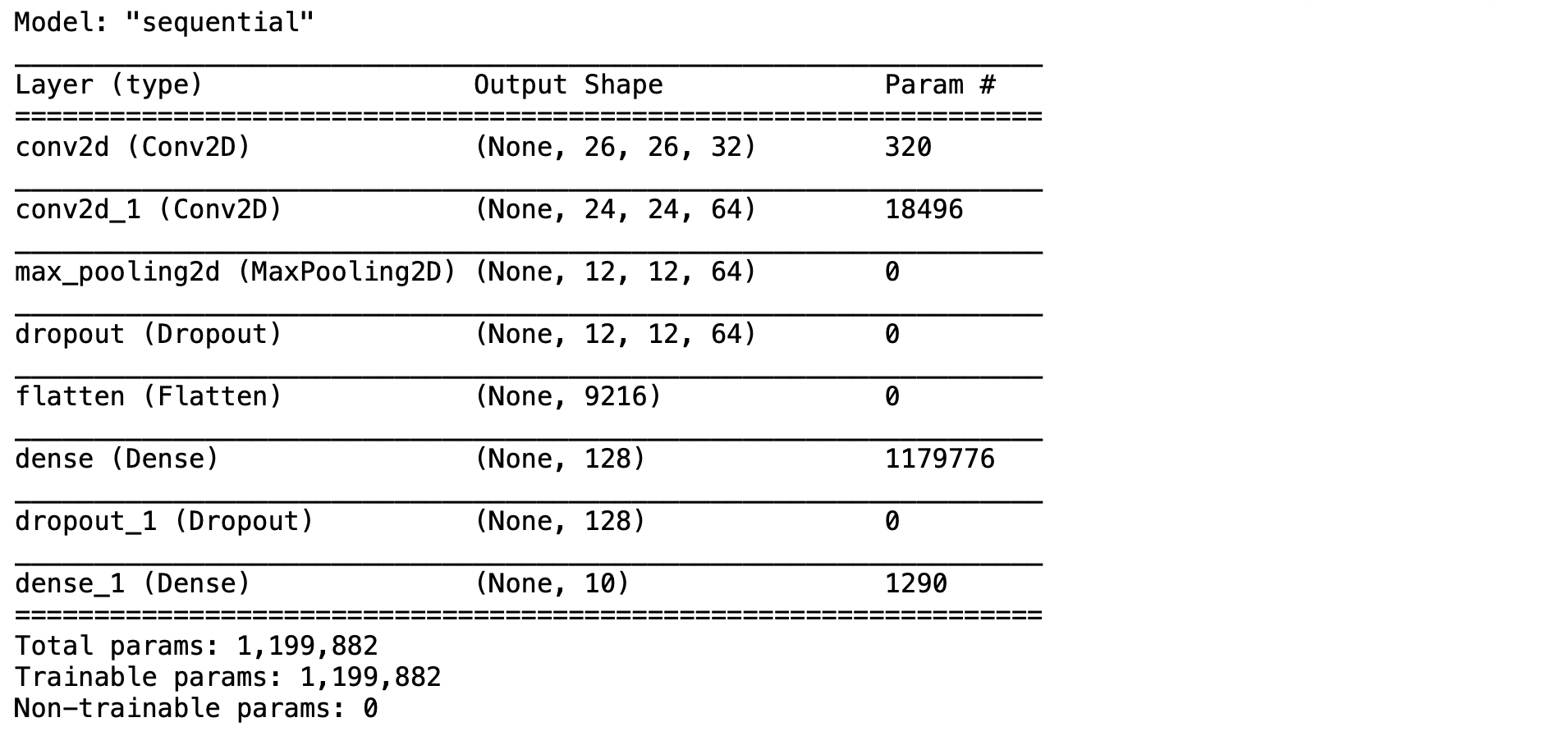
Fit (Train)
- พิมพ์ Code ตามตัวอย่าง เพื่อ Train Model แล้วกด Shift+Enter
start = time.time()
his = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
done = time.time()
print(done - start)
จากภาพ ในแต่ละ Epoch ของการ Train จะใช้เวลาประมาณ 21 วินาที ในแต่ละรอบเราจะเห็นค่า loss และ accuracy ที่เกิดจากข้อมูล Train และค่า val_loss และ val_accuracy จากข้อมูล Test โดยค่าเหล่านี้ คือ History ที่เรานำมาเก็บไว้ในตัวแปร his
Save
- Save History
filepath_history_model = 'history_model'
with open(filepath_history_model, 'wb') as file:
p.dump(his.history, file)- Save Model แบบรวม Structure และ Weight ในไฟล์เดียวกัน
filepath='model.h5'
model.save(filepath)- Save Model แบบแยก Structure (JSON Format) และ Weight
filepath_model = 'model.json'
filepath_weights = 'weights_model.h5'
model_json = model.to_json()
with open(filepath_model, "w") as json_file:
json_file.write(model_json)
model.save_weights(filepath_weights)โดยไฟล์ model.h5 ที่มีการ Save แบบรวม Structure และ Weight จะมีขนาดใหญ่กว่าไฟล์ model.json และ weights_model.h5 รวมกันครับ
Load
- Load History
with open(filepath_history_model, 'rb') as file:
his = p.load(file)Plot Loss
h1 = go.Scatter(y=his['loss'],
mode="lines", line=dict(
width=2,
color='blue'),
name="loss"
)
h2 = go.Scatter(y=his['val_loss'],
mode="lines", line=dict(
width=2,
color='red'),
name="val_loss"
)
data = [h1,h2]
layout1 = go.Layout(title='Loss',
xaxis=dict(title='epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data, layout=layout1)
plotly.offline.iplot(fig1, filename="testMNIST")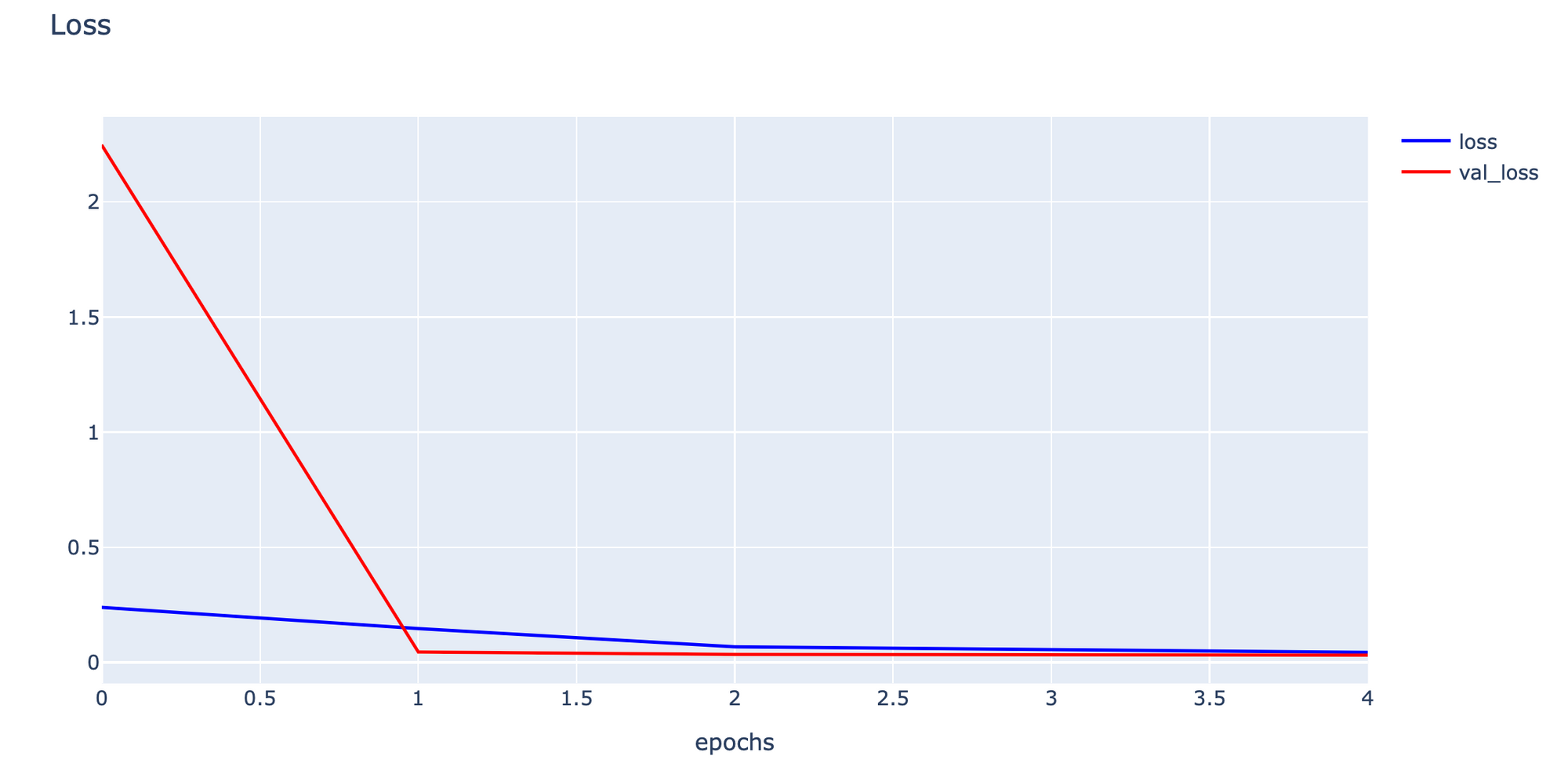
- Load Model แบบไฟล์เดียว
predict_model = load_model(filepath)
predict_model.summary()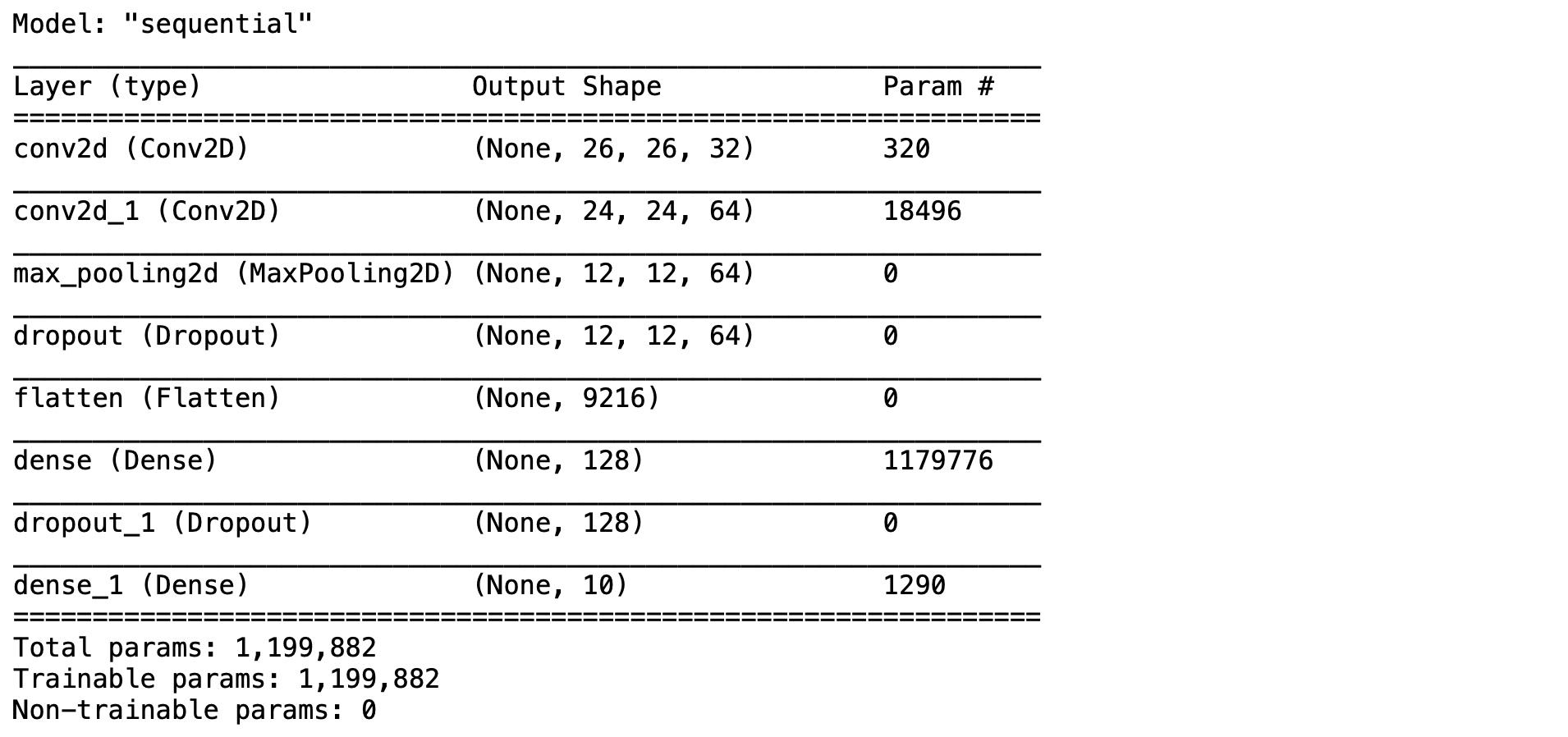
- Load Model แบบแยก Structure (JSON Format) และ Weight แล้ว Compile Model ใหม่
with open(filepath_model, 'r') as f:
loaded_model_json = f.read()
predict_model = model_from_json(loaded_model_json)
predict_model.load_weights(filepath_weights) predict_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
predict_model.summary()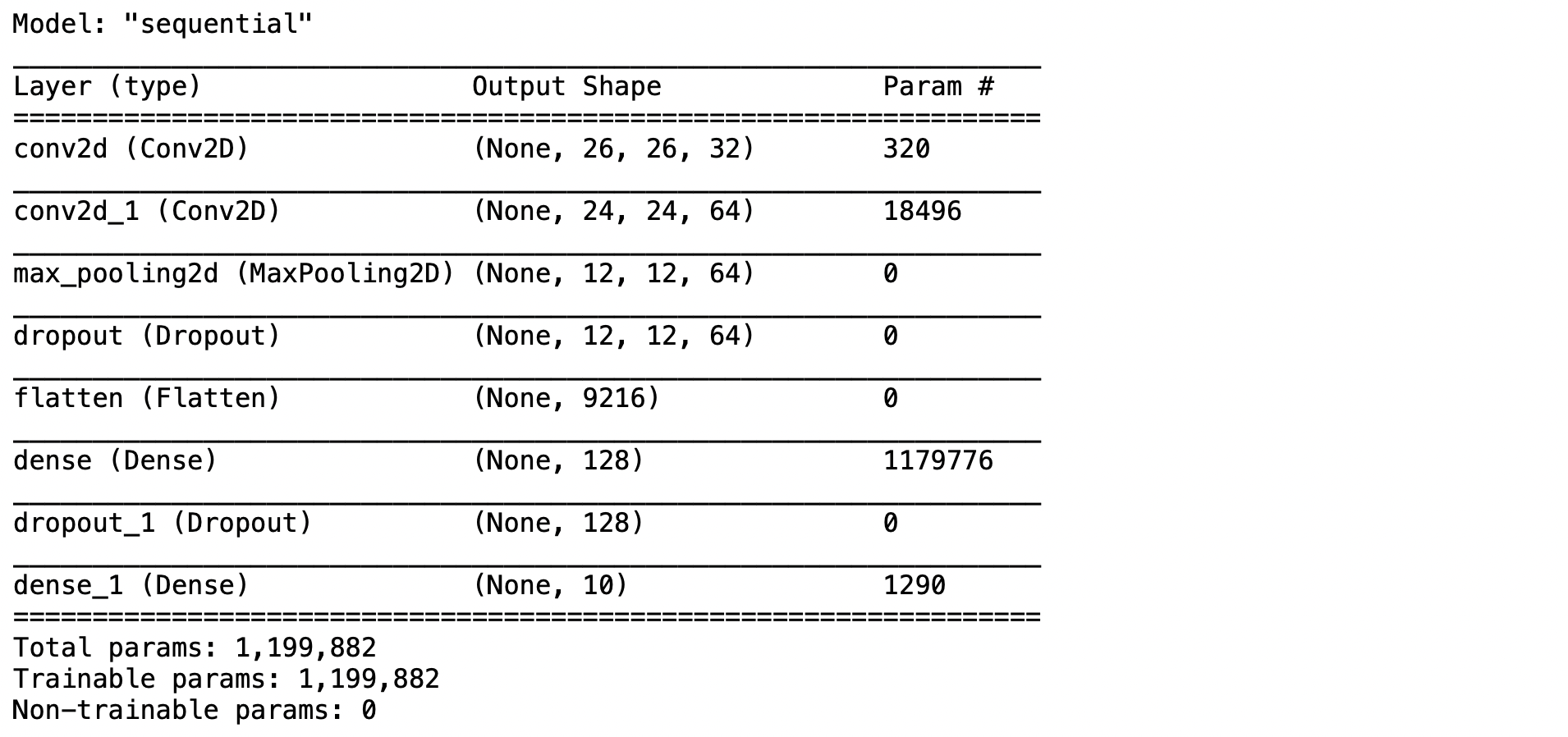
หมายเหตุ ผู้อ่านสามารถเลือกวิธีการ Load Model แบบรวมหรือแยก Structure และ Weight ได้ตามความเหมาะสม
Prediction
- แสดงภาพจาก Test Dataset
plt.figure(figsize=(5, 4))
for i in range(20):
plt.subplot(4, 5, i+1)
plt.imshow(temp_x_test[i], cmap='gray')
plt.xticks([])
plt.yticks([])
plt.tight_layout()
plt.savefig('test_mnist.png', dpi=300)
- Predict ภาพแรกใน Test Dataset
result = predict_model.predict(x_test[:1])
result = np.argmax(result, axis=-1)
print(result)
Evaluation
- Evaluvate Model จาก Test Dataset
score = predict_model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
- เตรียม predicted_classes และ y_true เพื่อแสดง Confuse Matrix, Precision, Recall, F1-score
predicted_classes = predict_model.predict(x_test)
predicted_classes = np.argmax(predicted_classes,axis=-1)y_true = np.argmax(y_test, axis=-1)correct = np.nonzero(predicted_classes==y_true)[0]
incorrect = np.nonzero(predicted_classes!=y_true)[0]
print("Correct predicted classes:",correct.shape[0])
print("Incorrect predicted classes:",incorrect.shape[0])
- แสดง Confuse Matrix
confusion_matrix(y_true, predicted_classes)
- แสดง Precision, Recall, F1-score, support, accuracy, macro avg และ weighted avg
labels = {0 : "Zero", 1: "One", 2: "Two", 3: "Three", 4: "Four",
5: "Five", 6: "Six", 7: "Seven", 8: "Eight", 9: "Nine"}
target_names = ["Class {} ({}) :".format(i,labels[i]) for i in range(num_classes)]
print(classification_report(y_true, predicted_classes, target_names=target_names, digits=4))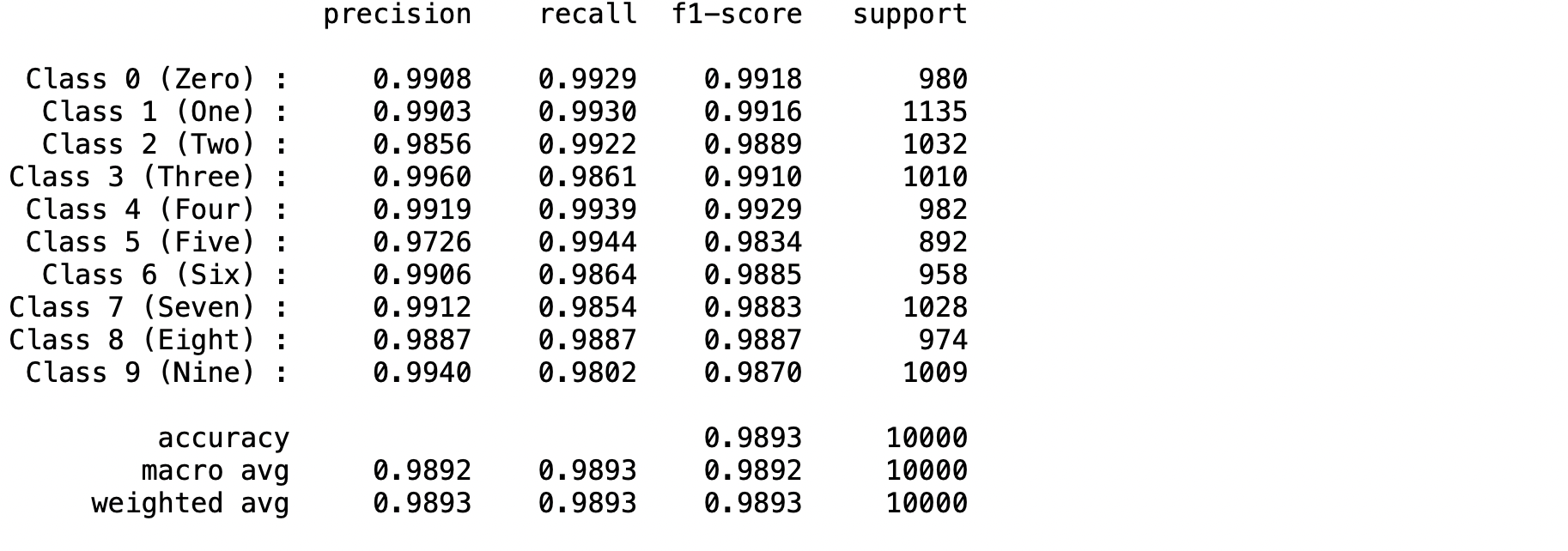

หมายเหตุ
F1-score คือค่าเฉลี่ยฮาร์โมนิก (Harmonic Mean)
N/Σ(1/X)สรุป
ในบทความนี้ผู้อ่านได้เข้าใจ Neural Network 3 ประเภท ได้แก่ Perceptron, CNN และ RNN หน้าที่ของ Activate Function, Loss Function และ Optimizer รวมทั้งการทำ Workshop เพื่อแยกประเภทภาพตัวเลข 0-9 จาก MNIST Dataset โดยใช้ Model แบบ Deep Learning (CNN) ซึ่งมีกระบวนการพัฒนา Model ได้แก่
- Data Preparation
- Define Model
- Compile
- Fit (Train)
- Save
- Load
- Prediction
- Evaluation
Bonus
หากต้องการอ่าน Dataset ใน path หรือเครื่องของตนเอง สามารถดูตัวอย่างได้จาก How to Load Large Datasets From Directories for Deep Learning in Keras หรือ Detecting Pneumonia in Chest X-Ray Images Using Deep Learning Models on Google Colab Pro