A Book Recommendation Example: Collaborative Filtering using Autoencoder Model


บทความโดย ผศ.ดร.ณัฐโชติ พรหมฤทธิ์
ภาควิชาคอมพิวเตอร์
คณะวิทยาศาสตร์
มหาวิทยาลัยศิลปากร
Collaborative Filtering เป็นเทคนิคหนึ่งที่ใช้ในการทำ Recommendation โดยอาศัยข้อมูลความพึงพอใจของ User ที่มีต่อ Item ต่างๆ อย่างเช่น การให้คะแนนความชอบในหนังสือแต่ละเล่ม การ Comment ภาพยนตร์แต่ละเรื่อง หรือการกด Like เพลงแต่ละเพลง เพื่อหาค่าความคล้ายคลึงของ User (Similar Users) โดยระบบจะแนะนำ Item (หนังสือ ภาพยนตร์ หรือเพลง ฯลฯ) แบบที่ User คนหนึ่งชื่นชอบ แก่ User อีกคนที่มีความคล้ายคลึงกัน
อย่างไรก็ตาม สิ่งสำคัญประการหนึ่งที่จะทำให้การทำ Recommendation ด้วยเทคนิค Collaborative Filtering ประสบความสำเร็จ คือ จะต้องมีจำนวน User ที่มีปฏิสัมพัน (Rating, Comment, กด Like ฯลฯ) กับ Item ต่างๆ ที่มากพอ
ในบทความนี้ผู้เขียนจะยกตัวอย่างการทำ Book Recommendation โดยใช้ข้อมูลการให้คะแนนหนังสือจาก Book-Crossing Dataset ซึ่งมีการแยกเก็บข้อมูล User, Book และ Book Ratings เป็นไฟล์ *.csv ทั้งหมด 3 ไฟล์ และใช้ Autoencoder Model เพื่อเรียนรู้ และทำนายคะแนนความชื่นชอบในหนังสือแต่ละเล่ม เพื่อจะแนะนำหนังสือที่มีคะแนนสูงสุด 10 อันดับให้แก่ User แต่ละคน
Data Preparation
Filter Data with Threshold
นอกจากจะต้องมีจำนวน User ที่มีการให้คะแนนหนังสือที่มากพอสำหรับการ Train Model แล้ว หนังสือแต่ละเล่มจะต้องมี User มา Review เป็นจำนวนหนึ่ง เพื่อให้ระบบสามารถแนะนำหนังสือได้ตรงกับความต้องการของ User มากที่สุด ซึ่งในการทดลอง เราจะกำหนดค่า Threshold เพื่อคัดกรองข้อมูลก่อนจะ Train Model ดังนี้
User แต่ละคนจะต้องมีการให้คะแนนหนังสือไม่น้อยกว่า 20 ครั้ง
หนังสือแต่ละเล่มจะต้องมี User มา Review ไม่น้อยกว่า 20 ครั้ง
หลักๆ ผู้เขียนจะใช้ภาษา SQL ร่วมกับ Pandas ในการ Query และ Tranform คะแนนการ Review หนังสือของ User แต่ละคนไปเป็น Matrix ขนาด M x N โดย M คือ จำนวน User และ N คือ จำนวนหนังสือ
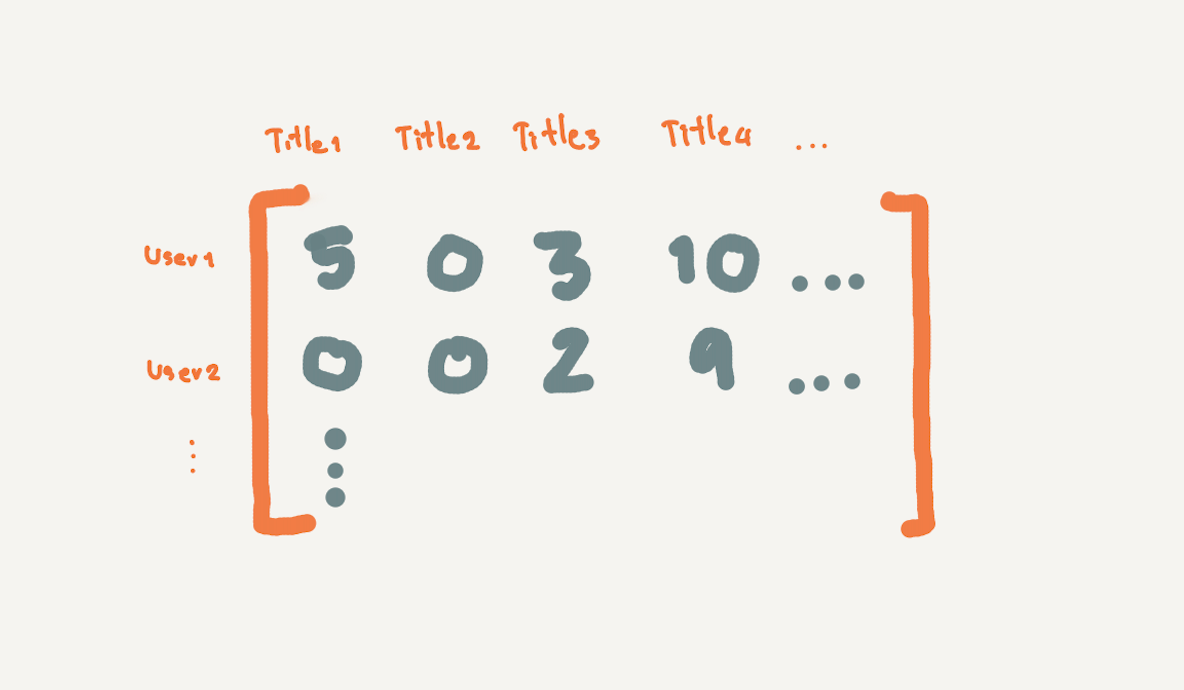
โดยมีขั้นตอนในการเตรียมข้อมูล ดังนี้
1) ติดตั้ง Library ที่จำเป็น
import numpy as np
import pandas as pd
import tensorflow as tf
ModelCheckpoint = tf.keras.callbacks.ModelCheckpoint
load_model = tf.keras.models.load_model
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import sqlite3
import plotly.express as px
import plotly
import plotly.graph_objs as go
import warnings
warnings.filterwarnings('ignore')2) Read CSV File
อ่านข้อมูล Book Ratings, User และ Book จากไฟล์ *.csv โดยกำหนดการเข้ารหัสแบบ "latin-1" ซึ่งคะแนนของ User จะมีค่าในช่วงตั้งแต่ 0 จนถึง 10
rating = pd.read_csv('BX-Book-Ratings.csv', sep=';', encoding="latin-1", on_bad_lines='skip')
print(rating.shape)
rating.head()(1149780, 3)

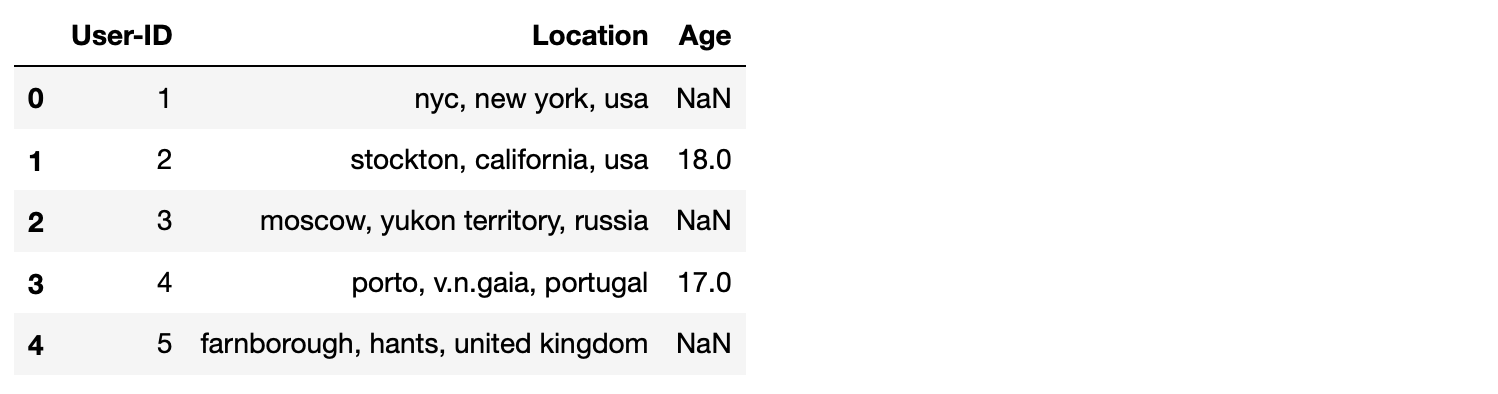
user = pd.read_csv('BX-Users.csv', sep=';', encoding="latin-1")
print(user.shape)
user.head()(278858, 3)
book = pd.read_csv('BX_Books.csv', sep=';', on_bad_lines='skip', encoding="latin-1")
print(book.shape)
book.head()(271360, 8)

3) Connect SQLite Database Engine เพื่อสร้าง Table ใหม่
Connect และสร้าง SQLite Database ขึ้นมาใหม่ โดยบันทึกข้อมูลลงในไฟล์ "book_rec.db"
connect = sqlite3.connect('book_rec.db')4) สร้าง Table book, user และ rating ใน SQLite Database ด้วยการ Import ข้อมูลจาก Dataframe
book.to_sql("book", connect, if_exists='fail')
user.to_sql("user", connect, if_exists='fail')
rating.to_sql("rating", connect, if_exists='fail')5) ติดตั้ง และ Load ipython-sql Library เพื่อจัดการ SQLite Database ด้วย Magic Command
ติดตั้ง ipython-sql ด้วยคำสั่ง pip install
pip install ipython-sqlLoad ipython-sql
%load_ext sql6) Connect SQLite Database Engine เพื่อจัดการกับ Database ด้วย Magic Command
%sql sqlite:///book_rec.db7) Check ข้อมูลใน Table rating, book และ user
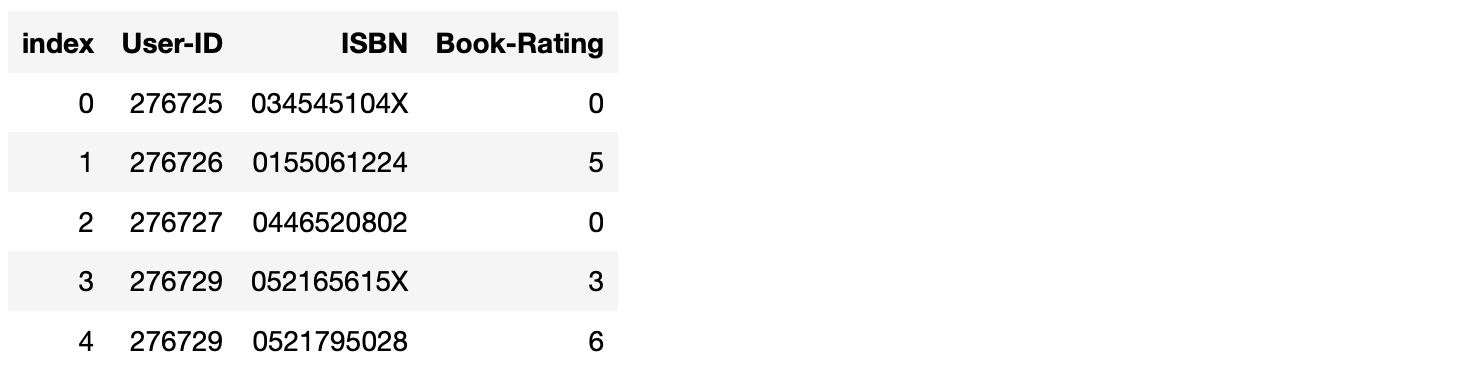
%sql SELECT * FROM rating LIMIT 5* sqlite:///book_rec.db
Done.
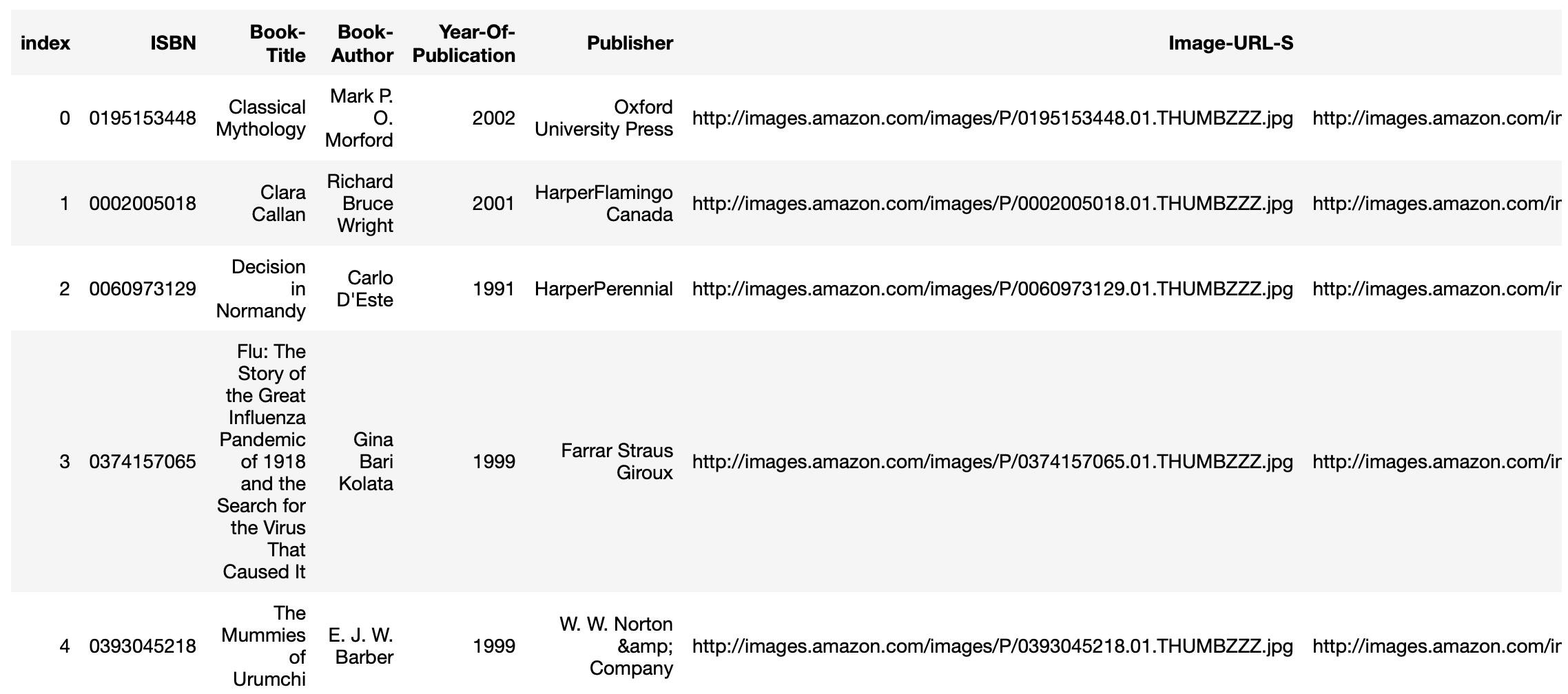
%sql SELECT * FROM book LIMIT 5* sqlite:///book_rec.db
Done.
%sql SELECT * FROM user LIMIT 5* sqlite:///book_rec.db
Done.

8) Merge Table rating กับ Table book
rating เป็น Table ที่จะนำข้อมูลไปแปลงเป็น Matrix เพื่อ Train Model โดยเราต้องการสร้าง Book Title เป็นอีกหนึ่ง Attribute ของ Table rating_book นอกเหนือจาก Attribute จาก Table rating ดังนั้นจึงต้องมีการ Joint Table rating กับ Table book ด้วย Attribute ISBN แบบ INNER JOIN ซึ่งเราไม่ต้องการให้ Attribute Book Title ใหม่ มีค่าเป็น Null เพราะไม่มีหมายเลข ISBN ใน Table book
%%sql
CREATE TABLE rating_book AS SELECT rating."User-ID" AS UserID , rating.ISBN, rating."Book-Rating" AS BookRating, book."Book-Title" AS BookTitle
FROM rating
INNER JOIN book
ON rating.ISBN = book.ISBN* sqlite:///book_rec.db
Done.
[]
Check ข้อมูลใน Table rating_book
%%sql
SELECT * FROM rating_book LIMIT 5* sqlite:///book_rec.db
Done.

ซึ่งพบว่า Table rating_book จะมีจำนวน Record ทั้งหมด 1,031,136 Record
%%sql
SELECT count(*) FROM rating_book* sqlite:///book_rec.db
Done.

9) นับจำนวนครั้งที่หนังสือแต่ละเล่มถูกให้คะแนน
เพื่อจะคัดกรองเฉพาะหนังสือที่มี User มา Review ไม่น้อยกว่า 20 ครั้ง เราจึงต้องนับจำนวนครั้งที่หนังสือแต่ละเล่มจะถูก Review ด้วยคำสั่ง GROUP BY โดยจะบันทึกข้อมูลการนับลงใน Table rating_count
%%sql
CREATE TABLE rating_count AS SELECT "BookTitle", count(*) as RatingCountBook FROM rating_book GROUP BY "BookTitle"* sqlite:///book_rec.db
Done.
[]
Check ข้อมูลใน Table rating_count
%%sql
SELECT * from rating_count limit 5* sqlite:///book_rec.db
Done.

ซึ่งพบว่า Table rating_count จะมีจำนวน Record ทั้งหมด 241,071 Record
%%sql
SELECT count(*) FROM rating_count* sqlite:///book_rec.db
Done.

10) คัดกรองหนังสือที่มี User มา Review ไม่น้อยกว่า 20 ครั้ง และบันทึกข้อมูลลงใน Table rating_count_filter
rating_coun_threshold = 20%%sql
CREATE TABLE rating_count_filter AS SELECT * FROM rating_count WHERE RatingCountBook >= :rating_coun_threshold* sqlite:///book_rec.db
Done.
[]
Check ข้อมูลใน Table rating_count_filter
%%sql
SELECT * FROM rating_count_filter LIMIT 5* sqlite:///book_rec.db
Done.
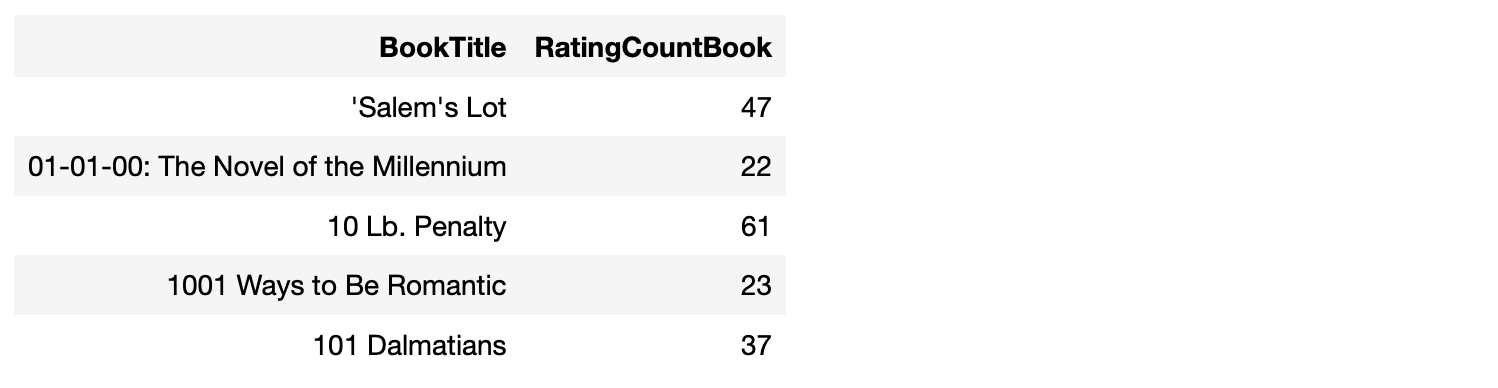
ซึ่งพบว่า Table rating_count_filter จะมีจำนวน Record ทั้งหมด 7,608 Record
%%sql
SELECT count(*) FROM rating_count_filter* sqlite:///book_rec.db
Done.

11) เลือกข้อมูลการ Review ของ User ในตาราง rating_book เฉพาะหนังสือที่มี User มา Review ไม่น้อยกว่า 20 ครั้ง และบันทึกข้อมูลลงใน Table user_rating และเพิ่ม RattingCountBook ของหนังสือเป็น Attribute หนึ่งใน Table user_rating ด้วย
%%sql
CREATE TABLE user_rating AS
SELECT rating_book.UserID, rating_book.ISBN, rating_book.BookRating, rating_book.BookTitle, rating_count_filter.RatingCountBook
FROM rating_book
INNER JOIN rating_count_filter
ON rating_book.BookTitle = rating_count_filter.BookTitle* sqlite:///book_rec.db
Done.
[]
Check ข้อมูลใน Table user_rating
%%sql
SELECT * FROM user_rating LIMIT 5* sqlite:///book_rec.db
Done.
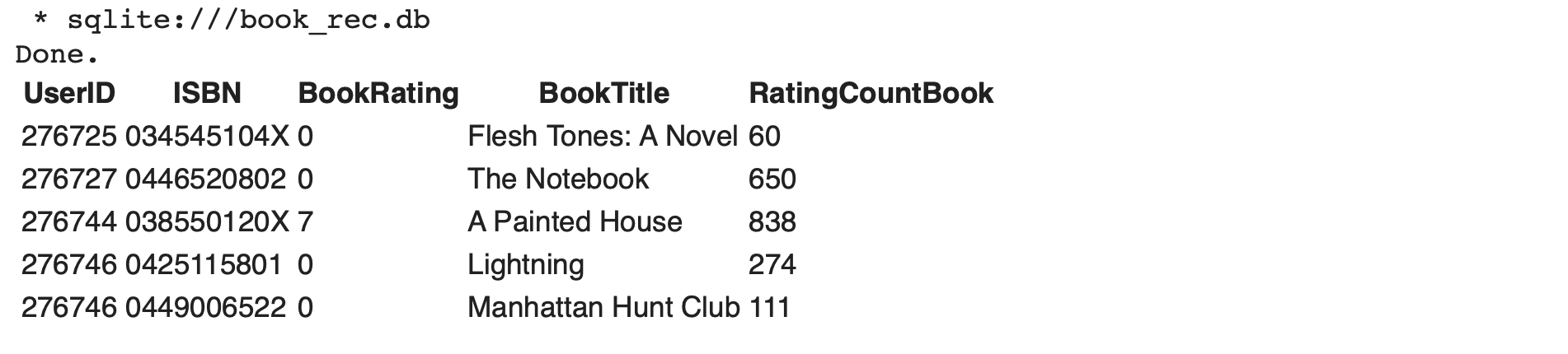
ซึ่งพบว่า Table user_rating จะมีจำนวน Record ทั้งหมด 442,253 Record
%%sql
SELECT count(*) FROM user_rating* sqlite:///book_rec.db
Done.

12) นับจำนวนครั้งในการ Review หนังสือของ User ใน Table user_rating และบันทึกข้อมูลลงใน Table user_count
%%sql
CREATE TABLE user_count AS SELECT UserID, count(*) as RatingCountUser FROM user_rating GROUP BY UserID* sqlite:///book_rec.db
Done.
[]
Check ข้อมูลใน Table user_count
%%sql
SELECT * FROM user_count LIMIT 5* sqlite:///book_rec.db
Done.

ซึ่งพบว่า Table user_count จะมีจำนวน Record ทั้งหมด 60,046 Record
%%sql
SELECT count(*) FROM user_count* sqlite:///book_rec.db
Done.

13) คัดกรอง User ที่ Review หนังสือ ไม่น้อยกว่า 20 ครั้ง และบันทึกข้อมูลลงใน Table user_count_filter
user_count_filter_threshold = 20%%sql
CREATE TABLE user_count_filter AS SELECT * FROM user_count WHERE RatingCountUser >= :user_count_filter_threshold* sqlite:///book_rec.db
Done.
[]
Check ข้อมูลใน Table user_count_filter
%%sql
SELECT * FROM user_count_filter LIMIT 5* sqlite:///book_rec.db
Done.

ซึ่งพบว่า Table user_count_filter จะมีจำนวน Record ทั้งหมด 3,426 Record
%%sql
SELECT count(*) FROM user_count_filter* sqlite:///book_rec.db
Done.

14) เลือกข้อมูลการ Review ของ User ในตาราง user_rating เฉพาะของ User ที่ Review หนังสือ ไม่น้อยกว่า 20 ครั้ง และบันทึกข้อมูลลงใน Table combined และเพิ่ม Table user_rating เป็น Attribute หนึ่งใน Table combined ด้วย
%%sql
CREATE TABLE combined AS SELECT user_rating.BookTitle, user_rating.RatingCountBook, user_rating.UserID, user_rating.ISBN, user_rating.BookRating, user_count_filter.RatingCountUser
FROM user_rating
INNER JOIN user_count_filter
ON user_rating.UserID = user_count_filter.UserID* sqlite:///book_rec.db
Done.
[]
Check ข้อมูลใน Table combined
%%sql
SELECT * FROM combined LIMIT 5* sqlite:///book_rec.db
Done.

ซึ่งพบว่า Table combined จะมีจำนวน Record ทั้งหมด 293,796 Record
%%sql
SELECT count(*) FROM combined* sqlite:///book_rec.db
Done.

เมื่อคัดกรองข้อมูลการ Review ของ User ตามค่า Threshold ที่กำหนด ซึ่ง User แต่ละคนจะต้องมีการให้คะแนนหนังสือไม่น้อยกว่า 20 ครั้ง และหนังสือแต่ละเล่มจะต้องมี User มา Review ไม่น้อยกว่า 20 ครั้ง พบว่าข้อมูลที่คัดกรองแล้วมาจากหนังสือทั้งหมด 7,602 เล่ม และการ Review ของ User ทั้งหมด 3,426 คน
%%sql
select count(distinct BookTitle) AS NumberOfUniqueBooks
FROM combined* sqlite:///book_rec.db
Done.

%%sql
select count(distinct UserID) AS NumberOfUniqueUsers
FROM combined* sqlite:///book_rec.db
Done.

Transform to Dataset
1) Export Table combined ไปยัง Dataframe
เพื่อจะสร้าง Matrix ของคะแนนการ Review หนังสือของ User สำหรับ Train Model เราจะ Export Table combined จาก SQLite Database ไปยัง Dataframe
combined = %sql SELECT * FROM combined* sqlite:///book_rec.db
Done.
combined_df = pd.DataFrame(data = combined, columns = combined.field_names)
combined_df.head()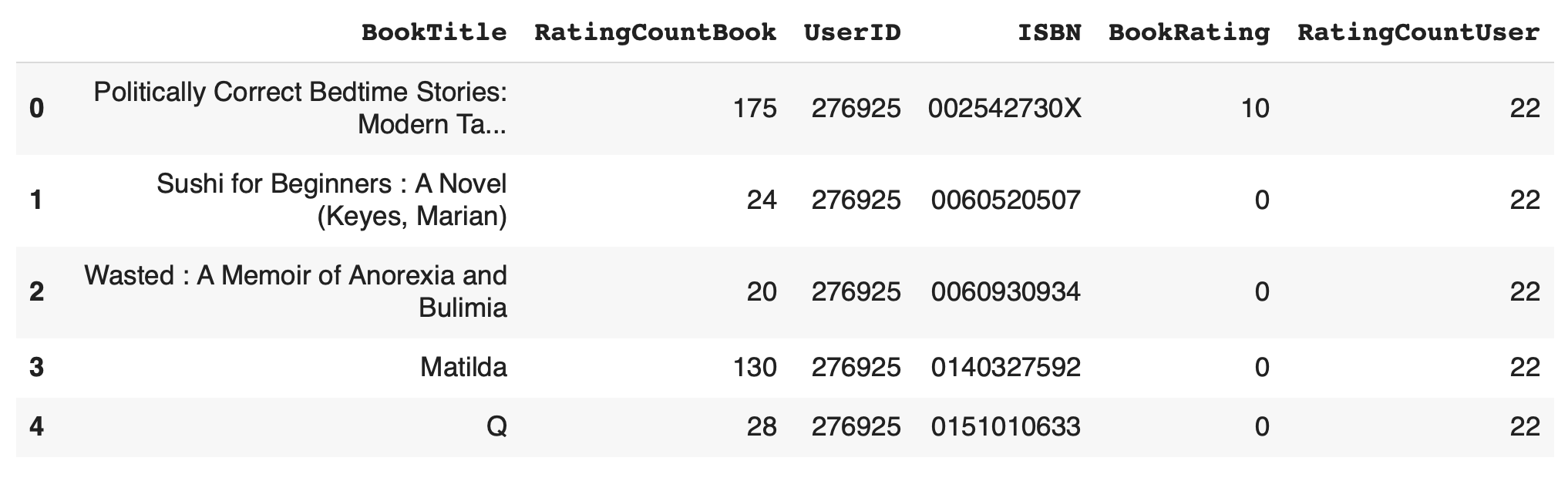
2) แปลงคะแนนจากเลขจำนวนเต็มเป็นเลขทศนิยม เพื่อจะทำ Normalization
combined_df['BookRating'] = combined_df['BookRating'].values.astype(float)
print(combined_df.shape)
combined_df.head()(293796, 6)
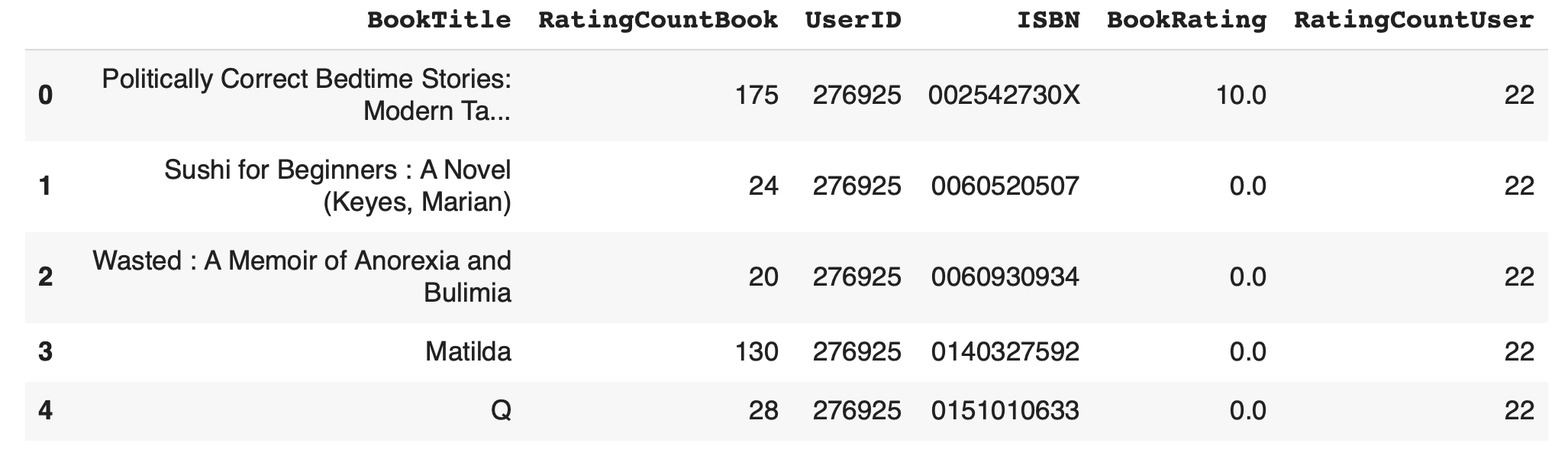
3) Drop ข้อมูลที่มี UserID และ BookTitle ซ้ำกัน
combined_df = combined_df.drop_duplicates(['UserID', 'BookTitle'])
print(combined_df.shape)(289865, 6)
4) เปลื่ยนโครงสร้างข้ออมูลแบบ Table เป็น Matrix ด้วยฟังก์ชัน pivot
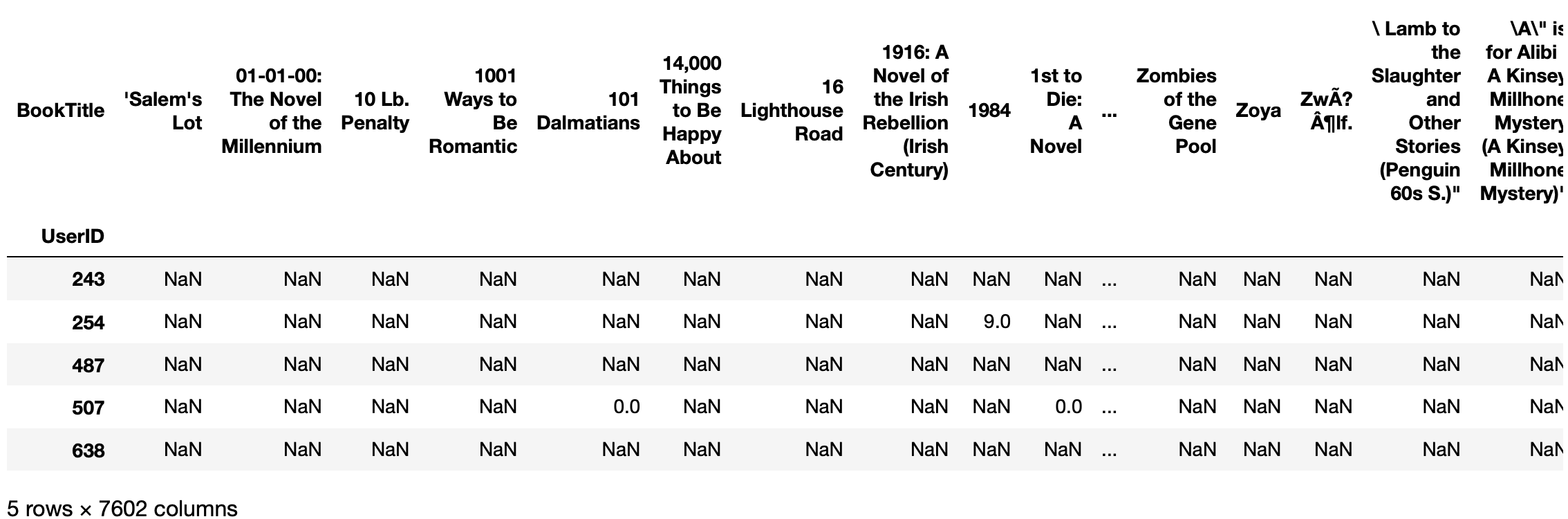
user_book_matrix = combined_df.pivot(index='UserID', columns='BookTitle', values='BookRating')
print(user_book_matrix.shape)
user_book_matrix.head()(3426, 7602)
5) สร้าง mask เพื่อไม่ให้ Model ทำโทษเมื่อมีการ Predict ผิดกับหนังสือที่ User ไม่เคยให้ Rating
mask = ~np.isnan(user_book_matrix)
mask = mask.astype(np.float32)6) แปลง Matrix ที่อยู่ในรูป Dataframe เป็น Numpy Array
user_book_matrix_zero_filled = np.nan_to_num(user_book_matrix, nan=0.0)
user_book_matrix_zero_filled.shape(3426, 7602)
8) สุ่มแบ่งข้อมูลสำหรับการ Train 80% และสำหรับการ Validate 20%
x_train, x_val, mask_train, mask_val = train_test_split(user_book_matrix_zero_filled, mask, test_size=0.2, random_state=1)9) ทำ Normalization
scaler = MinMaxScaler(feature_range=(0, 1))
# ปรับขนาดข้อมูลโดย fit กับข้อมูลฝึกเท่านั้น เพื่อป้องกันข้อมูลรั่วไหล (Data Leakage) จากชุดทดสอบไปยังชุดฝึก
scaler.fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_val_scaled = scaler.transform(x_val)คะแนนของ User จะมีค่าในช่วงตั้งแต่ 0.0 จนถึง 1.0
Autoencoder Model
Autoencoder เป็น Neural Network ที่มีโครงสร้างคล้ายรูปนาฬิกาทราย ซึ่งส่วนปลายทั้งสองข้างกว้าง แต่ตรงกลางของ Model แคบ ดังภาพด้านล่าง
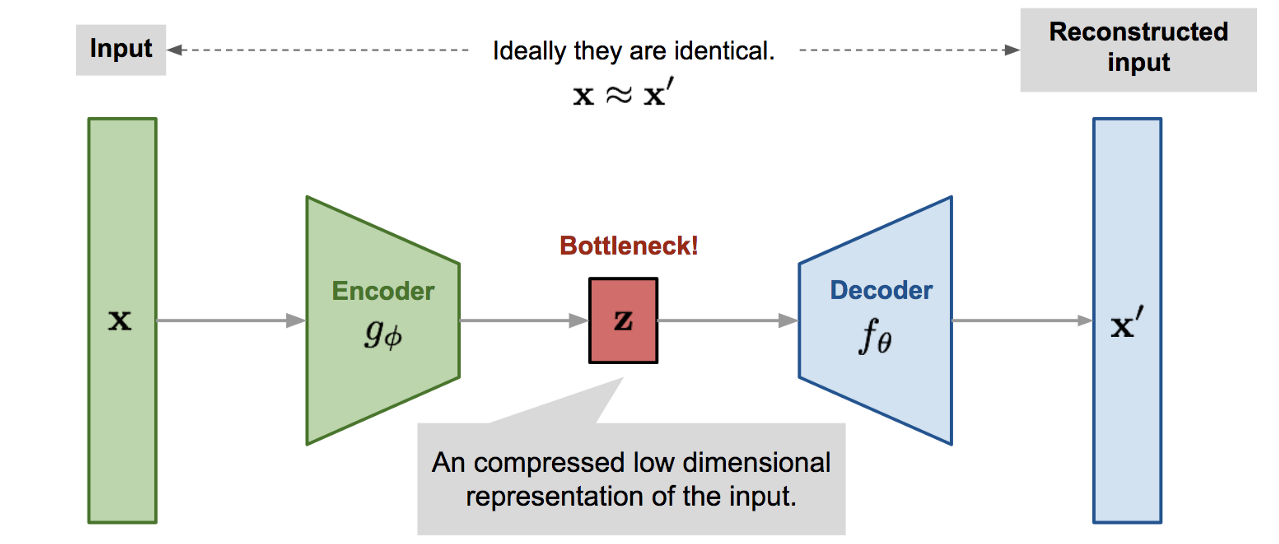
จากภาพ ส่วนปลายด้านที่ติดกับ Input Layer คือ Encoder Function มีหน้าที่แปลง Input Data X เป็น Latent Vector Z ขณะที่ส่วนปลายอีกด้าน คือ Decoder Function ทำหน้าที่แปลง Latent Vector Z กลับเป็น Output Data X'
ซึ่งในระหว่างการ Train Autoencoder กับข้อมูลการให้คะแนนหนังสือของ User, Encoder จะเรียนรู้ที่จะสรุปย่อ Information (Latent Vector Z) จาก Input Data และ Decoder จะเรียนรู้ที่จะแปลง Latent Vector Z กลับเป็น Output Data ที่ปลายอีกด้านของ Model
เราจะใช้ Autoencoder รับข้อมูลการให้คะแนนหนังสือ 7,602 เล่ม ของ User แต่ละคน โดยใช้ Mean Squared Error เป็น Loss Function และใช้ Sigmoid Activate Function เพื่อแปลง Output Data ให้อยู่ในช่วง 0 - 1
นิยาม Model
1) นิยาม Encoder
num_input = x_train_scaled.shape[1]
inp = tf.keras.layers.Input(shape=(num_input,))
e = tf.keras.layers.Dense(64)(inp)
e = tf.keras.layers.BatchNormalization()(e)
e = tf.keras.layers.LeakyReLU()(e)
e = tf.keras.layers.Dropout(0.3)(e)
e = tf.keras.layers.Dense(32)(e)
e = tf.keras.layers.BatchNormalization()(e)
e = tf.keras.layers.LeakyReLU()(e)
e = tf.keras.layers.Dropout(0.3)(e)
n_bottleneck = 16
bottleneck = tf.keras.layers.Dense(n_bottleneck)(e)2) นิยาม Decoder
d = tf.keras.layers.Dense(32)(bottleneck)
d = tf.keras.layers.BatchNormalization()(d)
d = tf.keras.layers.LeakyReLU()(d)
d = tf.keras.layers.Dropout(0.3)(d)
d = tf.keras.layers.Dense(64)(d)
d = tf.keras.layers.BatchNormalization()(d)
d = tf.keras.layers.LeakyReLU()(d)
d = tf.keras.layers.Dropout(0.3)(d)
decoded = tf.keras.layers.Dense(num_input, activation='sigmoid')(d)
ae = tf.keras.models.Model(inputs=inp, outputs=decoded)
ae.summary()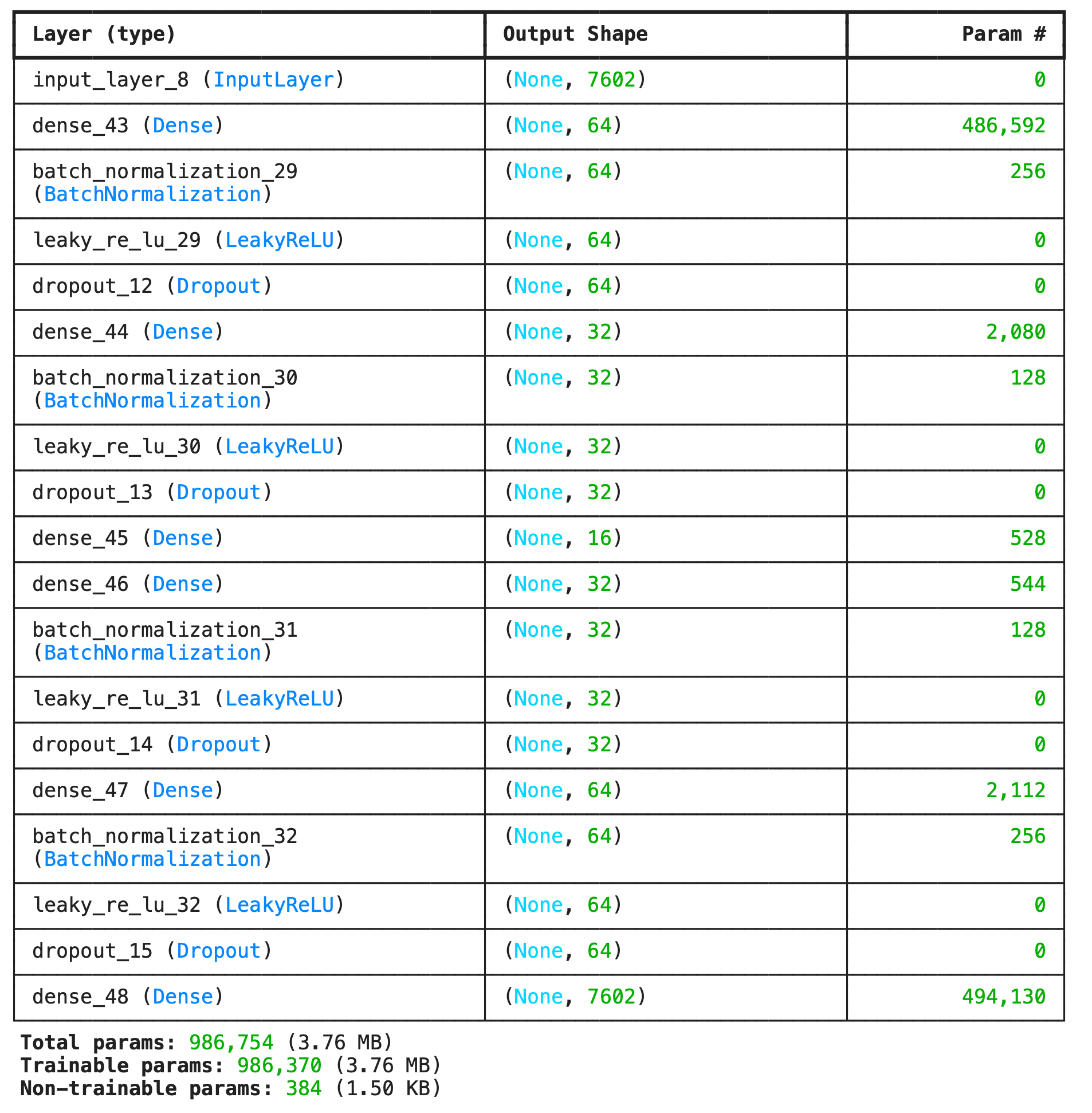
3) สร้าง Lost Function
mask_train_tensor = tf.convert_to_tensor(mask_train)
mask_val_tensor = tf.convert_to_tensor(mask_val)
def masked_mse(y_true, y_pred):
# y_true และ y_pred มีขนาด [batch_size, num_features]
mask = tf.cast(tf.not_equal(y_true, 0), tf.float32)
squared_difference = tf.square((y_true - y_pred) * mask)
# คำนวณ mse เฉพาะตำแหน่งที่มีการให้คะแนน
mse = tf.reduce_sum(squared_difference) / tf.reduce_sum(mask)
return mseCompile Model
ae.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001), loss=masked_mse)ทำ Check Point เพื่อ Save Weight ของ Model เฉพาะใน Epoch ที่มี val_loss น้อยที่สุด
filename = 'model.keras'
checkpoint = ModelCheckpoint(filename, monitor='val_loss', verbose=1, save_best_only=True, mode='min')Train Model
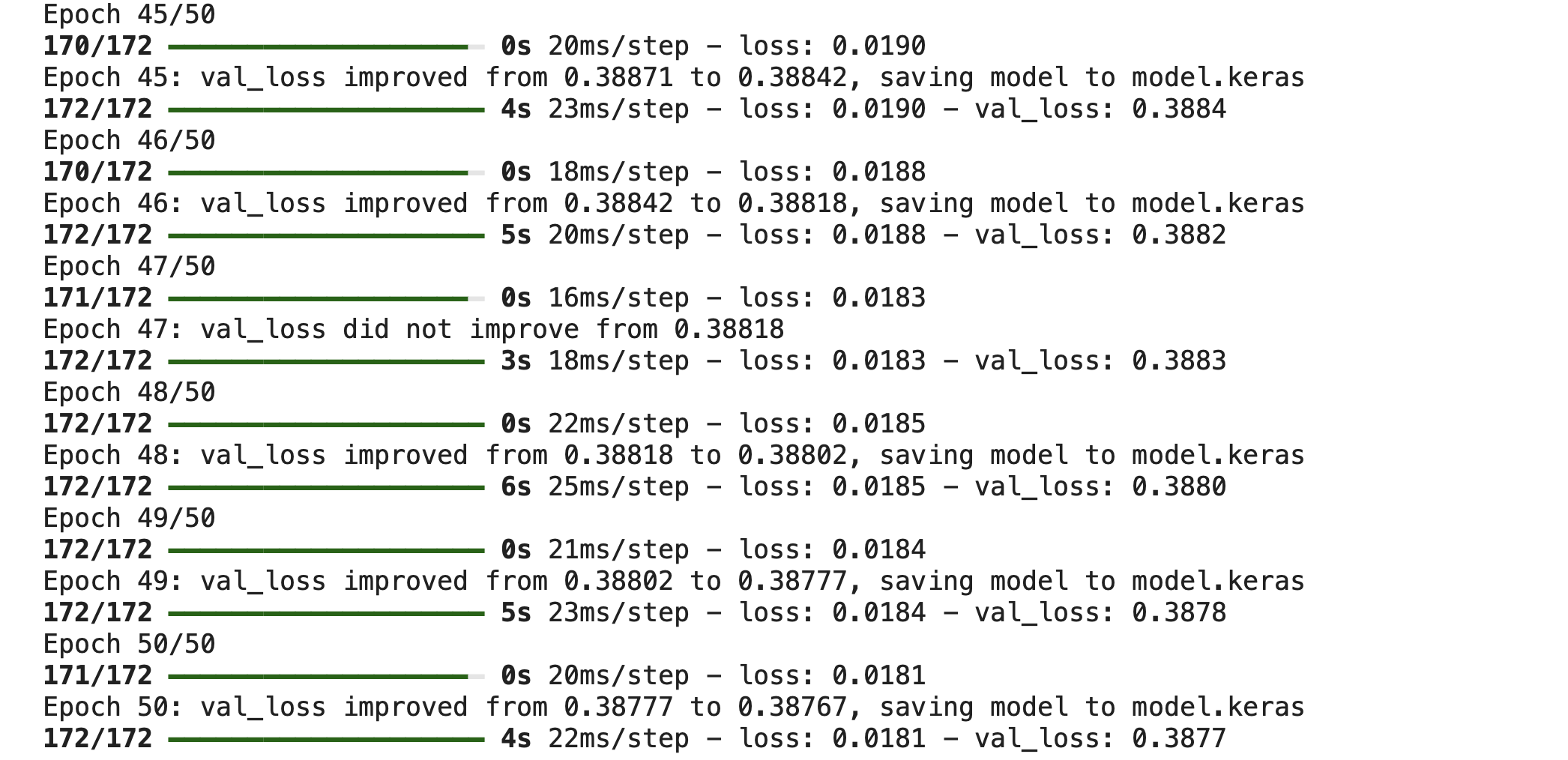
history = ae.fit(
x_train_scaled, x_train_scaled,
epochs=50,
batch_size=16,
validation_data=(x_val_scaled, x_val_scaled),
verbose=1,
callbacks = [checkpoint], shuffle= True
)
Plot Loss
h1 = go.Scatter(y=history.history['loss'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="loss"
)
h2 = go.Scatter(y=history.history['val_loss'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_loss"
)
data = [h1,h2]
layout1 = go.Layout(title='Loss',
xaxis=dict(title='epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1)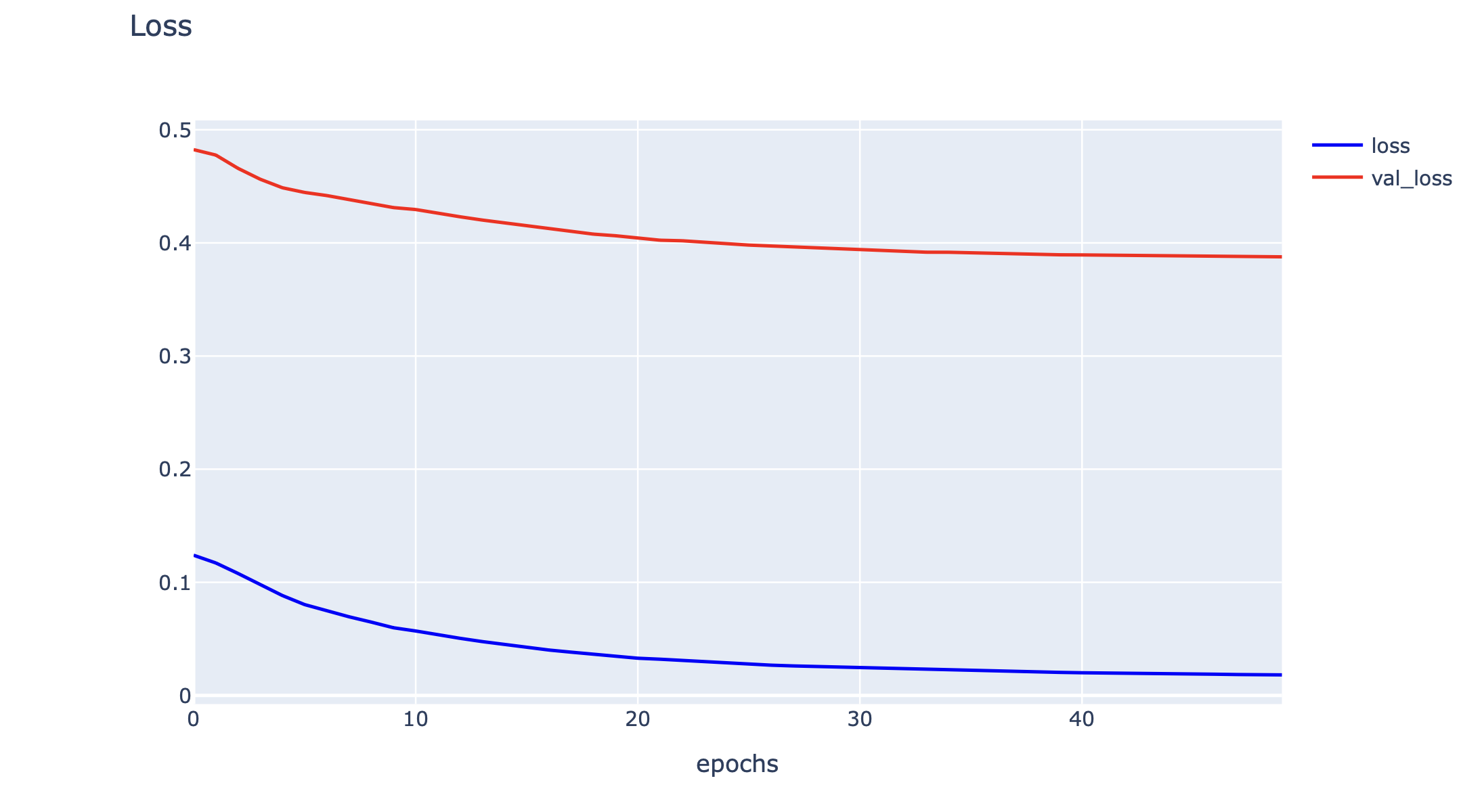
สร้าง Lost Function และ Load Weight จาก Epoch ที่ val_loss ต่ำที่สุด
def masked_mse(y_true, y_pred):
mask = tf.cast(tf.not_equal(y_true, 0), tf.float32)
squared_difference = tf.square((y_true - y_pred) * mask)
mse = tf.reduce_sum(squared_difference) / tf.reduce_sum(mask)
return mse# predict_model = load_model(filename)
predict_model = load_model(filename, custom_objects={'masked_mse': masked_mse})
predict_model.summary()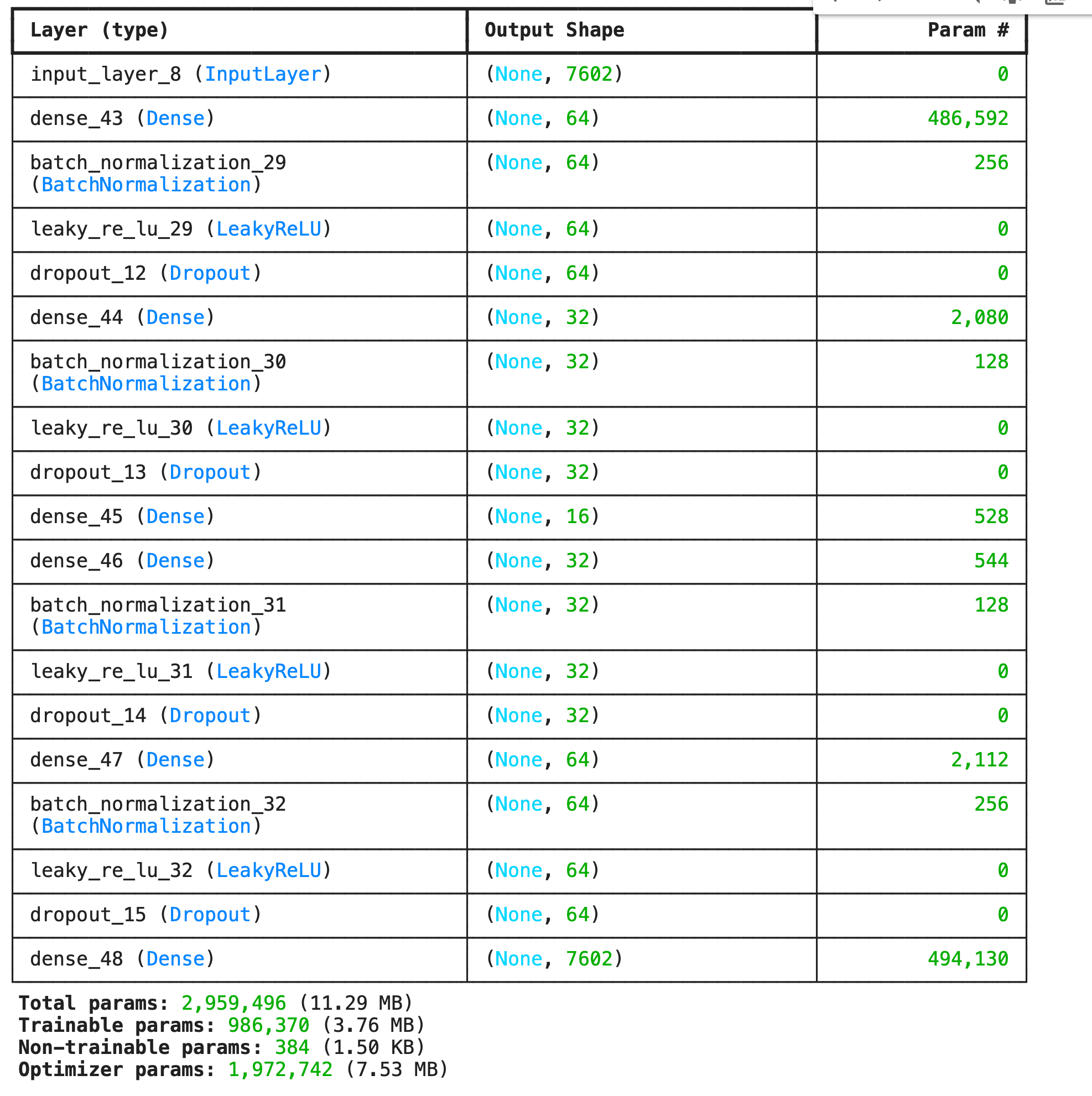
Predict Model
# ทำนายคะแนน
predictions_scaled = ae.predict(user_book_matrix_zero_filled)
# แปลงค่ากลับสู่ช่วงเดิม
predictions = scaler.inverse_transform(predictions_scaled)
# ตั้งค่าคะแนนของหนังสือที่ผู้ใช้เคยให้คะแนนเป็นค่าต่ำสุด
user_rated = (user_book_matrix_zero_filled > 0).astype(float)
adjusted_predictions = predictions - user_rated * 1e5
# สำหรับผู้ใช้แต่ละคน หาหนังสือที่มีคะแนนสูงสุด
top_n = 10
recommendations = np.argsort(-adjusted_predictions, axis=1)[:, :top_n] # หาหนังสือที่ได้คะแนนสูงสุด
recommendations.shape(3426, 10)
แปลงผลลัพธ์จาก Index ไปเป็น UserID และ BookTitle
user_ids = user_book_matrix.index.tolist() # รายชื่อ UserID
book_titles = user_book_matrix.columns.tolist() # รายชื่อ BookTitle
# เก็บรายการแนะนำในรูปแบบ Dictionary
user_recommendations = {}
# สำหรับผู้ใช้แต่ละคน ให้แปลงจาก Index เป็นชื่อหนังสือ
for i, user_id in enumerate(user_ids):
recommended_books_idx = recommendations[i] # ดึงดัชนีหนังสือที่แนะนำ
recommended_books = [book_titles[idx] for idx in recommended_books_idx] # แปลงดัชนีเป็นชื่อหนังสือ
user_recommendations[user_id] = recommended_books # เก็บใน Dictionaryทดลอง Query หนังสือแนะนำสำหรับ UserID = 243
user_id = 243
recommended_books_for_user_243 = user_recommendations.get(user_id, [])
print(f"Top 10 หนังสือที่แนะนำสำหรับ UserID {user_id}")
for book in recommended_books_for_user_243:
print(book)
เปรียบเทียบกับหนังสือที่ผู้ใช้ให้คะแนนมากที่สุด
user_ratings = user_book_matrix.loc[user_id].sort_values(ascending=False)
top_rated_books_by_user = user_ratings.index[:10].tolist()
print(f"หนังสือที่ UserID {user_id} เคยให้คะแนนมากที่สุด 10 อันดับ")
for book in top_rated_books_by_user:
print(book)
แปลงผลการ Predict เป็น Table ลงใน SQLite Database
1) แปลงผลการ Predict ของ Model เป็น Dataframe และบันทึกข้อมูลลง SQLite Database
recommendations_data = []
for user_id, recommended_books in user_recommendations.items():
for rank, book in enumerate(recommended_books):
recommendations_data.append((user_id, book, rank+1)) # เพิ่มอันดับหนังสือในรายการ
recommendations_df = pd.DataFrame(recommendations_data, columns=['UserID', 'BookTitle', 'Rank'])
recommendations_df.to_sql('user_recommendations', connect, if_exists='replace', index=False)Query Top 10 Book Rating
1) ค้นหาหนังสือให้แก่ UserID 243 โดยเรียงลำดับคะแนนความชอบตามที่ Model ทำนาย
%%sql
SELECT BookTitle, Rank
FROM user_recommendations
WHERE UserID = 243
ORDER BY Rank ASC
LIMIT 10* sqlite:///book_rec.db
Done.
