Microservices Architecture: Concepts, Design, and Best Practices


บทความโดย ผศ.ดร.ณัฐโชติ พรหมฤทธิ์ และ อ.ดร.สัจจาภรณ์ ไวจรรยา
ภาควิชาคอมพิวเตอร์
คณะวิทยาศาสตร์
มหาวิทยาลัยศิลปากร
ในยุคดิจิทัลปัจจุบัน ระบบ Software ต้องรองรับความต้องการที่เปลี่ยนแปลงอย่างรวดเร็ว ทั้งปริมาณผู้ใช้งานที่เพิ่มขึ้น และความซับซ้อนของกระบวนการทางธุรกิจ สถาปัตยกรรมแบบ Monolithic ซึ่งรวมทุก Function ไว้ในระบบเดียวอาจเริ่มมีข้อจำกัดด้านการปรับขนาด การดูแลรักษา
Microservices Architecture เป็นแนวทางหนึ่งในการออกแบบระบบ โดยมีเป้าหมายเพื่อแยกระบบออกเป็นส่วนย่อยที่มีความรับผิดชอบชัดเจน
อย่างไรก็ตาม การเลือกใช้ Microservices จำเป็นต้องพิจารณาในเชิงวิศวกรรมอย่างรอบด้าน เนื่องจากสถาปัตยกรรมแบบกระจายมาพร้อมกับต้นทุนและความซับซ้อนที่เพิ่มขึ้น
บทความนี้มีวัตถุประสงค์เพื่ออธิบายแนวคิด Microservices เปรียบเทียบกับ Monolithic Architecture เชื่อมโยงกับหลักการ 12-Factor App รูปแบบ Frontend แบบ SPA/MPA และการออกแบบ REST API โดยเน้นทั้งมุมมองเชิงแนวคิดและข้อพิจารณาในการใช้งานจริง
แนวคิดของ Microservices
Microservices Architecture เป็นแนวทางในการพัฒนา Software โดยแบ่งระบบออกเป็น Service ขนาดเล็ก แต่ละ Service มีความรับผิดชอบตามขอบเขตของธุรกิจ (Bounded Context) ซึ่งสามารถพัฒนา ทดสอบ และ Deploy ได้อย่างอิสระ โดย Service เหล่านี้สื่อสารกันผ่าน API และเครือข่าย
เมื่อเปรียบเทียบกับ Monolithic Architecture ซึ่งทุกองค์ประกอบทำงานอยู่ภายใน Process หรือ Deployment เดียว Microservices ช่วยให้ทีมสามารถพัฒนาแต่ละส่วนของระบบแบบขนาน และปรับขนาดเฉพาะส่วนที่จำเป็นได้ อย่างไรก็ตาม การเปลี่ยนไปสู่ Microservices คือการเปลี่ยนจากความซับซ้อนภายในระบบเดียว ไปสู่ความซับซ้อนของระบบแบบกระจาย (Distributed System)
ในเชิงวิศวกรรม ความซับซ้อนที่เพิ่มขึ้นอาจรวมถึง
- ความหน่วงของเครือข่าย (Network Latency)
- ความล้มเหลวที่เกิดขึ้นได้บางส่วน (Partial Failure)
- ความสอดคล้องของข้อมูล (Data Consistency)
- ความยากในการติดตามปัญหา (Observability)
ในทางปฏิบัติ ระบบจำนวนมากเริ่มต้นด้วย Modular Monolith ซึ่งเป็น Monolithic Architecture ที่มีการแบ่งโครงสร้างภายในชัดเจน และค่อยแยกออกเป็น Microservices เมื่อระบบ ทีม และโครงสร้างพื้นฐานมีความพร้อมมากขึ้น
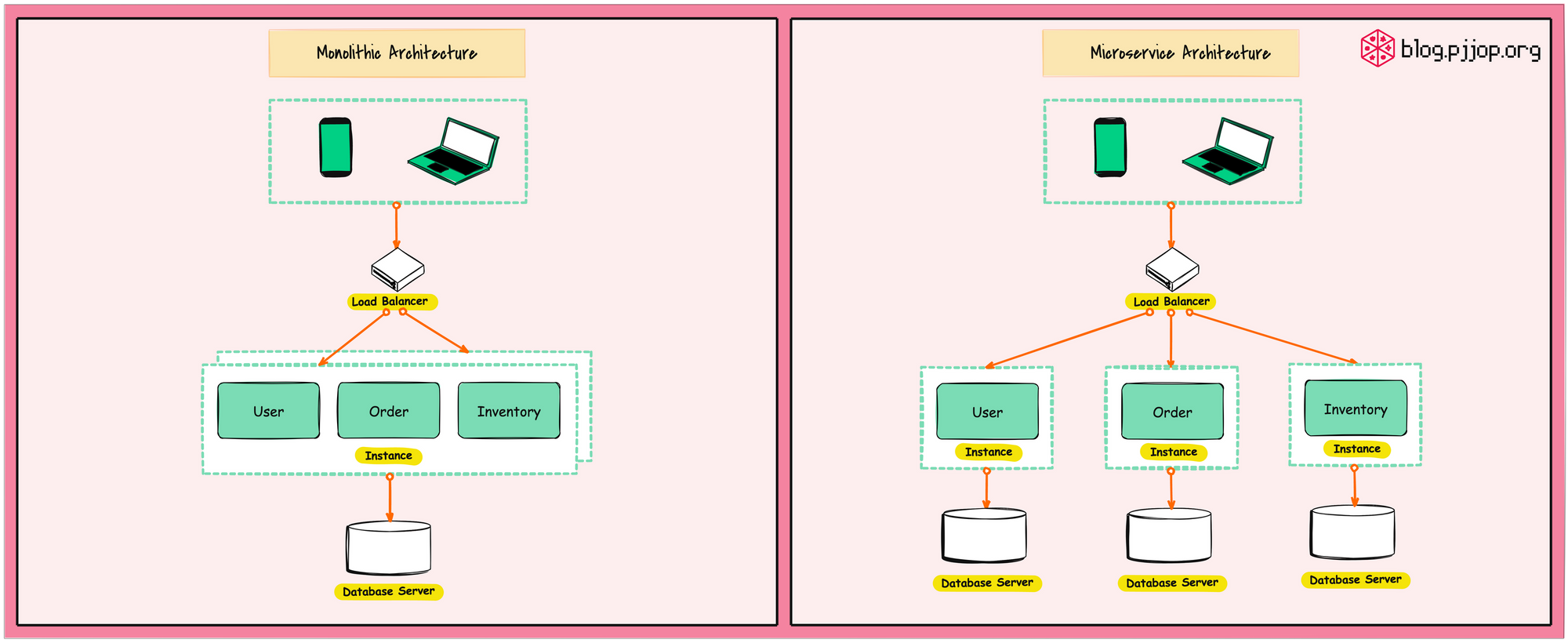
การแบ่ง Function ออกเป็น Service ขนาดเล็ก ทำให้ระบบมีความสามารถในการปรับขนาดได้ (Scalability) ด้วยการทำซ้ำ Service หรือ Instance ซึ่งระบบที่สามารถ Scale ได้จะมีความสามารถในการรับ Load ได้มากขึ้น นอกจากนี้ยังเป็นการเพิ่มความพร้อมใช้งาน (Availability) ของระบบ จากการมีความซ้ำซ้อนกันของ Instance (Redundancy) ทำให้เหมาะสำหรับระบบของธุระกิจที่มีการเติบโตสูง และมีทีมพัฒนาจำนวนมาก
เราสามารถสรุปประเด็นสำคัญของ Microservices Architecture ได้ดังต่อไปนี้
- เป็นการแบ่ง Function ของ Monolithic Application ออกเป็น Service ขนาดเล็ก แต่ละ Service มีความเป็นอิสระต่อกันสามารถใช้ทีมพัฒนา Test และ Deploy ที่แตกต่างกันซึ่งมีการปรับให้เหมาะสมกับแต่ละส่วนของธุระกิจ มีประโยชน์สําหรับองค์กรขนาดใหญ่ที่ต้องการปรับปรุงประสิทธิภาพการทํางาน
- แต่ละ Service มีการสื่อสารระหว่างกันอย่างหลวม ๆ ผ่าน API โดย Frontend และ Backend จะสื่อสารกันผ่าน REST API ในขณะที่การสื่อสารระหว่าง Service ด้วยกันเอง มักใช้ RPC หรือ Message Queue
- แต่ละ Service มีขอบเขตของการให้บริการที่ชัดเจนตามความต้องการทางธุรกิจ (Bounded Context)
- ในทางปฏิบัติมักใช้แนวทางของทีมพัฒนาแบบ DevOps ทีมมีขนาดเล็ก เป็น Full-stack หรือมีครบทั้ง Fontend, Backend และผู้ดูแลระบบ (Operation)
- ออกแบบให้สามารถ Scale ได้ในแนวนอน (Horizontally Scalable) มีความทนทานต่อความล้มเหลว
- มีการกำกับดูแลแบบกระจายอำนาจ ทีมสามารถเลือกเทคโนโลยีที่เหมาะสมกับ Service ของเขาได้
Microservices เป็นรูปแบบหนึ่งของ Distributed System ซึ่งประกอบด้วยหลาย Component ที่ทำงานร่วมกันผ่านเครือข่าย อย่างไรก็ตาม Distributed System ไม่จำเป็นต้องเป็น Decentralized เสมอไป
Decentralized System คือ Distributed System ที่ไม่มี Component ใดควบคุมการตัดสินใจทั้งหมด แต่ละ Component มีอำนาจการตัดสินใจบางส่วนและต้องประสานงานร่วมกัน
การออกแบบ Microservices ในโลกจริงจึงต้องคำนึงถึงระดับของการกระจายอำนาจ ทั้งในด้านเทคโนโลยีและการกำกับดูแลทีม
การกระจายอำนาจช่วยเพิ่มความยืดหยุ่น แต่ก็เพิ่มความยากในการควบคุมมาตรฐาน ความปลอดภัย และคุณภาพของระบบโดยรวม
12-Factor App สำหรับการพัฒนา Microservices
12-Factor App เป็นแนวทางในการพัฒนา Application ที่เหมาะกับสภาพแวดล้อมแบบ Cloud และ Distributed โดยมีเป้าหมายเพื่อให้ระบบสามารถ Deploy, Scale และดูแลรักษาได้ง่าย
อย่างไรก็ตาม 12-Factor App ถูกมองว่าเป็น แนวทาง (Guideline) ไม่ใช่มาตรฐานที่ต้องปฏิบัติตามอย่างเคร่งครัดทุกข้อ ในระบบจริงอาจจำเป็นต้องปรับใช้บางหลักการให้เหมาะสมกับบริบท เช่น
- ระบบที่ต้องมี State ชั่วคราว
- ระบบ Legacy ที่ไม่สามารถแยก Config ได้ทั้งหมด
- งานบางประเภทที่ต้องพึ่งพา Local Resource ชั่วคราว
เป้าหมายสำคัญของ 12-Factor App คือการลดการพึ่งพา Environment เพิ่มความสามารถในการคาดเดาพฤติกรรมของระบบ และสนับสนุนการพัฒนาในระยะยาว มากกว่าการทำตามหลักการครบทุกข้อโดยไม่พิจารณาต้นทุน
ใน 12-Factor App นั้น Processes คือ First Class Citizen
12-Factor App Principle
Codebase
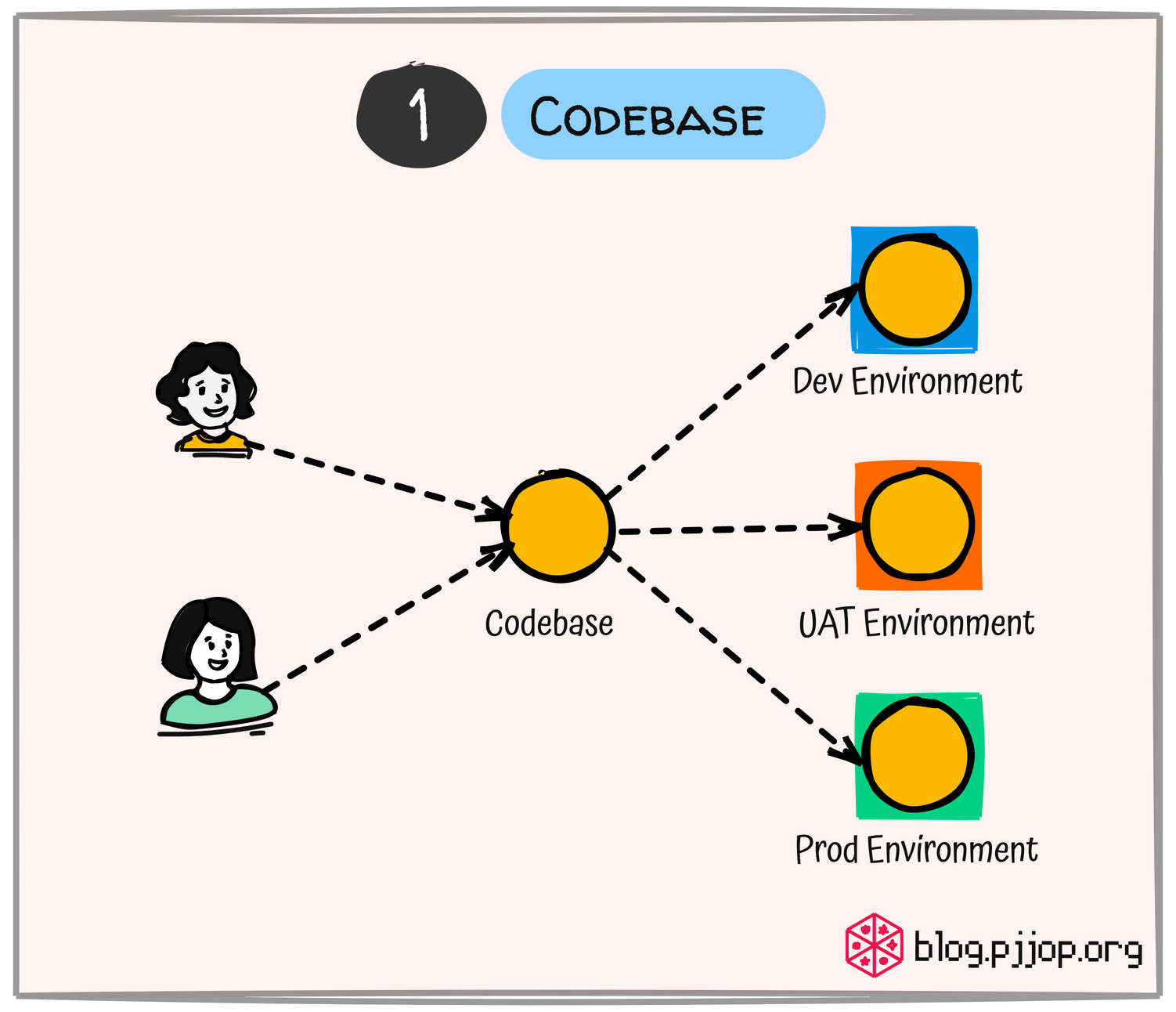
Codebase ควรมีที่เดียวเพื่อเก็บ Code ทั้งหมดของ Project และจัดการโดยใช้ Version Control เช่น GitHub หรือ GitLab ฯลฯ ทั้ง Dev, UAT และ Production Environment ควรมาจาก Codebase เดียวกัน
Codebase คือ ชุดของ Code ที่ใช้ในการพัฒนา Software ได้แก่ Source Code และไฟล์อื่น ๆ ที่จำเป็น เช่น Image, Audio คู่มือการใช้งาน และเอกสารต่าง ๆ ที่เกี่ยวข้อง, Script สำหรับการ Build, Test และ Deploy ไฟล์การตั้งค่า ฯลฯ
Codebase เป็นส่วนสำคัญในการพัฒนา Software ทำให้ทีมพัฒนาสามารถทำงานร่วมกัน ติดตามการเปลี่ยนแปลง และบำรุงรักษา Project ได้อย่างมีประสิทธิภาพ ในทางปฏิบัติสำหรับการพัฒนา Software แบบ Microservices เราสามารถแยกเก็บ Codebase ของแต่ละ Service ลงในแต่ละ Git Repository ได้
Dependency
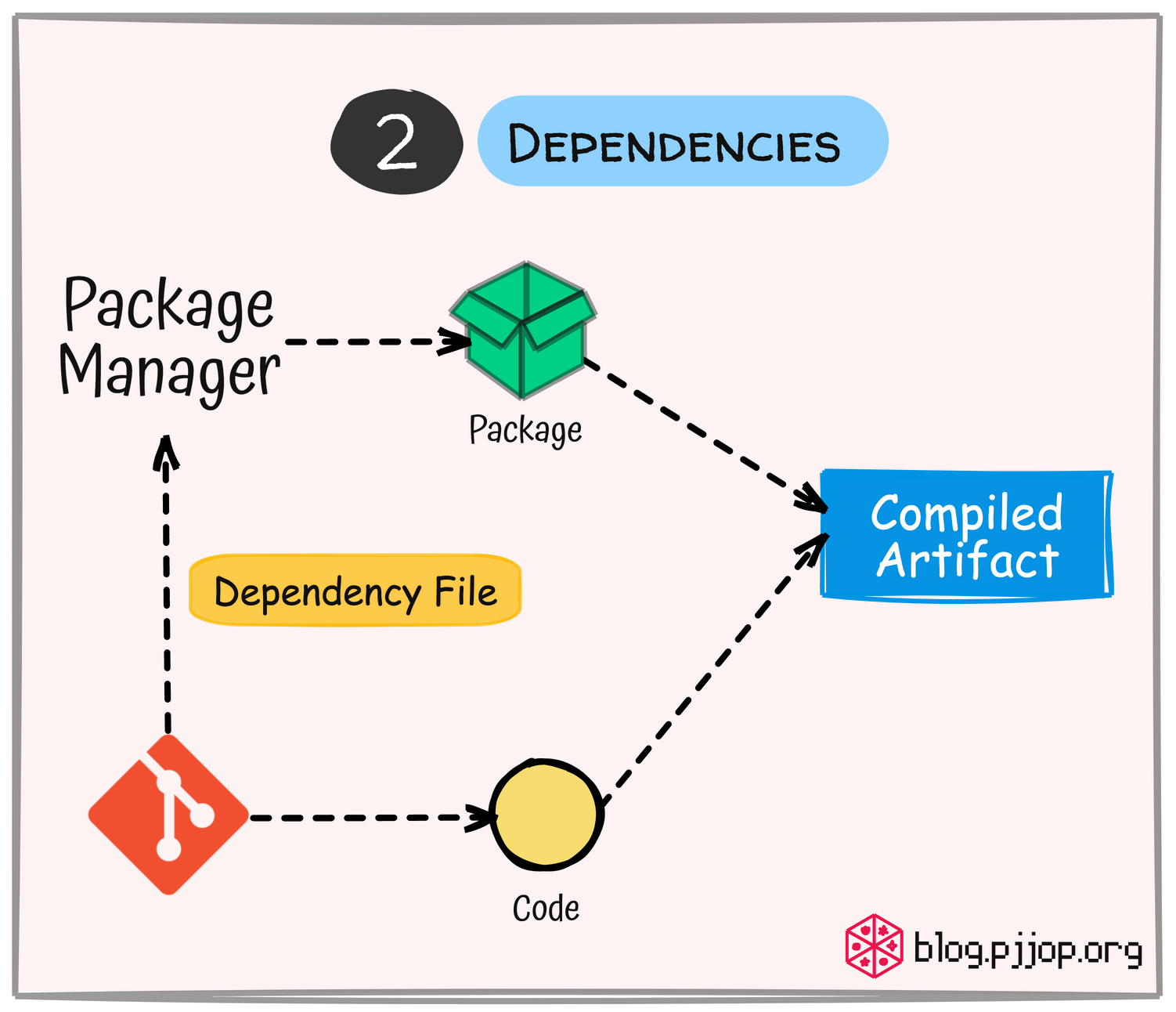
List ของสิ่งที่จำเป็นในการแปลง Source Code ให้อยู่ในรูปแบบที่คอมพิวเตอร์ หรือ Execution Environment สามารถเข้าใจได้ (Compiled Atifact) ควรเก็บไว้ใน Codebase
module example.com/hello
go 1.21.0
require (
github.com/gin-gonic/gin v1.7.4
github.com/go-sql-driver/mysql v1.6.0
)Config
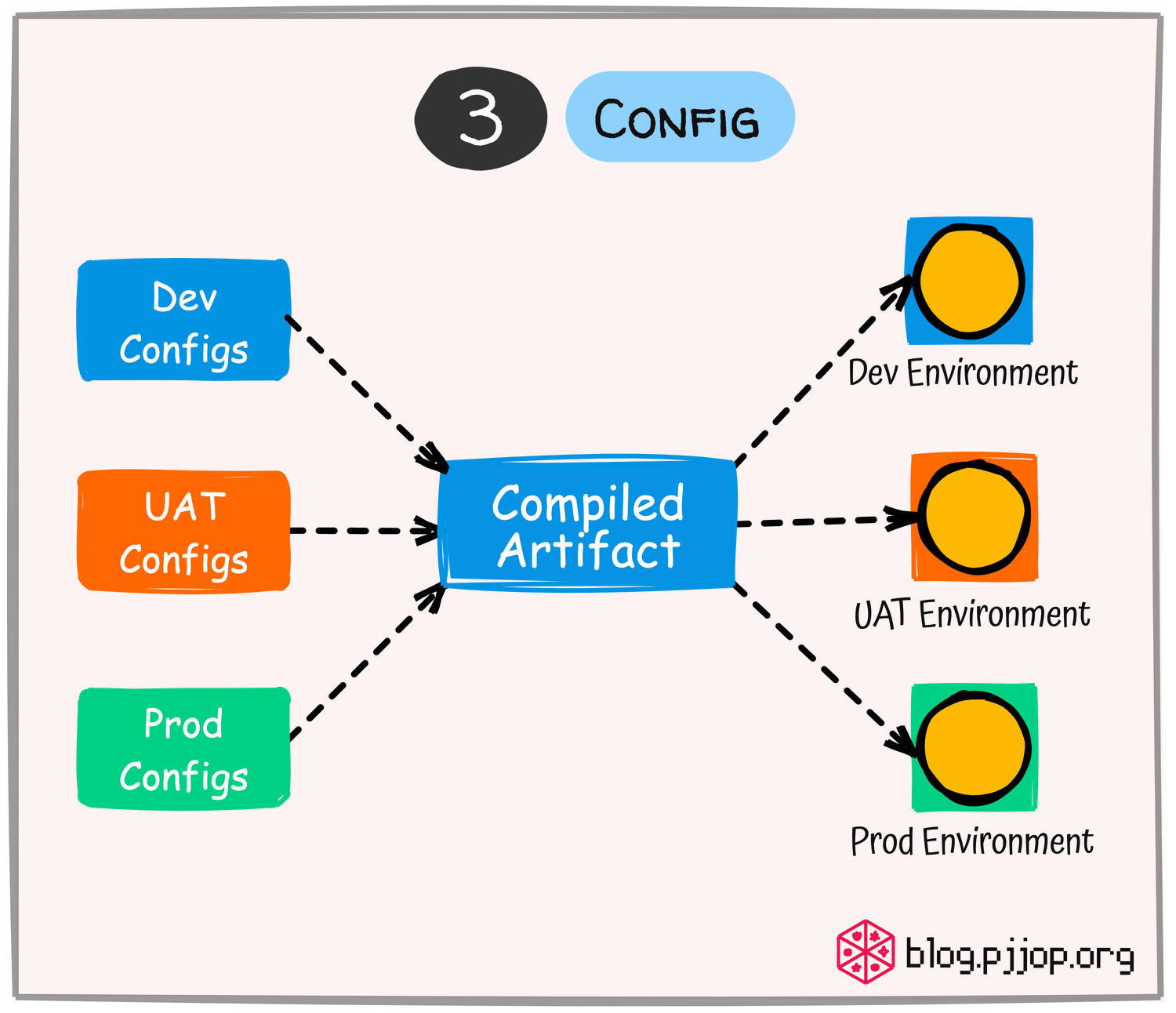
แยกการตั้งค่าที่สําคัญ เช่น ข้อมูลสำหรับการ Connect Database ออกจาก Code เพื่อให้สามารถเปลี่ยนมันได้โดยไม่ต้องเขียน Code ใหม่ เมื่อต้อง Deploy ในแต่ละ Environment โดยในทางปฏิบัติเราสามารถเก็บ Config แยกแต่ละ Enveronment ไว้นอก Codebase ได้
Backing Services
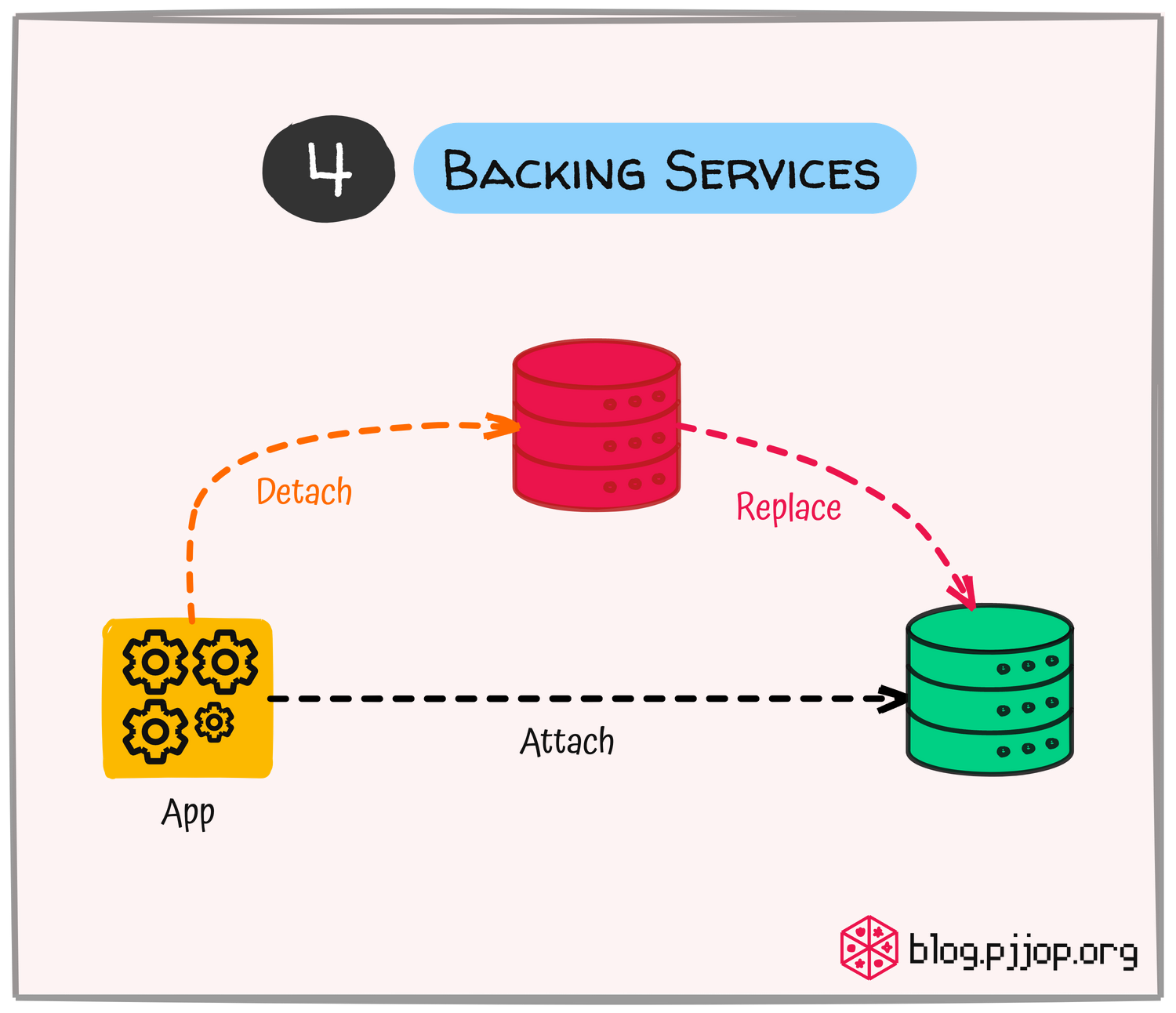
Backing Services หรือบริการต่าง ๆ ที่ Application ต้องพึ่งพาเพื่อทำงานได้อย่างสมบูรณ์ โดยเป็นส่วนที่แยกออกจาก Application หลัก และมักจะเข้าถึงผ่านเครือข่าย เช่น Database, ระบบ Cache, Message Queue, SMTP Service สำหรับส่ง Email, File Service ควรจัดการเชื่อมต่อผ่านการตั้งค่าผ่าน Environment Variables ไม่ใช่การ Hard-code
Build, Release, Run
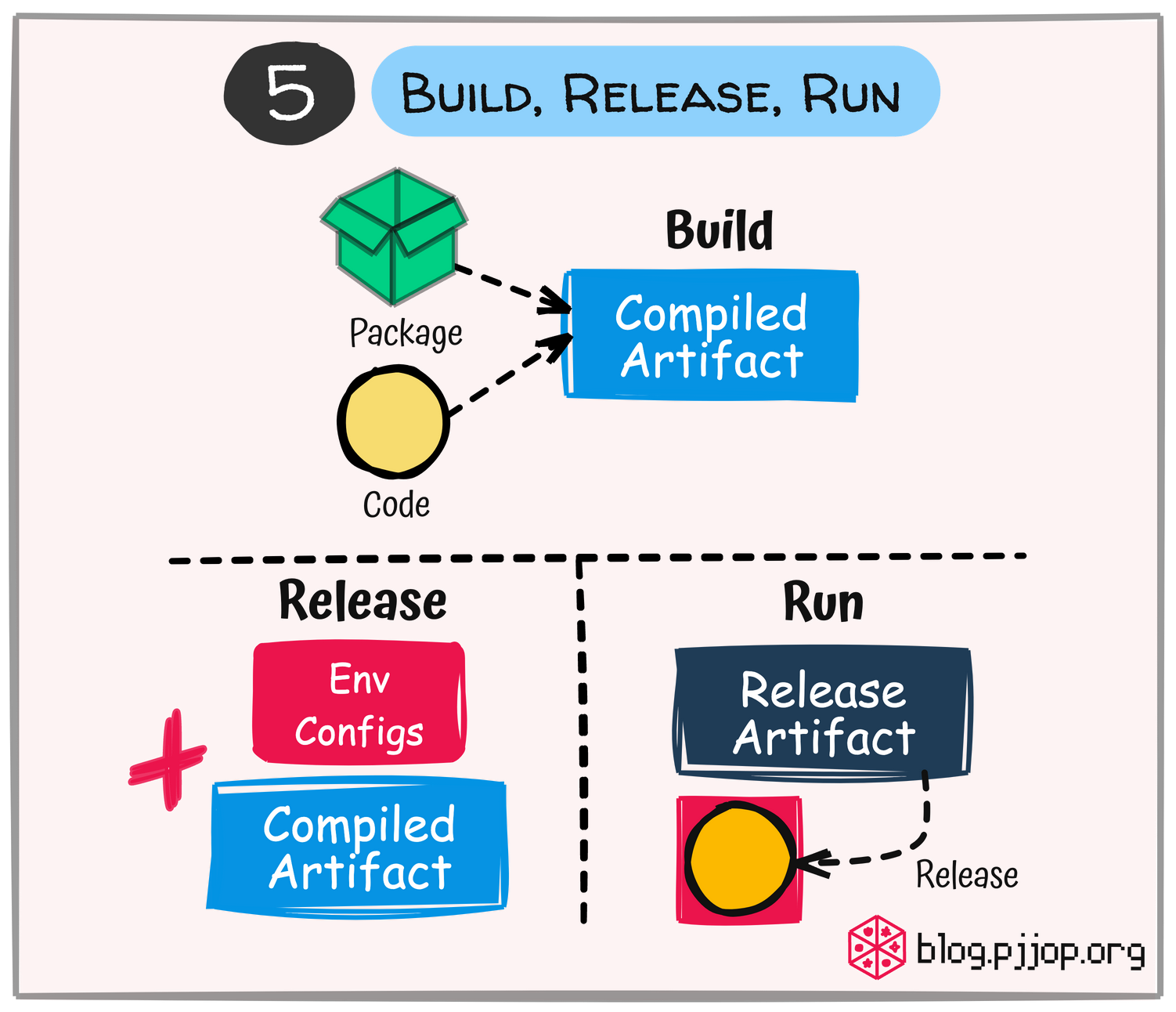
แยกขั้นตอนการพัฒนาและการ Deploy Application ออกเป็น 3 ส่วน ได้แก่ Build คือ การแปลงโค้ดเป็น Build Artifact, Release คือ การรวม Build Artifact กับการตั้งค่าสำหรับ Environment ที่จะ Deploy และ Run คือ การรัน Application ใน Execution Environment อย่างชัดเจน
การแยก Build, Release, Run ทำให้มั่นใจได้ว่าส่วนที่ทดสอบแล้วจะถูก Deploy จริง ง่ายต่อการ Rollback หากเกิดปัญหา สนับสนุนการทำ Continuous Deployment
นอกจากนี้ยังช่วยลดความเสี่ยงจากการแก้ไข Code บน Production Environment แยกหน้าที่ความรับผิดชอบได้ชัดเจนระหว่างทีมพัฒนาที่สามารถโฟกัสที่การ Build ทีม Operation ที่จัดการเรื่องการ Release และการ Run และทำให้การจัดการการตั้งค่าแยกจาก Code ซึ่งสามารถเปลี่ยนแปลงการตั้งค่าโดยไม่ต้อง Rebuild
สำหรับการพัฒนา Software แบบ Microservices แต่ละ Service จะมีกระบวนการ Build, Release, Run ของตัวเอง
Processes
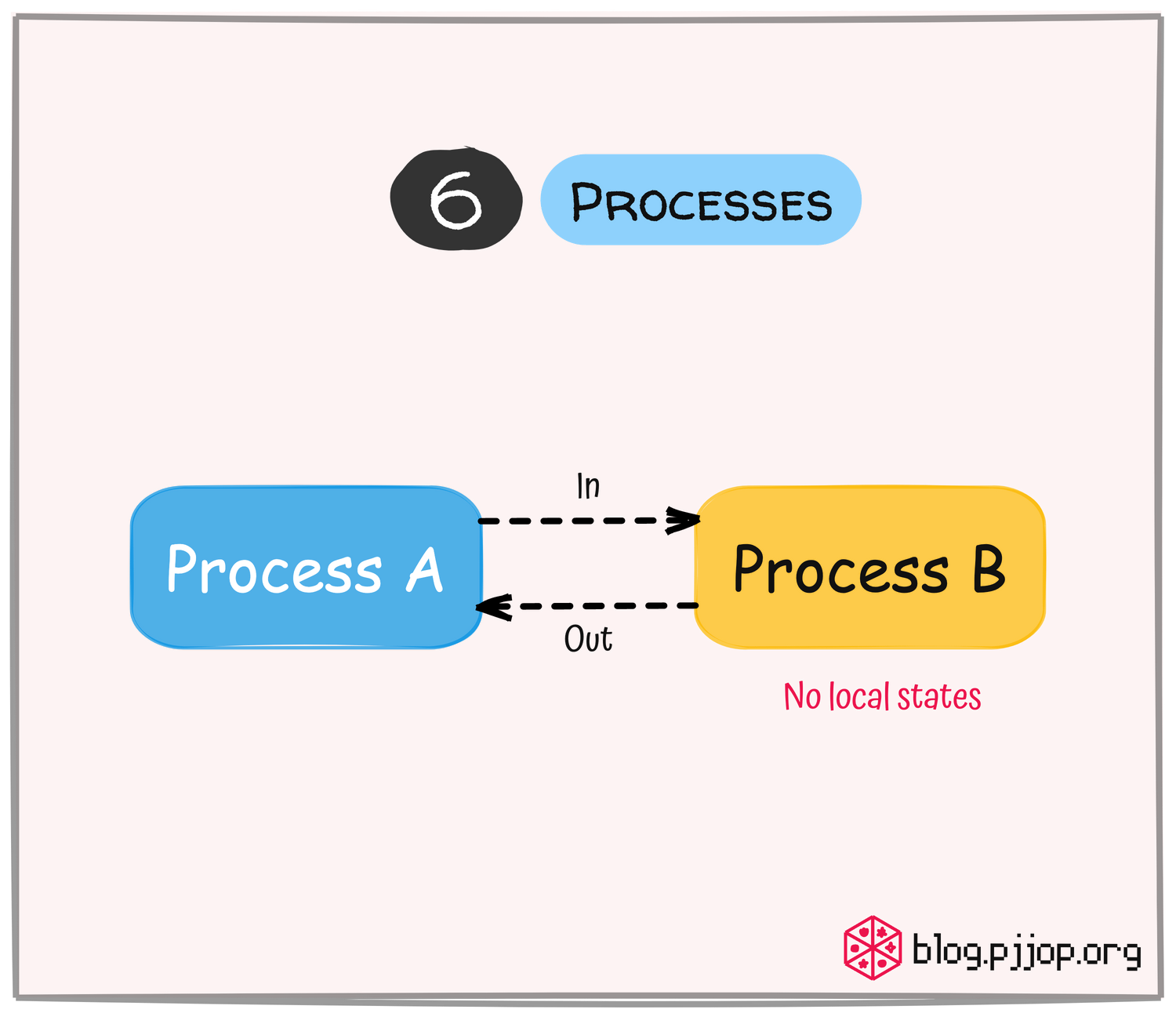
ออกแบบ Application เพื่อให้แต่ละส่วนไม่ต้องพึ่งพาคอมพิวเตอร์หรือหน่วยความจำเป็นการเฉพาะ โดยไม่เก็บ State ต่าง ๆ ไว้ภายใน Process (No Local State) แต่ข้อมูลที่ต้องเก็บควรอยู่ใน Backing Service ซึ่งจะช่วยให้ Application มีความยืดหยุ่น Scale ได้ง่ายเพื่อรองรับ Load ที่เพิ่มขึ้น และทนทานต่อความล้มเหลว
Port Binding

Application ควรเปิดให้เข้าถึงได้ผ่าน Network Port โดยตรง โดยไม่ต้องพึ่งพา Web Servcer ภายนอก เช่น Apache หรือ Nginx ในการรัน
เมื่อ Application สามารถควบคุม HTTP Request กำหนด Route และจัดการ Thread ได้โดยตรงด้วยตัวเอง การ Deploy จะง่ายขึ้นและสามารถ Scale ได้อย่างอิสระ
Port Binding ช่วยให้ Application เป็นอิสระมากขึ้น ง่ายต่อการ Deploy และ Scale ในสภาพแวดล้อมแบบ Cloud-native หรือ Containerized
หมายเหตุ เราสามารถพัฒนา PHP Application ให้สอดคล้องกับหลักการ Port Binding ได้ แม้ว่าบ่อยครั้งมันมักถูกใช้ร่วมกับ Web Server ภายนอกก็ตาม
เพื่อให้การพัฒนา PHP Application สอดคล้องกับหลักการ Port Binding ผู้พัฒนาสามารถใช้ PHP-FPM (FastCGI Process Manager) ร่วมกับ Docker โดยให้ Nginx ทำหน้าที่รับ HTTP Request จากภายนอกและส่งต่อไปยัง PHP-FPM Container (PHP Application)
Concurrency
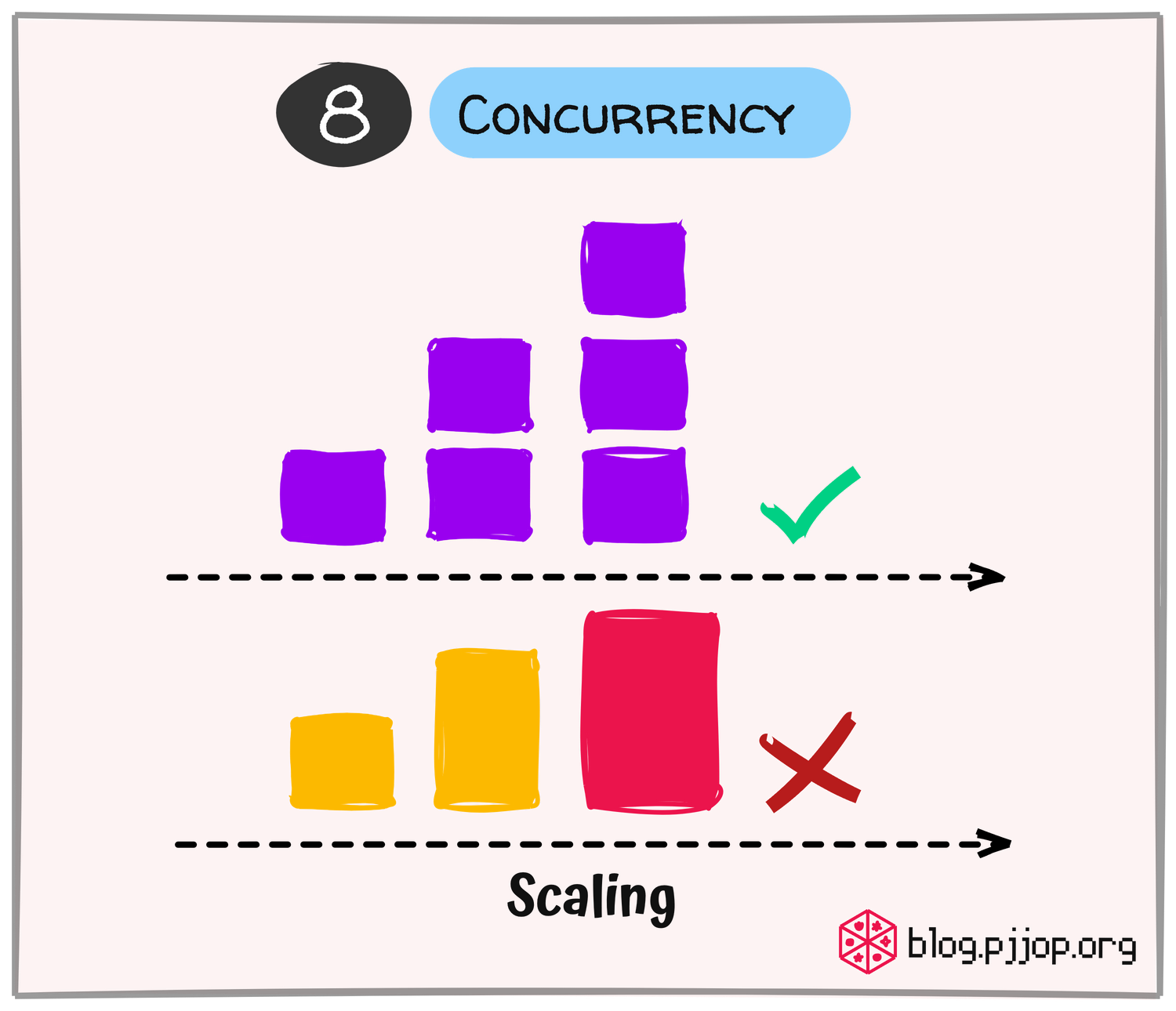
ออกแบบ Application ให้สามารถจัดการงานได้มากขึ้นโดยการเพิ่ม Copy ของ Instance (Horizontal Scaling) แทนการเพิ่มขนาดของ Instance (Vertical Scaling) หรือเรียกว่าการ Scale โดยการเพิ่มจำนวน Process เพื่อให้สามารถทำงานได้พร้อมกัน (Concurrency)
Disposability
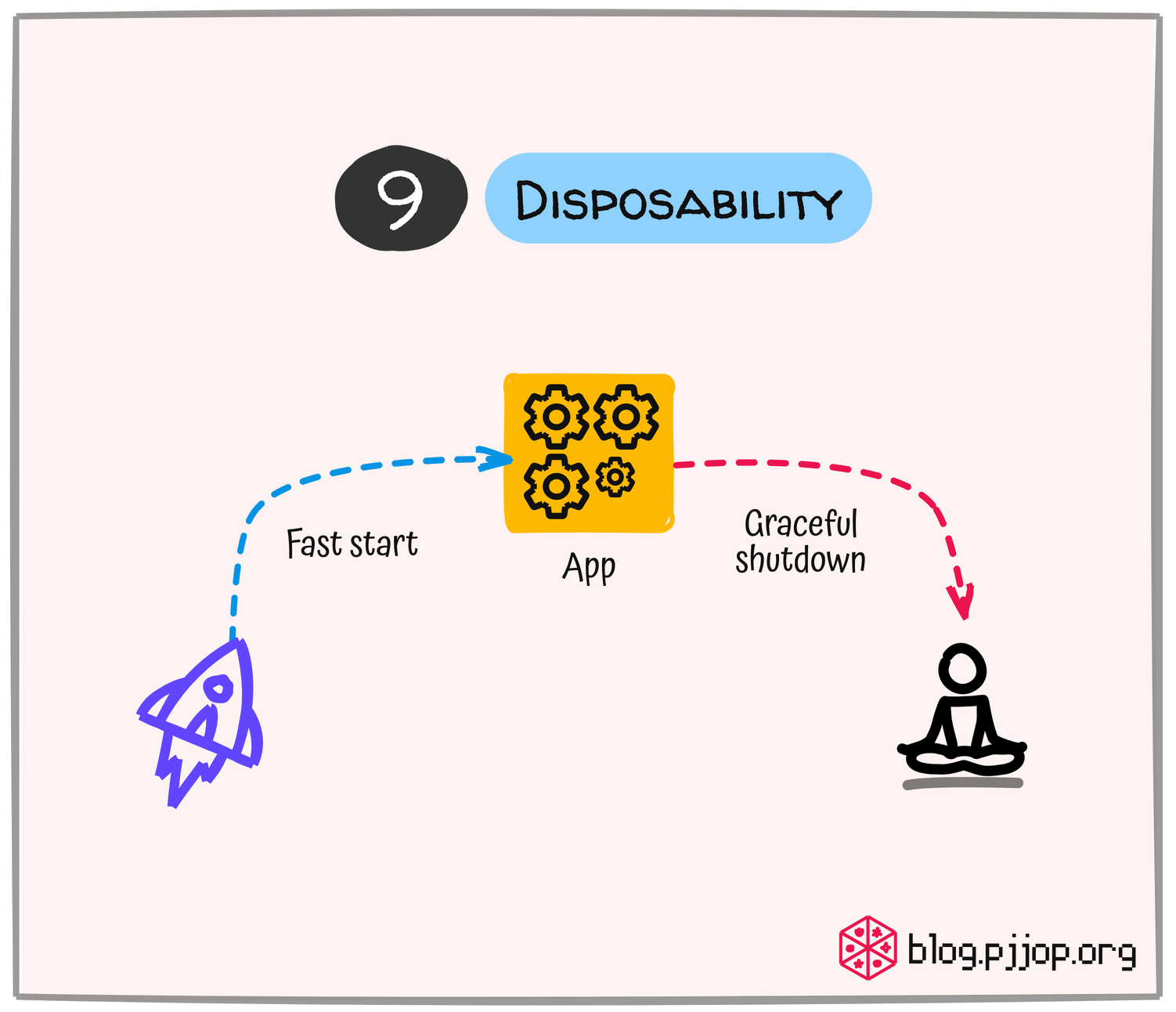
ออกแบบให้ Application สามารถเริ่มทำงานอย่างรวดเร็วภายในไม่กี่วินาที และปิดตัวลงอย่างสง่างาม โดยการรับสัญญาณ SIGTERM (Signal Terminate) แล้วหยุดการทำงานอย่างเป็นระบบ ด้วยการหยุดรับ Request ใหม่ ทำงานเก่าให้เสร็จสิ้น แล้วจึงปิดตัว
Dev/Prod Parity
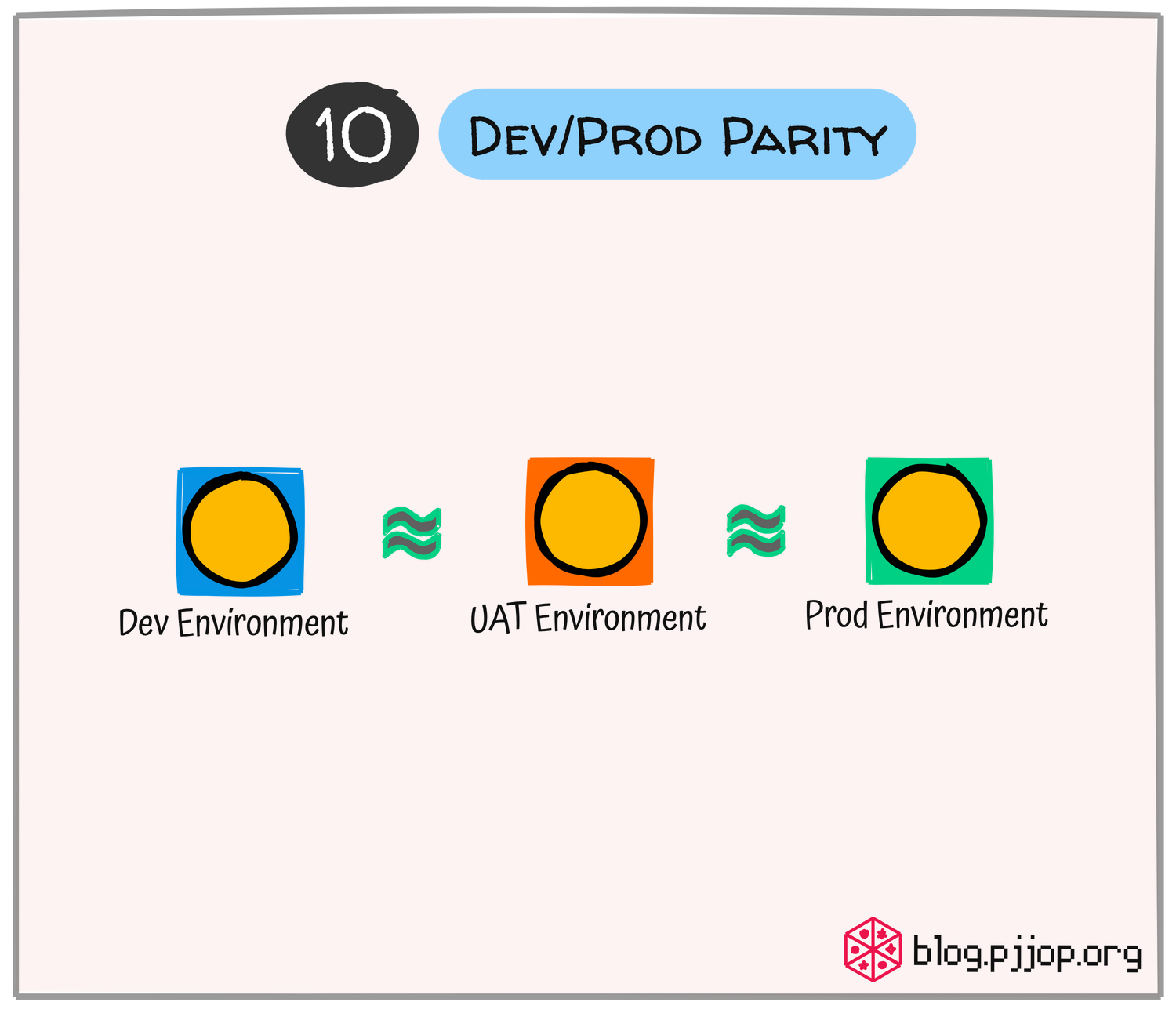
ทำให้มั่นใจว่า Environment ที่ใช้ในการพัฒนา และทดสอบ Application เหมือนกับ Environment ที่ใช้บน Production เพื่อหลีกเลี่ยงความ Surprise ลดปัญหา "Works on my machine"
Logs
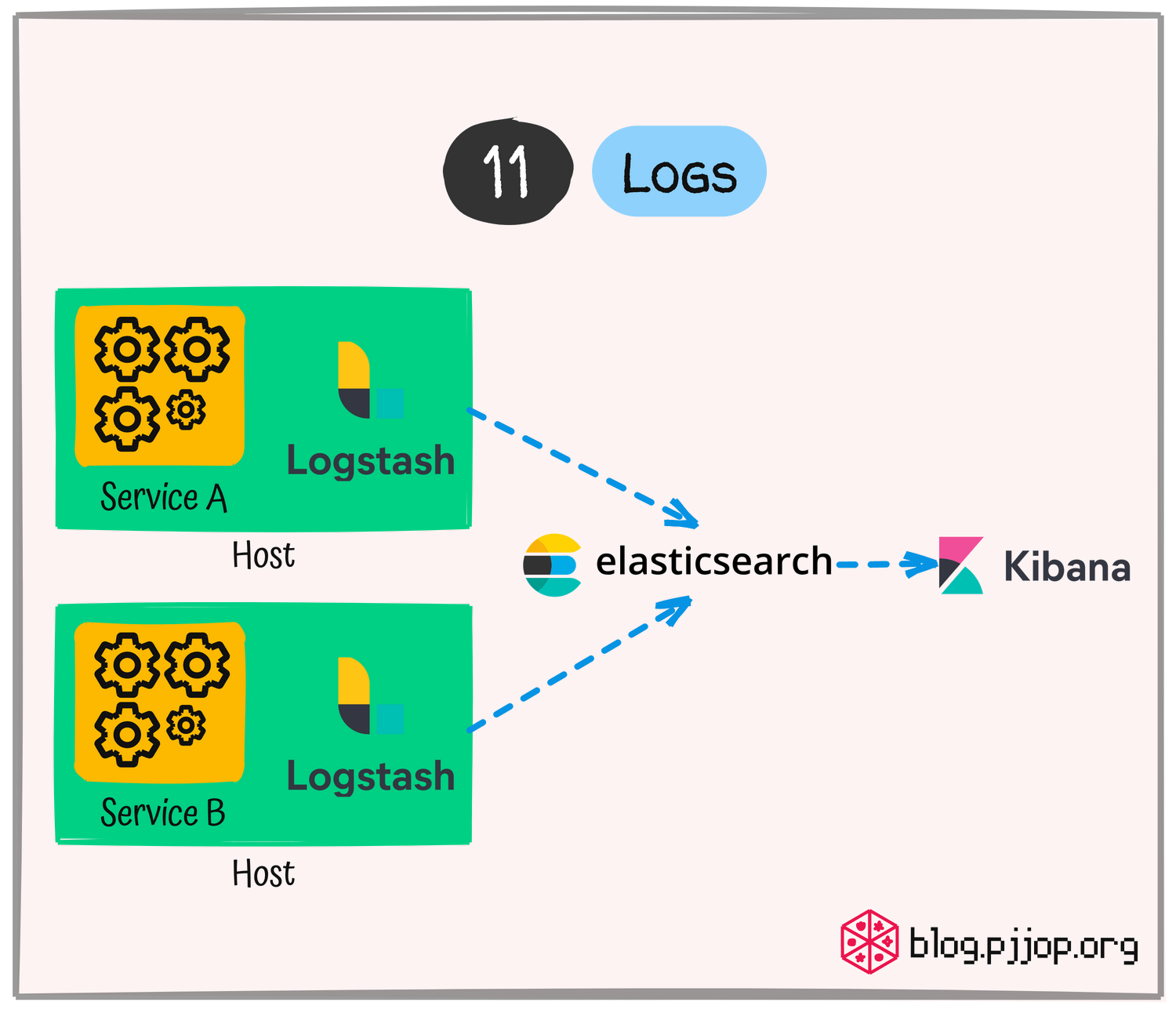
การเก็บบันทึกสิ่งที่เกิดขึ้นใน Application เพื่อให้สามารถเข้าใจและแก้ปัญหาได้ ในระบบที่มีหลาย Process หรือหลาย Service การเก็บ Logs ควรถูกรวมศูนย์ โดยแต่ละ Service ไม่ควรจัดการกับการเก็บ Log เอง
Admin Processes
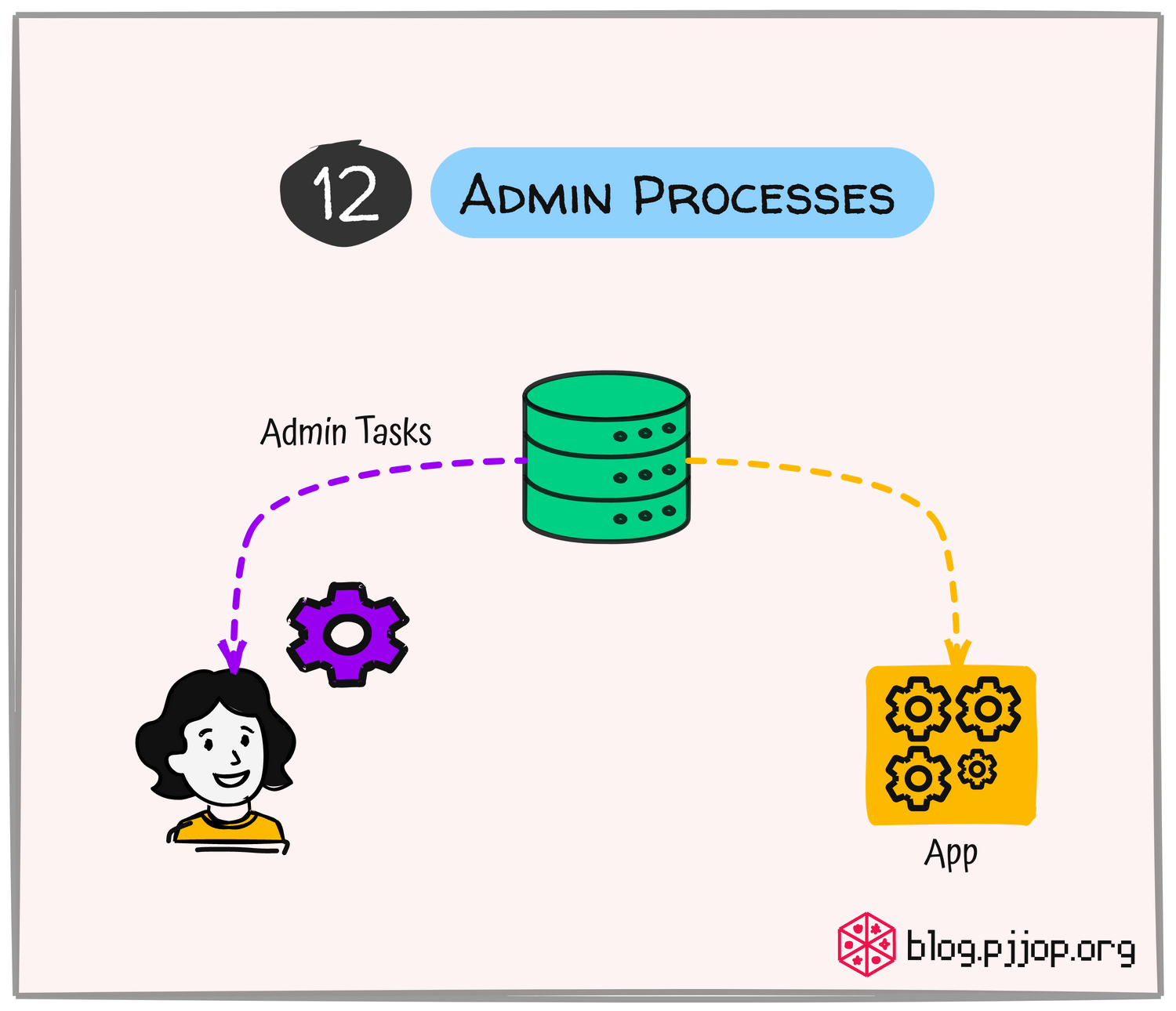
ควรแยกงานพิเศษ เช่น การ Migrate ฐานข้อมูล การทํา Data Cleansing ออกจากการทำงานปกติของ Application แต่เก็บไว้ใน Codebase เดียวกัน และใช้การตั้งค่าแบบเดียวกันกับ Application หลักผ่าน Environment Variable
Single Page Application vs Multi-Page Application
ขณะที่เราสามารถนำหลักการของ 12-Factor App มาประยุกต์ใช้ในการออกแบบ Backend ให้บำรุงรักษาได้ง่าย และสามารถ Scale ได้ Single Page Application (SPA) ก็เป็น Modern Frontend Framework แบบหนึ่ง ที่มีความเข้ากันได้ดีกับ Backend ที่พัฒนาแบบ Microservices เพื่อสร้างแอปพลิเคชันที่มีประสิทธิภาพสูง
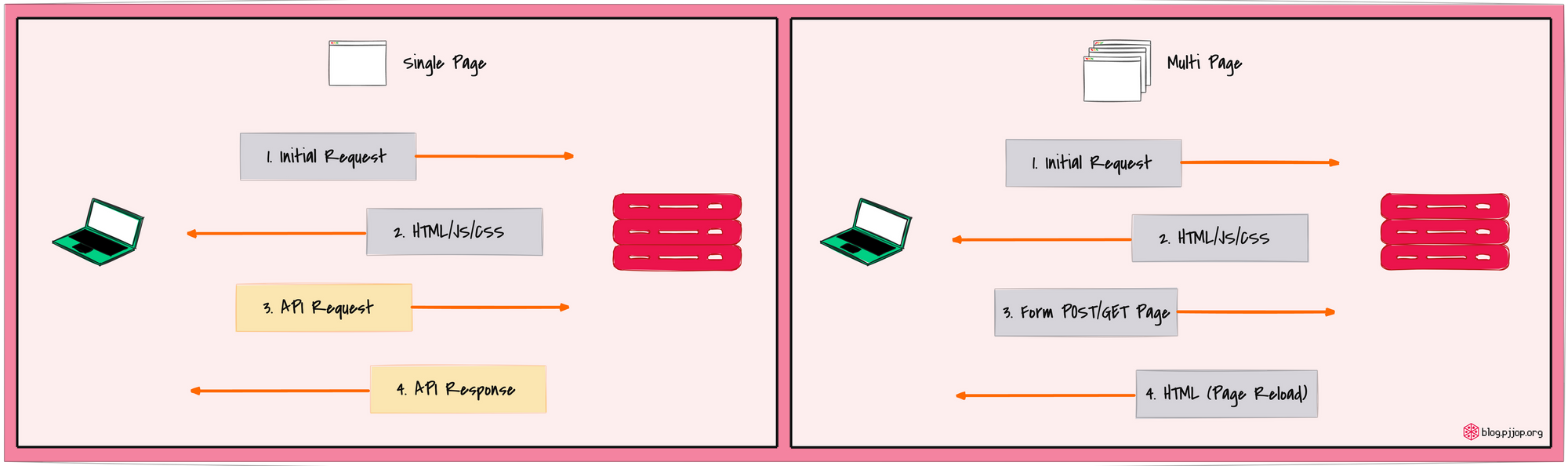
ในช่วงไม่กี่ปีที่ผ่านมา มีการเปลี่ยนแปลงที่สำคัญในวิธีการสร้าง Web Application จาก Multi-Page Application (MPA) ไปสู่ Single Page Application (SPA)
SPA ทำให้ผู้ใช้งานได้รับประสบการณ์ที่ราบรื่นขึ้นโดยการ Update หน้าปัจจุบันแบบ Dynamic แทนที่จะ Load หน้าใหม่ทุกครั้งที่ผู้ใช้มีการโต้ตอบกับ Application
ใน SPA, HTML และ Resource ที่จำเป็นจะถูก Load เพียงครั้งเดียว หลังจากนั้นการโต้ตอบกับ Application จะถูกดำเนินการโดย JavaScript เพื่อจัดการเนื้อหาในหน้าที่ Load ไว้ทีแรก
ขณะที่วิธีการดั้งเดิมแบบ MPA จะต้องมีการ Load หน้า HTML ใหม่ทุกครั้งเมื่อผู้ใช้ Click ที่ Link หรือ Submit Form คำขอข้อมูลในแต่ละครั้งจะต้องมีการ Refresh หน้าทั้งหมด
SPA จะ Load HTML เริ่มต้น แล้วส่งคำขอข้อมูลในรูป JSON เท่าที่จำเป็นผ่าน API ดังนั้น SPA จึงเป็น API-centric ที่มีการแบ่งความรับผิดชอบในการประมวลผลระหว่าง Client และ Server ซึ่งฝั่ง Client มักพัฒนาด้วย JavaScript Frameword เช่น React ขณะที่ MPA มีความเป็น Server-centric ที่เน้นการประมวลผลที่ซับซ้อนในฝั่ง Server ทำให้มีความท้ายมากขึ้นในการ Scale และบำรุงรักษาเมื่อ Application มีความซับซ้อนมากขึ้น
อย่างไรก็ตาม SPA ก็มีข้อจำกัด เช่น ปัญหา SEO หากไม่ใช้ Server-Side Rendering (SSR), Initial Load Time ที่สูง และความซับซ้อนในการพัฒนาและดูแลรักษา Frontend
Multi-Page Application (MPA) ยังคงเหมาะสมกับระบบหลายประเภท โดยเฉพาะระบบที่เน้นความเรียบง่าย ความเสถียร และ SEO บางระบบอาจเลือกใช้แนวทางแบบ Hybrid เช่น MPA ที่สื่อสารผ่าน API
การเลือก SPA หรือ MPA ควรพิจารณาจากลักษณะของระบบ ทีมพัฒนา และข้อจำกัดด้านทรัพยากร มากกว่าการเลือกตามแนวโน้มทางเทคโนโลยี
API First
ในช่วงไม่กี่ปีที่ผ่านมา API First ได้กลายเป็นแนวทางในการพัฒนา Software ยอดนิยม โดยการให้ความสำคัญกับการออกแบบ API ก่อนการออกแบบระบบ และการเขียน Code ซึ่งทีม Frontend Developer, Backend Developer และ QA ฯลฯ จะทำงานร่วมกันเพื่อออกแบบ API ตาม System Requirement
Code First จะเริ่มต้นด้วยการพัฒนา Code การทดสอบและการทำ API Document จะมาทีหลัง โดยจะเป็นการมุ่งเน้นการพัฒนาและการใช้งาน Code เป็นหลัก
API First จะเริ่มต้นด้วยการออกแบบ API โดยมีการ Review และ Mock API ก่อนการพัฒนาจริง การพัฒนา Code จะมาทีหลังหลังจากที่ API ได้รับการออกแบบแล้ว ซึ่งจะเน้นการทำ API Document และการทดสอบ API อย่างละเอียด
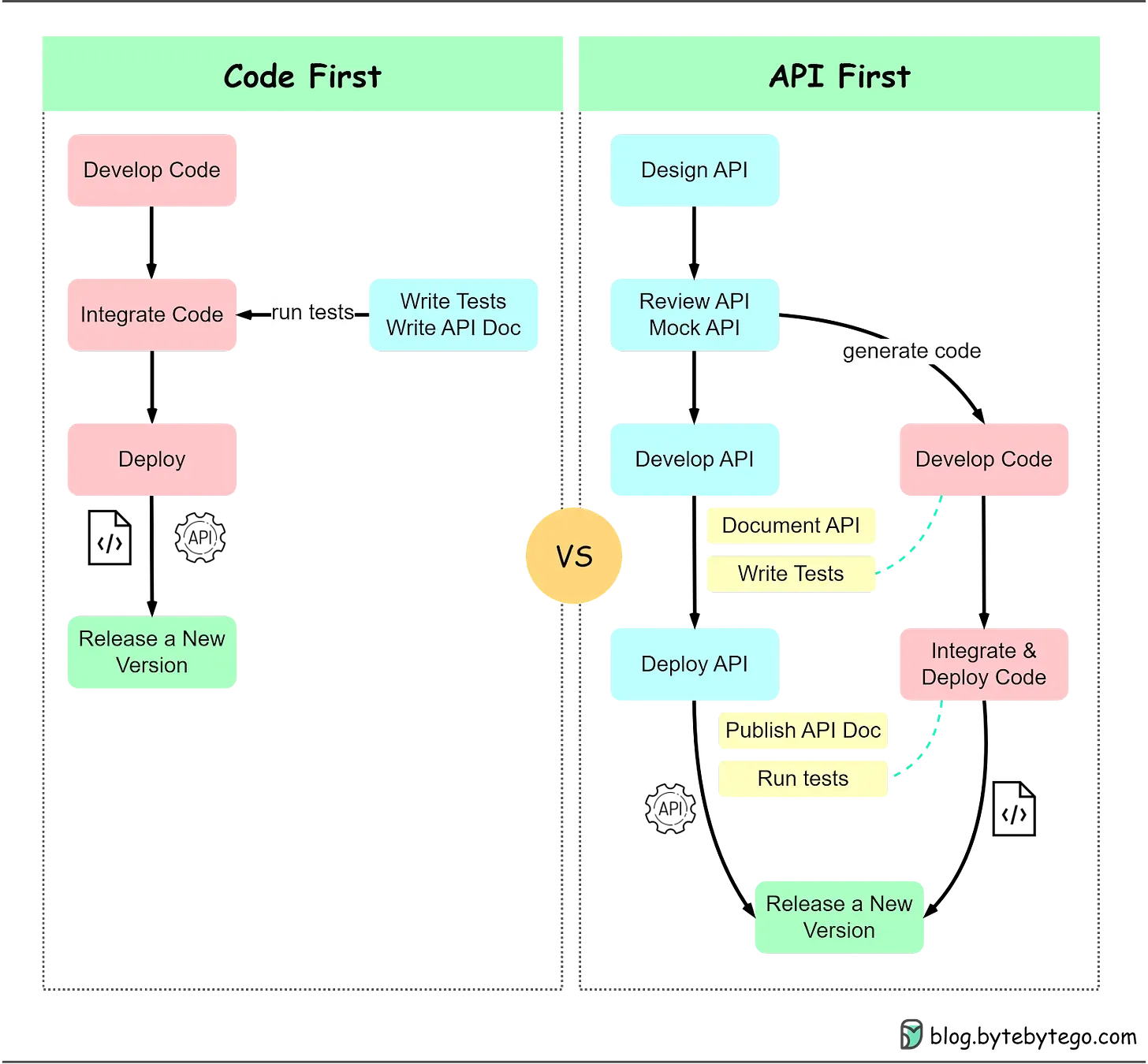
การพัฒนา Application ตามแนวคิด API First จะช่วยให้เราคำนึงถึงปัจจัยสำคัญ ๆ ในการออกแบบ API ที่สามารถ Scale ได้ดีตั้งแต่เริ่มต้น จึงเป็นแนวคิดที่เสริมกันอย่างดีกับการพัฒนาแบบ Single Page Application (SPA)
REST API Design
เมื่อเราพัฒนา Software ฝั่ง Fontend เรามักจะคิดถึงคนธรรมดาที่ไม่มีความเชี่ยวชาญด้านเทคโนโลยีมากนัก โดยการสร้าง Interface ที่เป็นมิตร รับข้อมูลในสิ่งที่ผู้ใช้ต้องการ แต่การพัฒนา API (Application Programming Interfaces) นั้นแตกต่างออกไป เรากําลังสร้าง Interface สําหรับ Programmer ที่มีทักษะ ซึ่งสามารถสังเกตุถึงปัญหาทางเทคนิคเล็ก ๆ น้อย
API มีมานานแล้วในรูปแบบใดรูปแบบหนึ่ง
ในการพัฒนาแบบ API First นั้น REST (Representational State Transfer) เป็นมาตรฐานการสื่อสารที่พบบ่อยที่สุดระหว่างสอง Application หรือ Software ที่ทําหน้าที่แตกต่างกันผ่านเครือข่าย เพื่อให้เชี่ยวชาญในการสร้าง REST API เราต้องปฏิบัติตามแนวทางบางประการเพื่อให้แน่ใจว่าเราได้ออกแบบ API ที่มีประสิทธิภาพและใช้งานง่าย
หลักการสำคัญของ REST คือ
ใช้ HTTP (Hypertext Transfer Protocol) ในการสื่อสาร
HTTP เป็น Stateless Protocol ที่ Request แต่ละรายการเป็นอิสระต่อกัน โดย Server จะไม่เก็บข้อมูลใด ๆ เกี่ยวกับ Request ก่อนหน้า
HTTP Request แต่ละรายการประกอบด้วย Method เช่น GET, POST, PUT, DELETE, Header และ Body ที่เป็น Option สำหรับบรรจุข้อมูล
HTTP Response จะประกอบไปด้วย Status Code, Header, และ Body ที่เป็น Option สำหรับบรรจุข้อมูลเช่นกัน
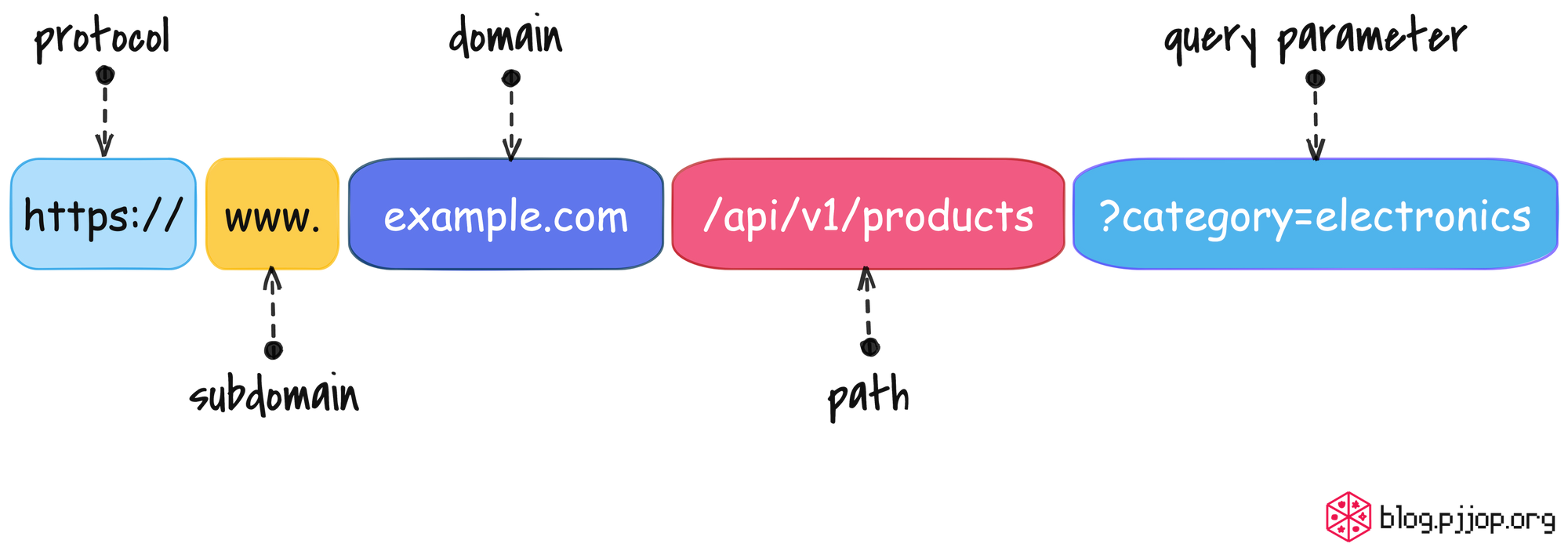
ใช้ URL (Uniform Resource Locator) ในการเข้าถึง Resource ต่าง ๆ
URL คือที่อยู่ที่ใช้เพื่อเข้าถึง Resource บนเว็บ
ใช้สถาปัตยกรรมการสื่อสารแบบ Client-Server
Client จะส่งคําขอไปยัง Server จากนั้น Server จะประมวลผล Request และส่งการตอบกลับมายัง Client โดย Client จะดูแลการนําเสนอสำหรับ User Interface ในขณะที่ Server จัดการ Business Logic การประมวลผลข้อมูล และการจัดเก็บข้อมูล
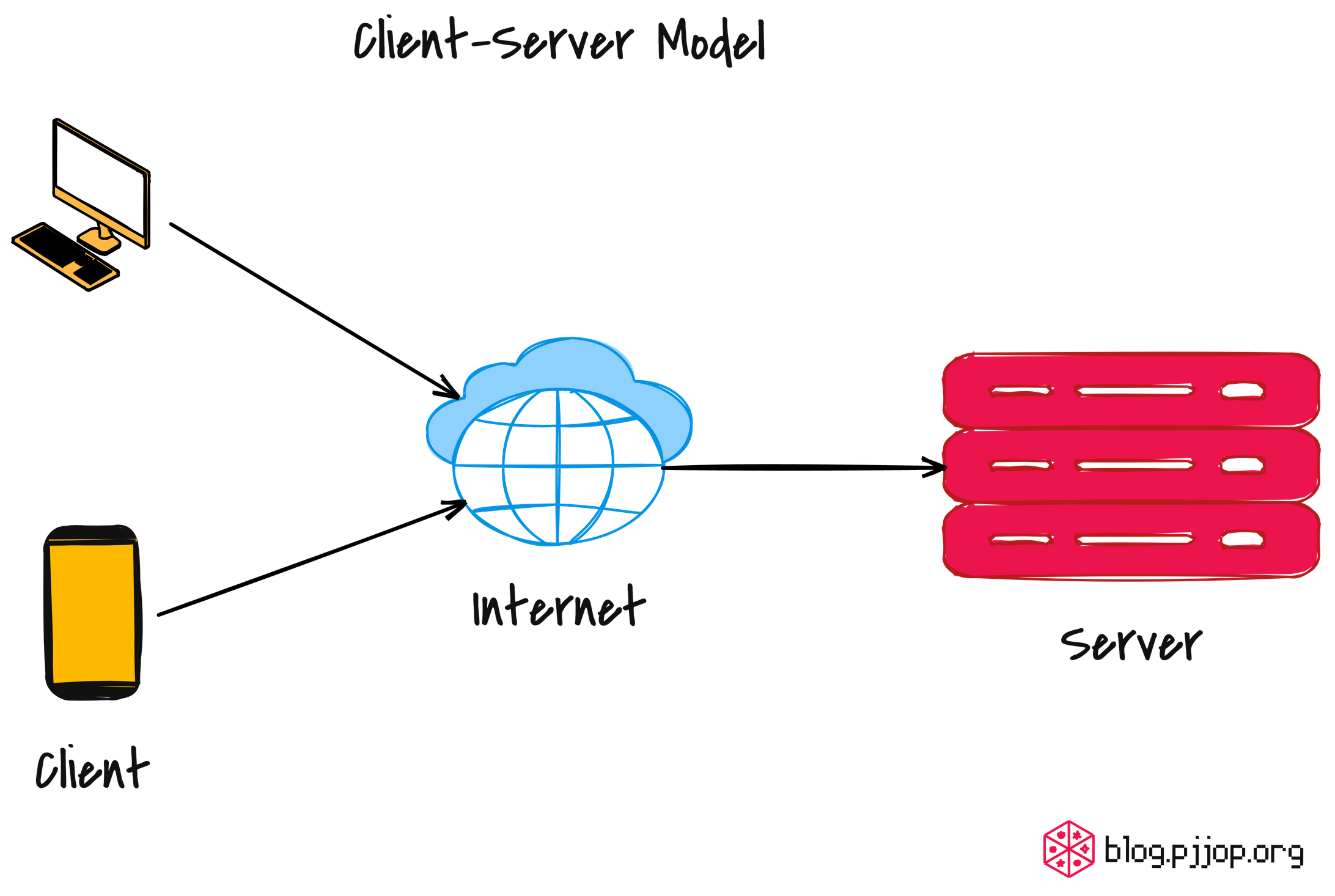
แนวคิดหลักของ REST คือ Resource
Resource คือ Information ที่สามารถตั้งชื่อและเข้าถึงได้ผ่าน URL ซึ่งแต่ละ Resource จะถูกกำหนดโดย URL ที่ไม่ซ้ำกัน (Resource Endpoint) โดยอาจจะเป็น User, Product หรือ Order ฯลฯ และถูกส่งกลับในรูปแบบ JSON
ใน REST API ส่วนของ Client จะโต้ตอบกับ Resource โดยการ Create, Update หรือ Delete โดยการส่ง HTTP Request ที่เหมาะสมไปยัง URL ที่เกี่ยวข้อง
Resource Endpoint จะต้องเป็นคำนาม ไม่ใช่คำกิริยา ยกตัวอย่างเช่น /users แทนที่จะใช้ /getUsers หรือ /createUser
ให้ใช้คํานามพหูพจน์ เช่น /products หรือ /users แทนที่จะเป็น /product หรือ /user (แม้ว่าการใช้คำนามพหูพจน์จะเป็นแนวปฏิบัติที่พบบ่อย แต่ไม่ได้เป็นกฎตายตัว)
ใช้ Path แบบลำดับชั้น ที่แสดงความสัมพันธ์ของ Resource ยกตัวอย่างเช่น /orders/123/items
ใช้ - เพื่อแยกคํา หากชื่อ Resource ประกอบด้วยหลายคํา ตัวอย่างเช่น /product-categories หรือ /user-profiles
ใช้ตัวพิมพ์เล็กทั้งหมด เพื่อรักษาความสอดคล้องและหลีกเลี่ยงความสับสน
ตัวอย่าง URL ของ Resource ต่าง ๆ
/users
แทนกลุ่มข้อมูลผู้ใช้
/users/123
แทนข้อมูลของผู้ใช้ที่มี ID 123
/products
แทนกลุ่มข้อมูลสินค้า
/orders/123/items
แทนกลุ่มข้อมูลสินค้าที่อยู่ในคำสั่งซื้อหมายเลข 123
/categories
แทนกลุ่มข้อมูลประเภทสินค้า
/categories/xyz/products
แทนกลุ่มข้อมูลสินค้าตามประเภท xyz ที่ระบุ
การใช้ HTTP Method ที่เหมาะสมใน REST API
ในการพัฒนา Application เรามักใช้หลักการแยกส่วน (Separation of Concern) ซึ่งแนะนำให้นักพัฒนาแยกชั้นของ Application เป็น Web Service Layer ซึ่งรับผิดชอบในการจัดการคําขอเว็บ (Route และ Handler Function) และ Service Layer ซึ่งรับผิดชอบ Core Business Logic ต่าง ๆ เช่น การโต้ตอบกับ Database การจัดการ Message Queue และการสื่อสารกับ Service อื่น ๆ
ที่ Web Service Layer เราจะใช้ HTTP Verb (Method) หลัก ๆ ได้แก่ GET, PUT, POST, DELETE และ PATCH เพื่อกําหนดการดําเนินการที่เราสามารถทำได้กับ Resource ต่าง ๆ ขณะที่ใน Service Layer เราใช้การดําเนินการ CRUD (Create, Read, Update, Delete) ในการจัดการกับ Business Logic จริง ๆ
โดย GET จะถูกใช้เพื่อดึง Resource ต่าง ๆ และ PUT ถูกใช้สำหรับการ Update แบบแทนที่ Resource ทั้งหมด ขณะที่ PATCH จะถูกใช้สำหรับการ Update Resource บางส่วน
ส่วน POST จะถูกใช้สำหรับสร้าง Resource ใหม่ และ DELETE สำหรับลบ Resource ที่มีอยู่
GET
- สำหรับดึง Resource ต่าง ๆ
- ตัวอย่างเช่น GET /users/123
- ไม่มี Request Body
- มี Response Body เช่น
{
"id": 123,
"name": "สมชาย ใจดี",
"email": "[email protected]",
"phone": "081-234-5678",
"address": {
"street": "123 ถนนหลัก",
"city": "กรุงเทพมหานคร",
"zip": "10100"
}
}- สามารถ Cache ได้ (แต่ไม่ได้หมายความว่าทุก GET Request ควรถูก cache เสมอไป)
- ทำซ้ำได้โดยให้ผลลัพธ์เหมือนเดิม (Idempotent)
- Service Layer Method เช่น get() และ list()
PUT
- สำหรับการ Update แบบแทนที่ Resource ทั้งหมด
- ตัวอย่างเช่น PUT /users/123
- มี Request Body เช่น
{
"id": 123,
"name": "ณัฐโชติ พรหมฤทธิ์",
"email": "[email protected]",
"phone": "081-234-5678",
"address": {
"street": "123 ถนนหลัก",
"city": "กรุงเทพมหานคร",
"zip": "10100"
}
}- อาจมี Response Body
- ไม่สามารถ Cache ได้
- ทำซ้ำได้โดยให้ผลลัพธ์เหมือนเดิม (Idempotent)
- Service Layer Method เช่น update()
POST
- สำหรับสร้าง Resource ใหม่
- ตัวอย่างเช่น POST /users
- มี Request Body เช่น
{
"name": "สัจจาภรณ์ ไวจรรยา",
"email": "[email protected]",
"phone": "095-277-5111",
"address": {
"street": "123 ถนนหลัก",
"city": "กรุงเทพมหานคร",
"state": "กรุงเทพ",
"zip": "10100"
}
}- มี Response Body เช่น
{
"id": 987,
"name": "สมชาย ใจดี",
"email": "[email protected]",
"phone": "095-277-5111",
"address": {
"street": "123 ถนนหลัก",
"city": "กรุงเทพมหานคร",
"zip": "10100"
},
"created_at": "2024-08-28T16:00:00Z",
"updated_at": "2024-08-28T16:00:00Z"
}- ไม่สามารถ Cache ได้
- ทำซ้ำแล้วอาจให้ผลลัพธ์ต่างออกไป เนื่องจาก POST ถูกออกแบบมาเพื่อใช้ในการสร้าง Resource ใหม่ การทำคำขอซ้ำอาจสร้าง Resource ใหม่ที่มีรหัสไม่เหมือนเดิม
- Service Layer Method เช่น create()
DELETE
- สำหรับการลบ Resource
- ตัวอย่างเช่น DELETE /user/123
- อาจมี Request Body
- อาจมี Response Body
- ไม่สามารถ Cache ได้
- ทำซ้ำได้โดยให้ผลลัพธ์เหมือนเดิม (Idempotent)
- Service Layer Method เช่น delete()
PATCH
- สำหรับการ Update Resource บางส่วน
- ตัวอย่างเช่น PATCH /users/123
- มี Request Body
{
"email": "[email protected]"
}- มี Response Body
{
"id": 123,
"name": "ณัฐโชติ พรหมฤทธิ์",
"email": "[email protected]",
"created_at": "2023-01-01T12:00:00Z",
"updated_at": "2024-08-28T15:00:00Z"
}- ไม่สามารถ Cache ได้
- ทำซ้ำแล้วอาจให้ผลลัพธ์ต่างออกไป เพราะการ Update อาจขึ้นอยู่กับค่าปัจจุบันใน Resource นั้น เช่น การเพิ่มค่า (Increment) ใน Field จำนวน หรือการ Update Field ที่ต้องขึ้นอยู่กับเงื่อนไขเฉพาะ ถ้า Resource มีการเปลี่ยนแปลงในระหว่างการทำคำขอครั้งแรกและครั้งที่สองผลลัพธ์ที่ได้อาจแตกต่างกัน
- Service Layer Method เช่น update()
API Design Best Practices
1. API Versioning
เมื่อเราต้องมีการเพิ่มคุณสมบัติใหม่ ๆ ให้กับ API แก้ไขปัญหาที่มีอยู่ หรือต้องเปลี่ยนวิธีการทํางานของ API เราจําเป็นต้องดำเนินการโดยไม่รบกวนผู้ใช้ของเรา การสร้าง Version ของ API ที่ชัดเจนและเข้าใจง่ายจะหลีกเลี่ยงความสับสนให้กับนักพัฒนา
หากเราเปลี่ยนชื่อ Field เดิมโดยไม่มีระบบ Version แล้ว Application ที่เรียกใช้ API อาจหยุดทํางานหรือมีการแสดงข้อผิดพลาด เพื่อรักษาความเข้ากันได้กับ Application ที่ใช้ API Version เก่า เราต้องขอให้นักพัฒนาเลือกเวลาที่จะ Update Application ให้สามารถทํางานกับ API Version ใหม่
เราอาจเพิ่มหมายเลข Version เป็นส่วนหนึ่งของ URL ได้ ซึ่งทำให้ง่ายต่อการตรวจสอบและแก้ไขข้อผิดพลาด เนื่องจากเราจะเห็น Version ได้ชัดเจนใน URL
ตำแหน่งของ Version อาจอยู่ก่อนชื่อ Resource หรือหลังชื่อ Resource เช่น
อยู่ก่อนชื่อ Resource เมื่อต้องการใช้ Version กับ API หลายตัวพร้อมกัน
https://myapi.com/api/v1/usersอยู่หลังชื่อ Resource เมื่อต้องการกำหนด Version เฉพาะสำหรับบาง Resource
https://myapi.com/api/users/v1ระบบการกำหนด Version ของ API อีกแบบหนึ่งคือ Semantic Versioning Specification (SemVer) ประกอบด้วย 3 ส่วนหลัก ตัวอย่างเช่น Version 3.0.0

Major คือ Version หลัก
Minor คือ Version รอง
Patch คือ Version แก้ไขย่อย
การ Update Major Version ใช้เมื่อมีการเปลี่ยนแปลงที่ทำให้เกิดความไม่เข้ากันกับเวอร์ชันเก่า (Breaking Change) เช่นจาก 3.0.0 เป็น 4.0.0
การ Update Minor Version ใช้เมื่อเราเพิ่ม Feature ใหม่ที่ยังคงมีความเข้ากันได้กับ Version เก่า (Backward Compatible Feature) เช่นจาก 3.0.0 เป็น 3.1.0
การ Update Patch ใช้สำหรับการแก้ไขข้อบกพร่องที่ยังคงความเข้ากันได้กับ Version เก่า (Backward Compatible Defect Fix) เช่นจาก 3.1.0 เป็น 3.1.1
หมายเหตุ SemVer ถูกออกแบบมาสำหรับการทำ Version ของ Software Library และ OS มากกว่า API โดยทั่วไป การใช้ Major Version เช่น v1 และ v2 ก็อาจเพียงพอและง่ายกว่าในการใช้งาน
2. Pagination
ในการออกแบบ API การแบ่งหน้า (Pagination) เป็นสิ่งสำคัญสำหรับจัดการกับ Resource ขนาดใหญ่
ตัวอย่างเทคนิคการแบ่งหน้า 3 แบบ ได้แก่ Offset-based, Cursor-based และ Page-based
Offset-based
ใช้ Parameter "offset" และ "limit" เพื่อกำหนดจุดเริ่มต้นและจำนวนรายการที่ต้องการ เช่น GET /api/v1/products?offset=0&limit=2
offset คือ ตำแหน่งเริ่มต้นของ Resource ที่ได้จากการ Query ที่ต้องการ (offset=0 หมายถึงเริ่มจากรายการแรก)
limit คือ จำนวนรายการที่ต้องการ
ตัวอย่างข้อมูลสินค้า
id 1001, name "โน้ตบุ๊ก A", price 30000
id 1002, name "สมาร์ทโฟน B", price 15000
id 1003, name "แท็บเล็ต C", price 20000
id 1004, name "หูฟัง D", price 5000
id 1005, name "กล้อง E", ราคา: 25000
เรียกครั้งแรก GET /api/v1/products?offset=0&limit=2
{
"products": [
{"id": 1001, "name": "โน้ตบุ๊ก A", "price": 30000},
{"id": 1002, "name": "สมาร์ทโฟน B", "price": 15000}
],
"total": 5,
"next_offset": 2
}เรียกครั้งที่สอง GET /api/v1/products?offset=2&limit=2
{
"products": [
{"id": 1003, "name": "แท็บเล็ต C", "price": 20000},
{"id": 1004, "name": "หูฟัง D", "price": 5000}
],
"total": 5,
"next_offset": 4
}เรียกครั้งที่สาม GET /api/v1/products?offset=4&limit=2
{
"products": [
{"id": 1005, "name": "กล้อง E", "price": 25000}
],
"total": 5,
"next_offset": null
}ข้อดี ง่ายต่อการเข้าใจและใช้งาน
ข้อเสีย อาจไม่มีประสิทธิภาพสำหรับ offset ขนาดใหญ่
Cursor-based
ใช้ตัวชี้ (cursor) เป็นตัวระบุตำแหน่งใน Resource มักเป็นค่าที่ไม่ซ้ำกัน เช่น ID ของรายการสุดท้ายในหน้าปัจจุบัน เช่น GET /api/v1/products?limit=2&cursor=1004
limit คือ จำนวนรายการต่อหน้า
cursor คือ ตำแหน่งใน Resource มักเป็นค่าที่ไม่ซ้ำกัน
เรียกครั้งแรก GET /api/v1/products?limit=2
{
"products": [
{"id": 1001, "name": "โน้ตบุ๊ก A", "price": 30000},
{"id": 1002, "name": "สมาร์ทโฟน B", "price": 15000}
],
"next_cursor": "1002"
}เรียกครั้งที่สอง: GET /api/v1/products?limit=2&cursor=1002
{
"products": [
{"id": 1003, "name": "แท็บเล็ต C", "price": 20000},
{"id": 1004, "name": "หูฟัง D", "price": 5000}
],
"next_cursor": "1004"
}เรียกครั้งที่สาม: GET /api/v1/products?limit=2&cursor=1004
{
"products": [
{"id": 1005, "name": "กล้อง E", "price": 25000}
],
"next_cursor": null
}ข้อดี มีประสิทธิภาพสำหรับชุดข้อมูลขนาดใหญ่
ข้อเสีย ซับซ้อนกว่าในการใช้งานและพัฒนา
Page-based
ใช้การระบุหมายเลขหน้าและขนาดของแต่ละหน้า เช่น GET /api/v1/products?page=1&pageSize=2
page คือ หมายเลขหน้าที่ต้องการ (เริ่มจาก 1)
pageSize คือ จำนวนรายการต่อหน้า
เรียกหน้าแรก: GET /api/v1/products?page=1&pageSize=2
{
"products": [
{"id": 1001, "name": "โน้ตบุ๊ก A", "price": 30000},
{"id": 1002, "name": "สมาร์ทโฟน B", "price": 15000}
],
"currentPage": 1,
"totalPages": 3,
"totalItems": 5
}เรียกหน้าที่สอง: GET /api/v1/products?page=2&pageSize=2
{
"products": [
{"id": 1003, "name": "แท็บเล็ต C", "price": 20000},
{"id": 1004, "name": "หูฟัง D", "price": 5000}
],
"currentPage": 2,
"totalPages": 3,
"totalItems": 5
}เรียกหน้าสุดท้าย: GET /api/v1/products?page=3&pageSize=2
{
"products": [
{"id": 1005, "name": "กล้อง E", "price": 25000}
],
"currentPage": 3,
"totalPages": 3,
"totalItems": 5
}ยกตัวอย่างการคำนวน totalPages
totalItems = 5 (จำนวนสินค้าทั้งหมด)
pageSize = 2 (จำนวนรายการต่อหน้า)
totalPages = Math.ceil(5/2) = Math.ceil(2.5) = 3
ข้อดี ง่ายต่อการใช้งานและพัฒนา
ข้อเสีย อาจมีปัญหาประสิทธิภาพสำหรับหมายเลขหน้าที่สูง
3. Filtering
ในการออกแบบ API ที่ดีเราควรมีการกรองข้อมูล เพื่อให้ผู้ใช้สามารถเลือกข้อมูลตามเงื่อนไขที่ต้องการ ซึ่งจะช่วยลดปริมาณข้อมูลที่ส่งกลับ เช่น
GET /api/v1/products?category=electronics&price_min=1000&price_max=5000&location=bangkok
4. Sorting
เช่นเดียวกับการทำ Filtering เราควรใช้การ Sorting เพื่อให้ผู้ใช้สามารถจัดเรียงข้อมูลตามเงื่อนไขที่กำหนด เช่น
GET /api/v1/products?sort_by=price&order=desc
ผลลัพธ์จากการใช้ Sorting
{
"products": [
{"id": 1001, "name": "โน้ตบุ๊ก A", "price": 30000},
{"id": 1005, "name": "กล้อง E", "price": 25000},
{"id": 1003, "name": "แท็บเล็ต C", "price": 20000},
{"id": 1002, "name": "สมาร์ทโฟน B", "price": 15000},
{"id": 1004, "name": "หูฟัง D", "price": 5000}
]
}5. Error Handling
การจัดการข้อผิดพลาด (Error Handling) เป็นส่วนสำคัญในการสร้าง API ที่มีความปลอดภัยและให้ประสบการณ์ผู้ใช้ที่ดี การจัดการข้อผิดพลาดที่เหมาะสมจะช่วยให้นักพัฒนาเข้าใจปัญหาได้ดีขึ้นโดยไม่เปิดเผยข้อมูลที่อาจเป็นอันตราย
เราควรส่งคืนข้อความข้อผิดพลาดด้วย HTTP Status Code และรายละเอียดเพิ่มเติม เช่น
HTTP Status Code
400 : Bad Reques ใช้เมื่อข้อมูลที่ส่งมามีรูปแบบไม่ถูกต้องหรือมีข้อมูลที่ไม่ครบถ้วน
401 : Unauthorized ใช้เมื่อผู้ใช้ยังไม่ได้มีการ Authen ที่ถูกต้อง
403 : Forbidden ใช้เมื่อผู้ใช้ไม่มีสิทธิ์ในการเข้าถึง Resource ที่ร้องขอ
404 : Not Found เมื่อไม่พบ Resource ที่ร้องขอ
500 : Internal Server Error ใช้เมื่อเกิดข้อผิดพลาดภายใน Server
กลุ่มของ HTTP Status Code ที่มักใช้กันบ่อย ๆ
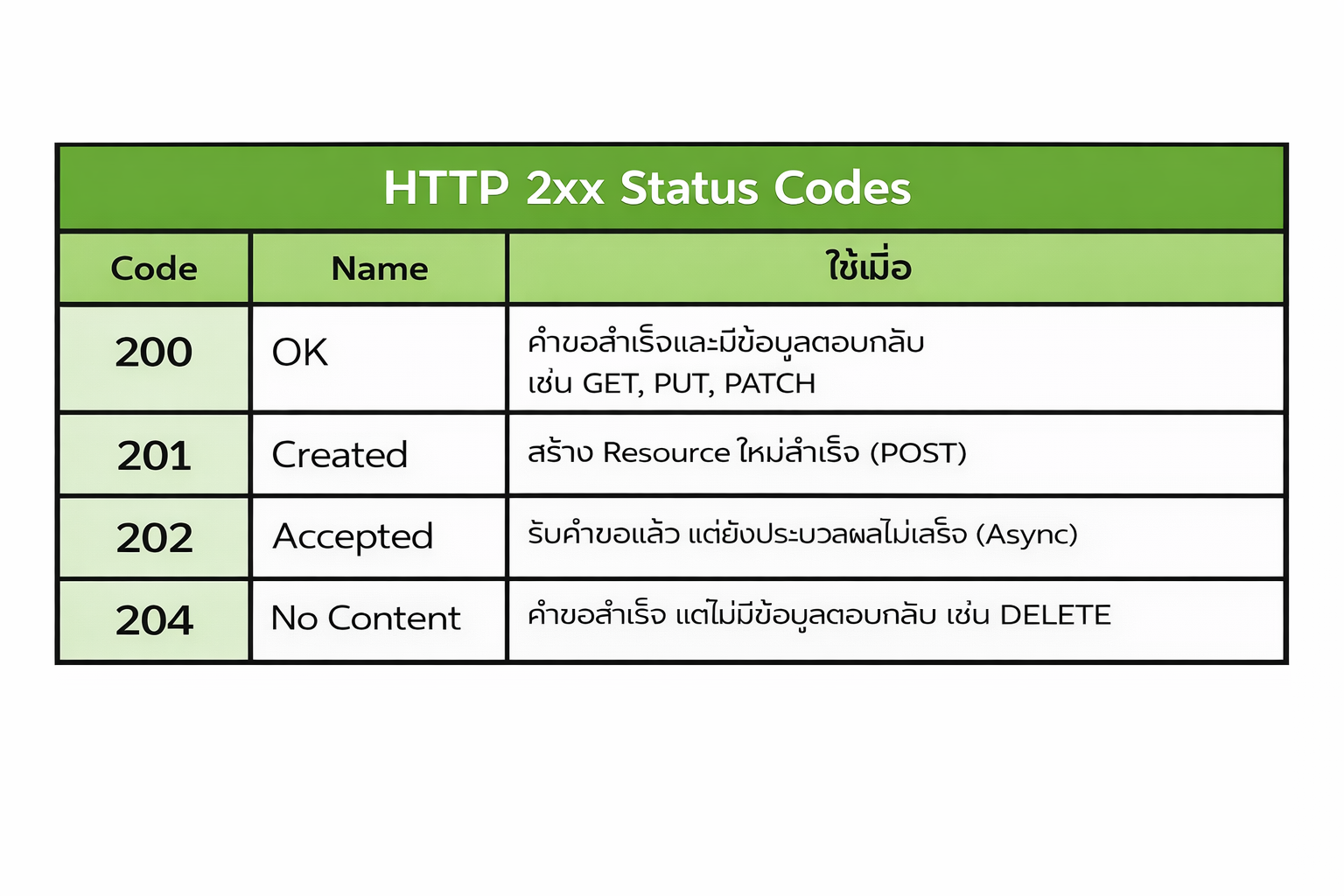
2xx - Acknowledge and Success ใช้เมื่อคำขอประสบความสำเร็จ
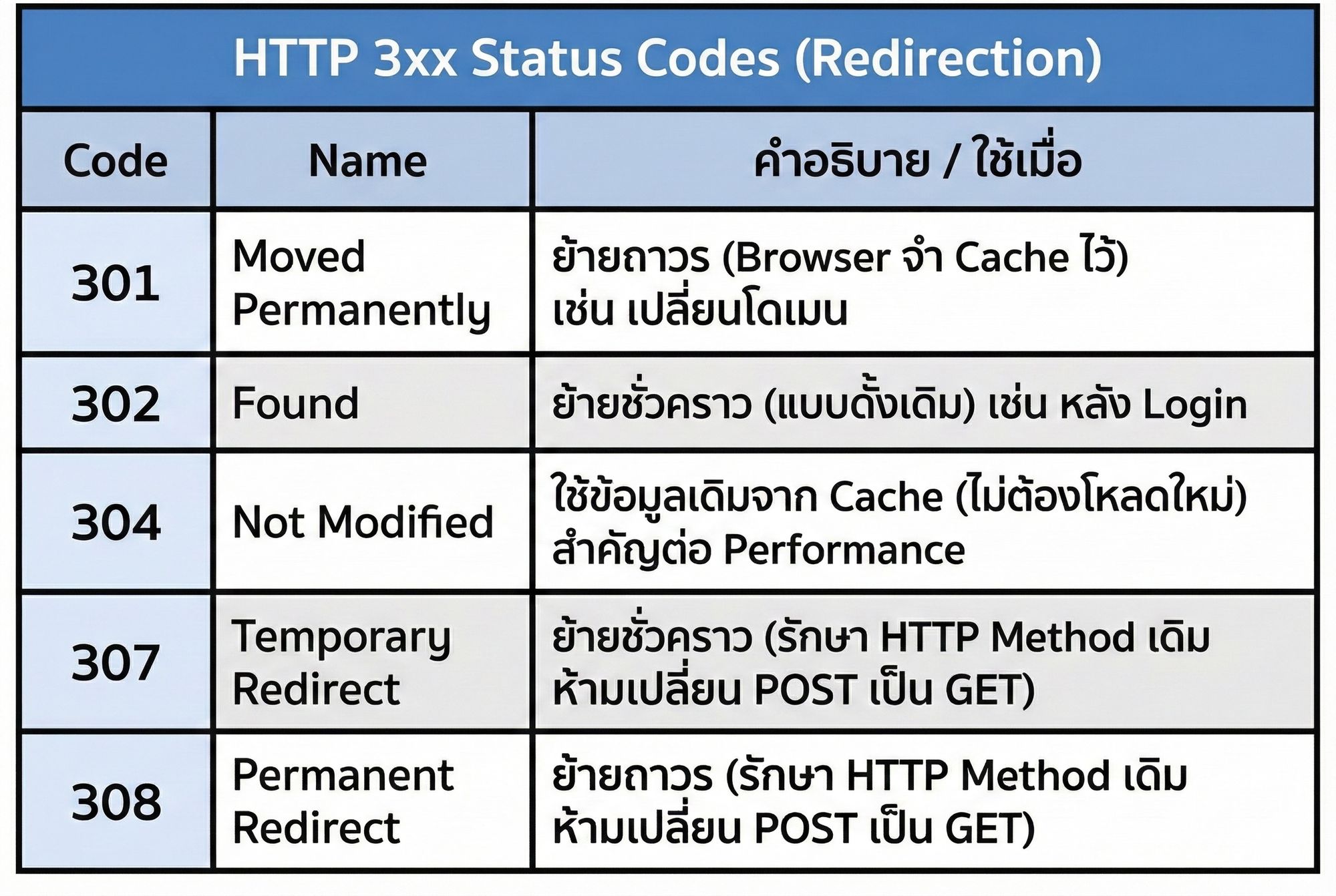
3xx - Redirection ใช้เมื่อต้องมีการดำเนินการเพิ่มเติมเพื่อให้คำขอสมบูรณ์
4xx - Client Error ใช้เมื่อคำขอมีข้อผิดพลาดหรือไม่สามารถดำเนินการได้เนื่องจากปัญหาจากฝั่ง Client

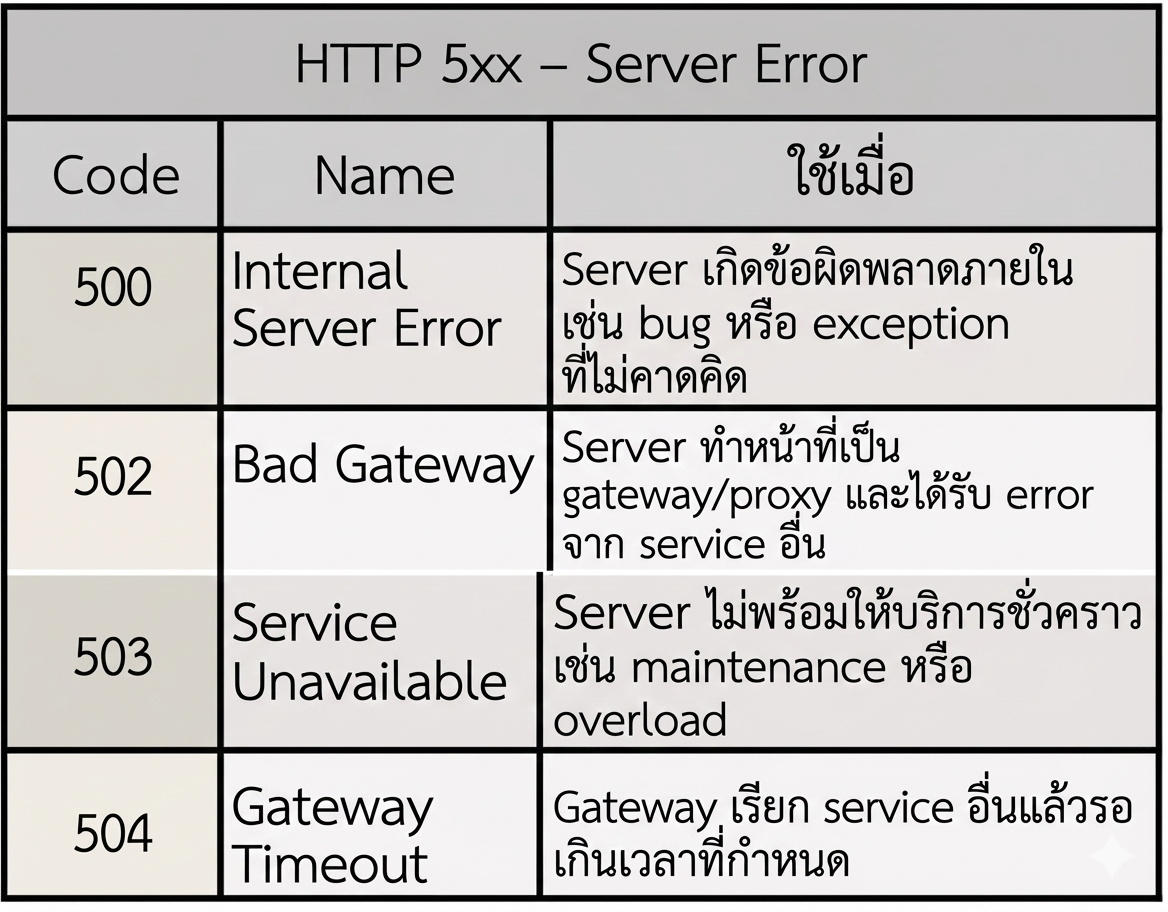
5xx - Server Error ใช้เมื่อ Server ไม่สามารถดำเนินการตามคำขอที่มาอย่างถูกต้องได้
รายละเอียดเพิ่มเติมที่ส่งไปพร้อมกับ HTTP Status Code
เราควรให้ข้อมูลที่ชัดเจนเพียงพอให้นักพัฒนาสามารถแก้ไขปัญหาได้ แต่ไม่ควรเปิดเผยข้อมูลภายใน ที่อาจเสี่ยงต่อความมั่นคงปลอดภัย เช่น แทนที่จะบอกว่า "Internal Server Error" ควรใช้ข้อความเช่น "Access denied. Check credentials and permissions." ซึ่งให้ข้อมูลเพียงพอแก่นักพัฒนาโดยไม่เปิดเผยข้อมูลภายในระบบ
รวมทั้งไม่ควรแสดงรายละเอียดที่อาจทำให้ระบบถูกโจมตีได้ เช่นไม่ควรบอกว่า "SQL query failed due to malformed input containing a DROP TABLE command" แต่ควรใช้ข้อความทั่วไปเช่น "Invalid input provided. Please review and try again."
6. API Spec
API Spec คือ เอกสารที่อธิบายรายละเอียดของ API อย่างเป็นทางการ API Spec ช่วยให้นักพัฒนาเข้าใจวิธีการใช้งาน API ได้อย่างถูกต้อง ทำให้การพัฒนาและการทดสอบมีประสิทธิภาพมากขึ้น โดยเฉพาะ Project ที่มีทีมพัฒนาหลายทีม หรือ Project ที่ต้องมีการจ้างทีม Outsource

Post-test (25 ข้อ) ขอให้สนุกกับการทำ Post-test นะครับ!