Introduction to Deep Reinforcement Learning on Google Colab Pro


บทความโดย ผศ.ดร.ณัฐโชติ พรหมฤทธิ์
ภาควิชาคอมพิวเตอร์
คณะวิทยาศาสตร์
มหาวิทยาลัยศิลปากร
ปี 2013 บริษัทสตาร์ทอัพในลอนดอนชื่อ DeepMind ได้ตีพิมพ์ Paper ชื่อ Playing Atari with Deep Reinforcement Learning ซึ่งแสดงให้เห็นว่า AI Agent สามารถควบคุมการเล่นเกมอย่างเช่น Breakout, Enduro และ Pong จนเอาชนะมนุษย์ได้เพียงแค่รับ Input เป็น Screen Pixel ในการฝึกสอน โดยในขณะที่ฝึกจะมีการให้รางวัล (Reward) เพื่อให้ AI เรียนรู้ว่ามันทำได้ดี
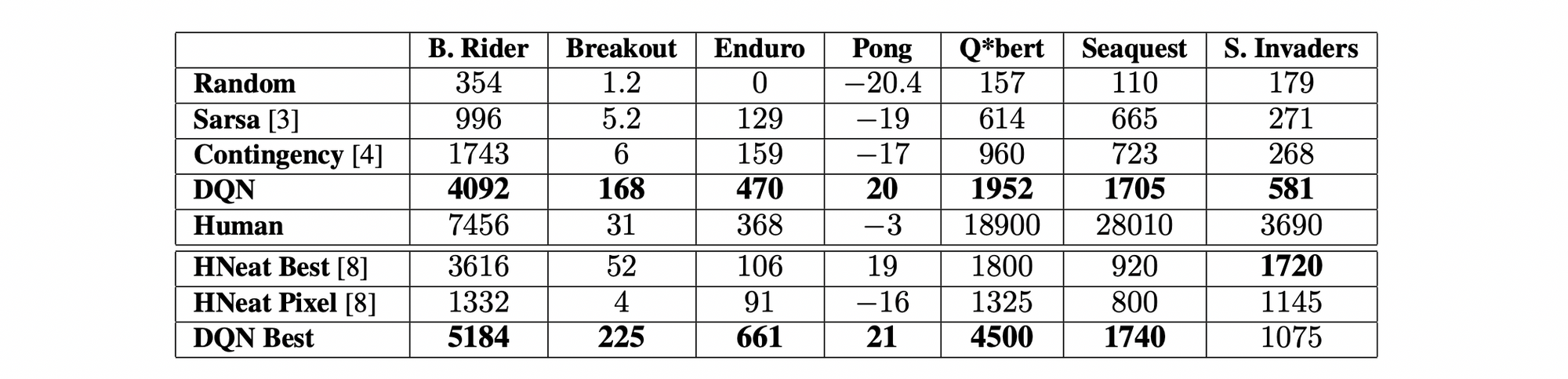
ซึ่งคะแนนที่ AI ของ DeepMind (DQN) ทำได้ในแต่ละเกม แสดงดังตารางด้านล่างนี้ครับ
ในบทความนี้ ผู้อ่านจะได้ฝึก AI Agent ให้เล่มเกม Pong หรือ Table Tennis ซึ่งเป็นหนึ่งใน Arcade Game ของ Gym Framework จาก OpenAI ที่ถูกก่อตั้งโดย Elon Musk (หนึ่งในผู้ก่อตั้ง)
โดยเราจะให้ AI Agent เรียนรู้การเล่นเกมด้วย Deep Q-Network (DQN) ที่เป็น Deep Learning Model เช่นเดียวกับที่ DeepMind ได้ใช้ฝึกสอน AI

แต่ก่อนที่ AI Agent จะมีความสามารถในการตัดสินใจในสถานการณ์ต่างๆ ได้ดี ช่วงแรกมันจะต้องมีการลองผิดลองถูกในจำนวนที่มากพอ (Exploration) โดยการสุ่มเลือก Action แล้วเรียนรู้จากผลลัพธ์ที่เกิดขึ้น (State และ Reward)
ผู้เขียน Train AI Agent ด้วย 4vCPU Intel(R) Xeon(R) @ 2.20GHz และ Tesla P100 บน Google Colab Pro ทั้งหมด 700 เกม เป็นเวลากว่า 16 ชั่วโมง จนกระทั่งหมดโควต้าการใช้งาน GPU โดยมีการเรียนรู้จาก Screen Pixel ทั้งสิ้นกว่า 1.5 ล้าน Frame
Q-Table Learning
ก่อนจะฝึกสอน AI Agent ด้วย DQN เราจะทำความเข้าใจแนวคิดสำคัญที่อยู่เบื้องหลังมันเสียก่อน นั่นคือ Q-Table Learning Algorithm
โดย Q-Table Learning นั้นเป็น Reinforcement Learning Algorithm สำหรับการประมาณค่า Action Values หรือ Q-values ซึ่งก็คือผลรวมของรางวัลที่ AI Agent น่าจะได้รับในอนาคต เมื่อมีการเปลี่ยนจาก State หนึ่งไปยังอีก State หนึ่ง
เพื่อให้มันบรรลุเป้าหมายตามภารกิจที่กำหนดไว้ AI Agent จะเลือก Action ซึ่งมีผลรวมของรางวัลที่น่าจะได้รับในอนาคต (Q-values) มากที่สุด
FrozenLake Environment
เราจะทดลองคำนวณ Q-values ด้วยการให้ AI Agent แก้ปัญหา FrozenLake (Environment หนึ่งของ Gym Framework)

โดย FrozenLake Environment จะประกอบด้วย Grid Block ขนาด 4x4 (16 State) 4 ประเภท ได้แก่ Start Block (S), Frozen Block (F), Hole Block (H) และ Goal Block (G)
เป้าหมายของ AI Agent คือการเดินทางจาก Start Block ไปยัง Goal Block ด้วยการ Move Up, Move Down, Move Left หรือ Move Right โดยห้ามผ่านไปบน Hole Block
ทุกๆ Step ของการเดิน AI Agent จะได้ Reward เท่ากับ 0 ยกเว้นเมื่อมันเดินทางไปถึง Goal Block ซึ่งจะได้ Reward เท่ากับ 1 นอกจากนี้ FrozenLake Environment จะจบ Episode และ Return สถานะ Done เท่ากับ True เมื่อ AI Agent เดินไปบน Hole Block หรือเดินถึง Goal Block
เพื่อให้เห็นภาพของการแก้ปัญหา FrozenLake Environment มากยิ่งขึ้น ผู้เขียนจะใช้ Google Colab Pro ในการรัน Code ตามขั้นตอนดังนี้
- ไปที่ Google Colab แล้วคลิ๊ก NEW NOTEBOOK
- คลิ๊กที่ Untitled0.ipynb ตั้งชื่อไฟล์เป็น q-values.ipynb แล้วเลือกเมนู Runtime -> Change runtime type
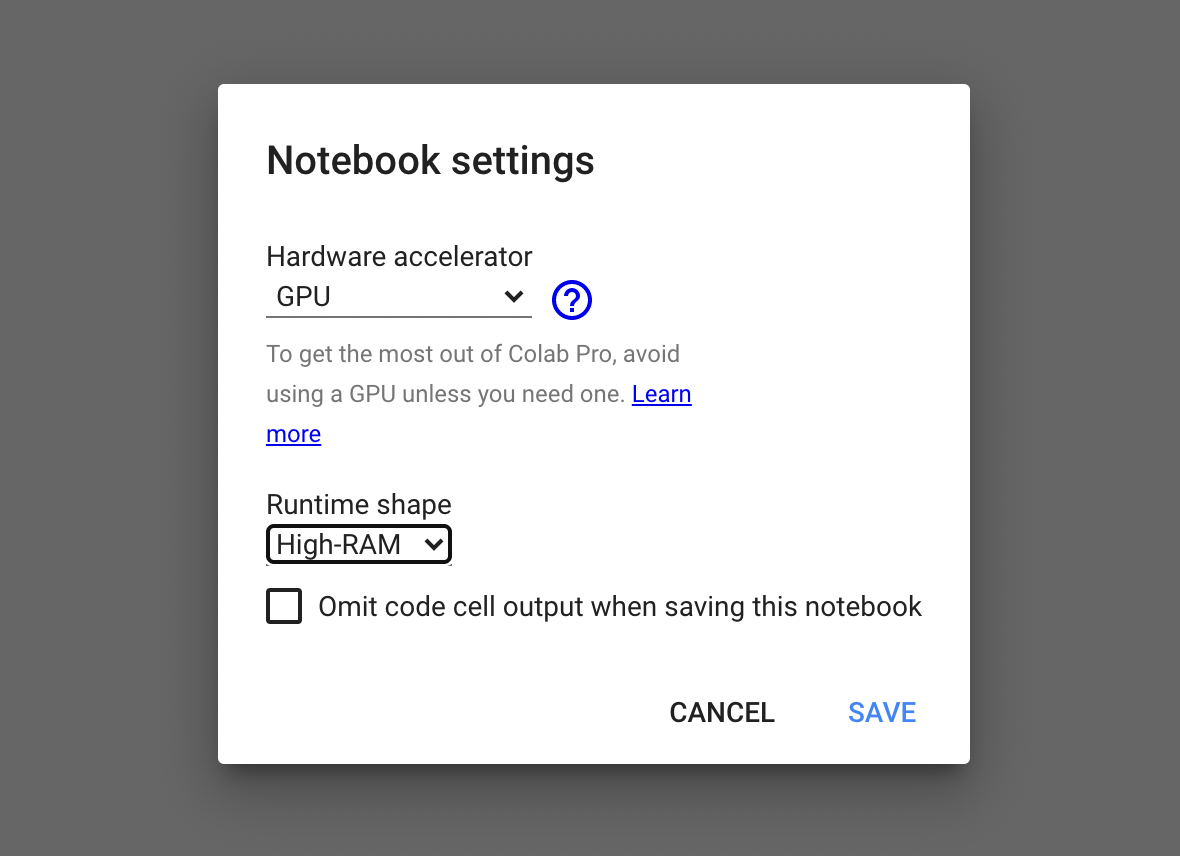
- เลือกชนิดของ Hardware accelerator เป็น GPU และ Runtime shape เป็น High-RAM แล้วคลิ๊ก SAVE
- ตรวจสอบการใช้งาน GPU ด้วยคำสั่งต่อไปนี้
!nvidia-smi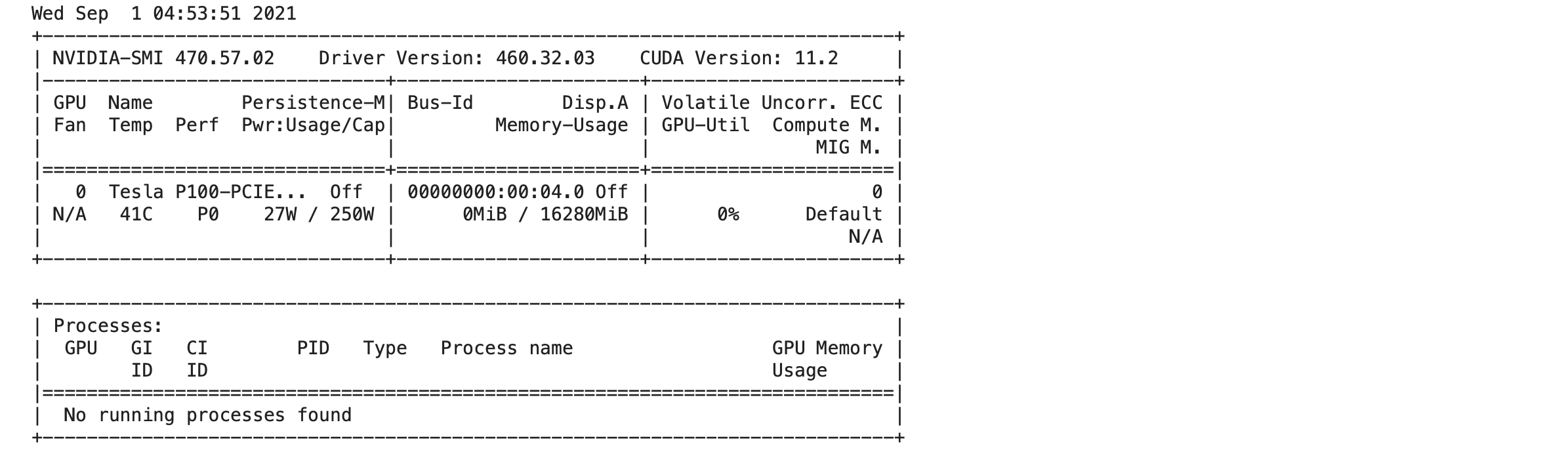
- แสดงจำนวน Core ของ CPU ที่ได้รับการจัดสรร
from psutil import *
cpu_count()4
- แสดงข้อมูลของ CPU ในแต่ละ Core
!cat /proc/cpuinfo
- Import Library ที่จำเป็นต้องใช้
import gym
import numpy as np
import random
import plotly.graph_objs as go
import pickle as p- กำหนด Environment เป็น FrozenLake
env = gym.make('FrozenLake-v0', is_slippery=False)- สุ่ม Action ด้วยคำสั่ง action = env.action_space.sample() นำ Action ที่สุ่มเข้า Environment เพื่อให้มันเปลี่ยนไปยัง State ถัดไป ด้วยคำสั่ง state, reward, done, info = env.step(action) และ Render State ที่เกิดขึ้น
state = env.reset()
print(' (Start)')
env.render()
while True:
action = env.action_space.sample()
state, reward, done, info = env.step(action)
print('\n')
env.render()
print(f'State = {state}, Reward = {reward}, Done = {done}')
if done:
break;
env.close()
Q-Table
เพื่อจะคำนวนหา Q-values เราจะสร้าง Q-Table ขนาด 16 แถว 4 คอลัมน์ ตามจำนวน State และ Action ดัง Code ด้านล่าง
Q = np.zeros([env.observation_space.n, env.action_space.n])
print(Q.shape)
print(Q)
เราจะปรับค่า Q-value ด้วยการฝึกสอน AI Agent ทั้งหมด 1000 Episode แต่ละ Episode จะมีการเดินได้หลาย Step จนกระทั่ง FrozenLake Environment คืนค่าสถานะ Done เท่ากับ True ด้วยสมการ ดังต่อไปนี้
Q(s,a) = Q(s,a) + lr(r + γ(max(Q(s',a)))
โดย
lr คือ Learning Rate
r คือ Reward
γ คือ Gamma
s' คือ Next Stateและจะมีการทำงานตามขั้นตอน ดัง Code ด้านล่าง
- กำหนด Parameter ต่างๆ
learning_rate = 0.8
gamma = 0.95
num_episode = 1000- ฝึกสอนทั้งหมด 1000 Episode โดยจะค่อยๆ ลดการลองผิดลองถูก (Exploration) ด้วยคำสั่ง action = np.argmax(Q[state,:] + np.random.randn(1, env.action_space.n)*(1./(i+1)))
reward_list = []
for i in range(num_episode):
state = env.reset()
sum_reward = 0
while True:
action = np.argmax(Q[state,:] + np.random.randn(1, env.action_space.n)*(1./(i+1)))
next_state, reward, done, info = env.step(action)
Q[state,action] = Q[state,action] + learning_rate*(reward + gamma*np.max(Q[next_state,:]))
sum_reward += reward
state = next_state
if done == True:
break
reward_list.append(sum_reward)- Plot กราฟ Reward
h1 = go.Scatter(y=reward_list,
mode="lines", line=dict(
width=2,
color='blue'),
name="reward"
)
data = [h1]
layout1 = go.Layout(title='Total Reward',
xaxis=dict(title='Episode'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
fig1.show(renderer="colab")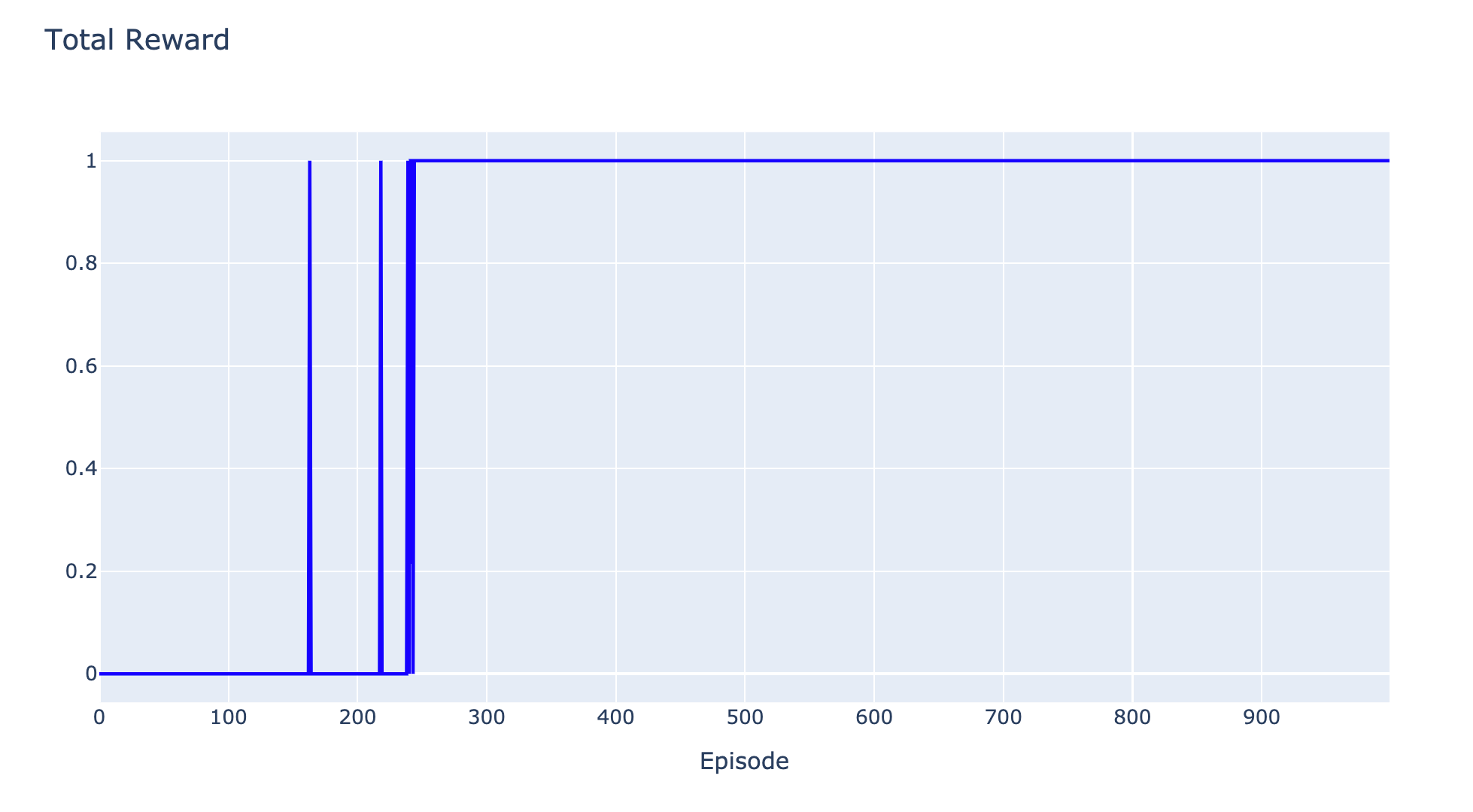
- แสดงค่าใน Q-Table
print("Final Q-Table")
print(Q)
- โดย AI Agent จะเลือก Action จาก Q-Table จนกระทั่งสามารถเดินทางถึง Goal Block ได้ ดังตัวอย่างต่อไปนี้
state = env.reset()
print(' (Start)')
env.render()
while True:
action = np.argmax(Q[state,:])
state, reward, done, info = env.step(action)
print('\n')
env.render()
print(f'State = {state}, Reward = {reward}, Done = {done}')
if done:
break;
env.close()

จากภาพด้านบนจะเห็นว่า AI Agent สามารถใช้ Q-Table ตัดสินใจเลือก Action ที่มีค่า Q-values หรือผลรวมของรางวัลที่น่าจะได้รับในอนาคตมากที่สุด
อย่างไรก็ตาม จำนวน State ของ Real-world Environment หรือแม้แต่เกมอย่าง Pong นั้นมีค่าใกล้อนันต์ การจะประมาณ Q-values ด้วย Q-Table ขนาดใหญ่ จึงเป็นไปได้ยากในทางปฏิบัติ ดังนั้นเราจะคำนวณค่า Q-values โดยใช้ Neural Network แทนการใช้ Q-Table ครับ
Deep Q-Network
Deep Learning Model
เราจะสร้าง Deep Learning Model แบบ Convolutional Neural Network จำนวน 2 ตัว (Double DQN) ที่มีการรับ Input เป็น Screen Pixel แบบ Grayscale ขนาดครึ่งหนึ่งของขนาดจาก Pong Environment จำนวน 4 Frame ที่อยู่ติดกัน (2 Frame สำหรับการประมาณความเร็ว, 3 Frame ขึ้นไปสำหรับประมาณความเร่ง) เพื่อประมาณค่า Q-value ซึ่ง Output Layer จะมีจำนวน Node เท่ากับขนาดของ Action Space ของ Pong Environment ดังตัวอย่าง ต่อไปนี้
- Import Library ที่จำเป็น
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib as mpl
import cv2
import os
import pickle as pic
from collections import deque
import sys
loss_function = tf.keras.losses.Huber()
initializer = tf.keras.initializers.VarianceScaling(scale=2.0)
tf.__version__'2.6.0'
- กำหนดค่า Learning Rate, Loss Function และค่าเริ่มต้นของ Weight
learning_rate=0.00025
loss_function = tf.keras.losses.Huber()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate, clipnorm=1.0)- นิยาม Deep Learning Model
def create_network(learning_rate, action_space):
initializer = tf.keras.initializers.VarianceScaling(scale=2.0)
model = tf.keras.models.Sequential()
model.add(tf.keras.Input(shape=(105,80,4)))
model.add(tf.keras.layers.Conv2D(32, 8, padding="same", strides=4, activation="relu", kernel_initializer=initializer, use_bias=False, name = "conv2d_1"))
model.add(tf.keras.layers.Conv2D(64, 4, padding="same", strides=2, activation="relu", kernel_initializer=initializer, use_bias=False, name = "conv2d_2"))
model.add(tf.keras.layers.Conv2D(64, 3, padding="same", strides=1, activation="relu", kernel_initializer=initializer, use_bias=False, name = "conv2d_3"))
model.add(tf.keras.layers.Flatten(name = "flatten_1"))
model.add(tf.keras.layers.Dense(512,activation="relu", kernel_initializer=initializer, name = "dense_1"))
model.add(tf.keras.layers.Dense(action_space, kernel_initializer=initializer, name = "dense_2"))
return model- ติดตั้ง Atari Environment สำหรับเกม Pong (ROM)
pip install -U gym[atari,accept-rom-license]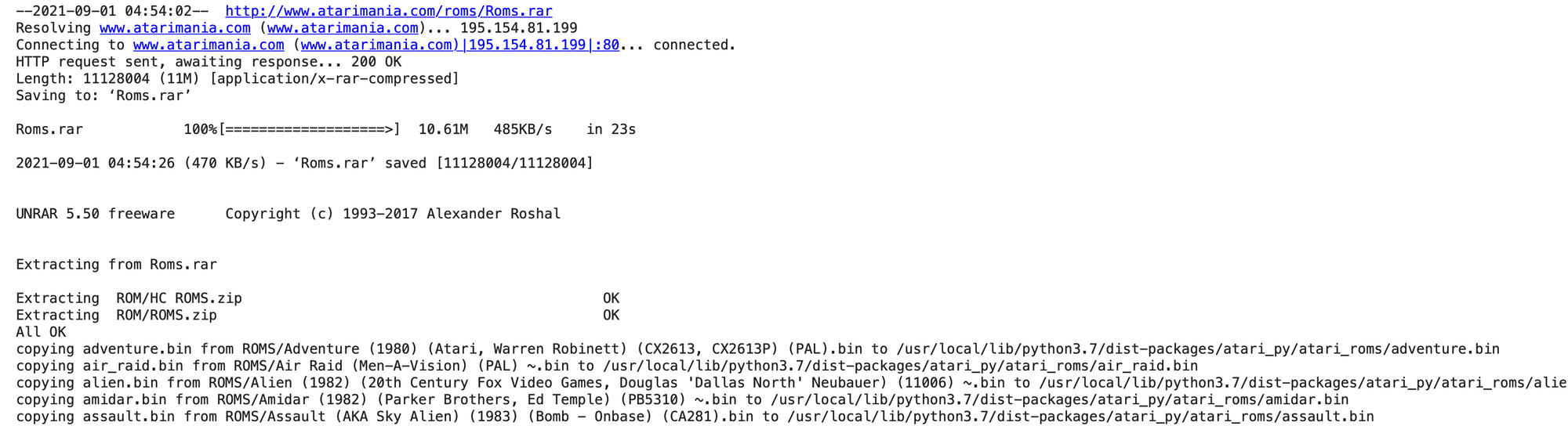
- Compile Model แสดง Output Shape และจำนวน Parameter
env = gym.make('Pong-v0')
model = create_network(learning_rate, env.action_space.n)
model.compile(loss=loss_function, optimizer=optimizer)
target_model = create_network(learning_rate, env.action_space.n)
target_model.compile(loss=loss_function, optimizer=optimizer)model.summary()
target_model.summary()
จะเห็นว่า Model ของเรามีจำนวน Parameter ประมาณ 4.7 ล้านตัว ซึ่งถือว่าเป็น Model ที่มีขนาดไม่ใหญ่มากนัก
Screen Pixel Preprocessing
แต่ด้วย Screen Pixel เดิม จาก Pong Environment นั้นเป็นภาพสี ขนาด 210X160 โดยแต่ละ Pixel จะมีค่าอยู่ระหว่าง 0 - 236 ดังตัวอย่าง ต่อไปนี้
env = gym.make('Pong-v4')
env.reset()
action = env.action_space.sample()
state, reward, done, _, info = env.step(action)
print(state.shape)
print(state.min(), state.max())(210, 160, 3)
0 236
print(state)
mpl.rcParams['figure.dpi'] = 300
plt.imshow(state)
plt.savefig('pong.png')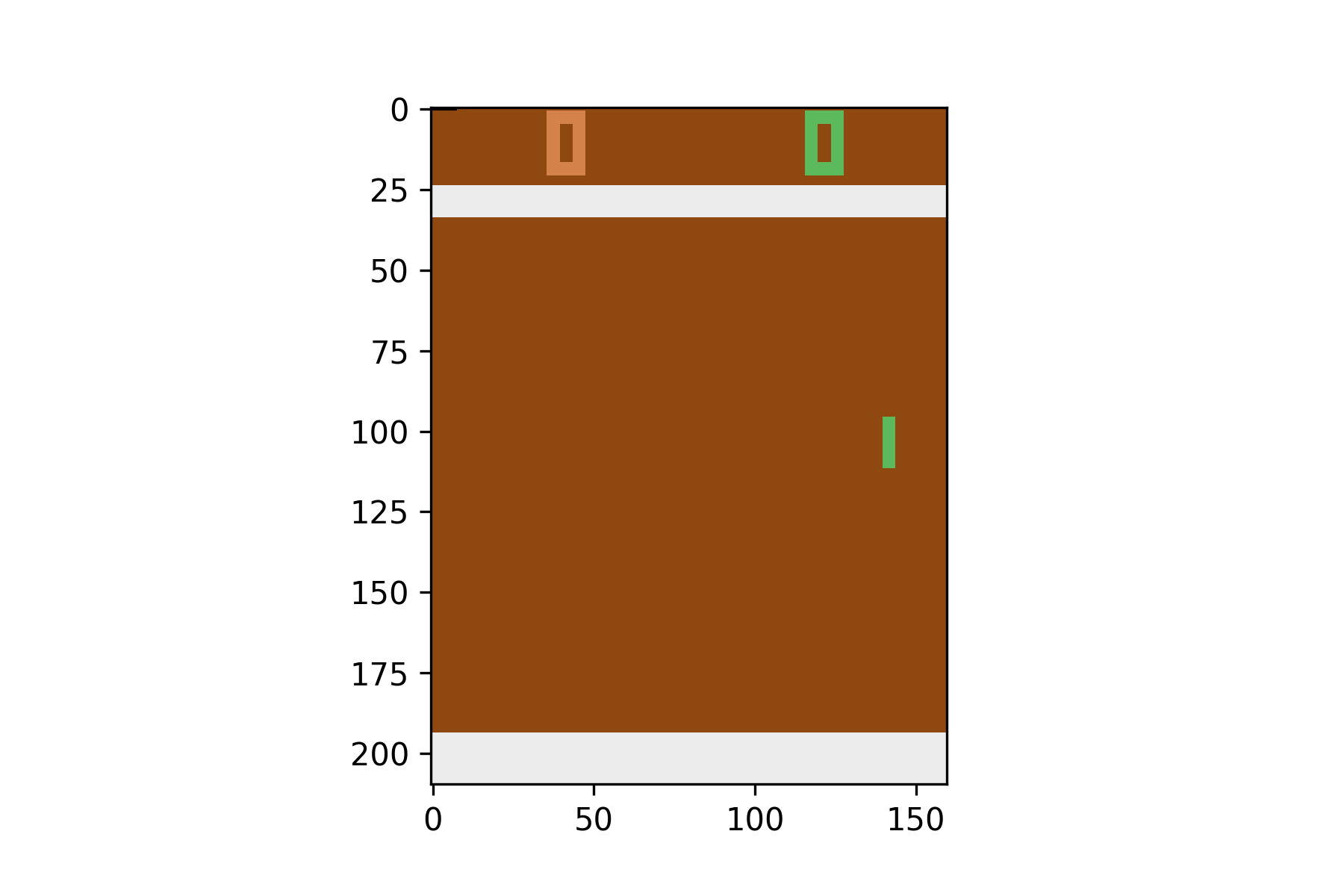
ดังนั้นจึงต้องมีการทำ Preprocessing เพื่อแปลงภาพเป็นแบบ Grayscale ขนาด 105X80 และ Nomalization ให้ค่าสีอยู่ระหว่าง 0.00 - 1.00 เสียก่อน
def screen_pixel_preprocess(observation):
s = cv2.cvtColor(observation, cv2.COLOR_BGR2GRAY)
s = cv2.resize(s, (0, 0), fx=0.5, fy=0.5, interpolation = cv2.INTER_AREA)
s = s/236.0
return sstate = screen_pixel_preprocess(state)
state.shape(105, 80)
print(state)
plt.imshow(state, cmap='gray')
plt.savefig('pong2.png')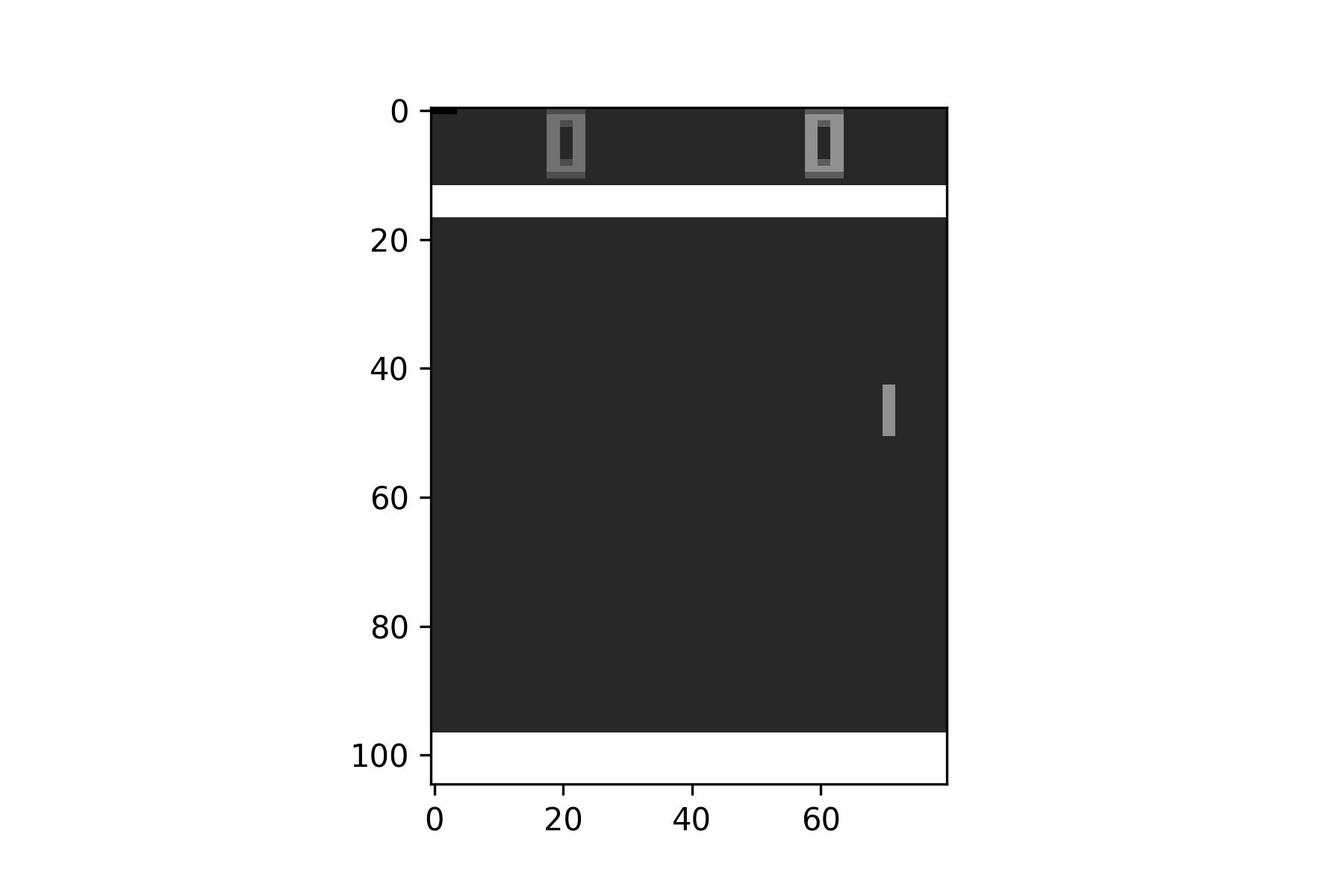
Save Model to Google Drive
เราจะฝึกสอน AI Agent ทั้งหมด 2,000 Episode ซึ่งแต่ละ Episode หรือแต่ละเกม ผู้เล่นทั้ง 2 ฝั่ง จะต้องพยายามทำคะแนนให้ได้ 21 คะแนนก่อน โดยทุกๆ 100 Episode จะมีการ Save Model ลง Google Drive 1 ไฟล์ (model-xxx.h5) ตามขั้นตอนดังนี้
- Mount Colab กับ Google Drive
from google.colab import drive
drive.mount('/content/drive')- คลิ๊ก Link เพื่อขอ Authorization Code สำหรับเข้าถึง Google Drive

- เลือก Google Account แล้วคลิ๊ก อนุญาต
- Copy Authorization Code เพื่อไปวางใน Text Box แล้วกด Enter

- ไปที่ Google Drive ด้วย Google Account ที่เลือกด้านบน แล้วสร้าง Folder ชื่อ colabpro_drive
- ติดตั้ง Google Drive App (Option)
- เปลี่ยน Directory (Folder) ปัจจุบันเป็น colabpro_drive
os.chdir("drive/My Drive/colabpro_drive")- ตรวจสอบ Directory ปัจจุบัน
pwd'/content/drive/My Drive/colabpro_drive'
Render OpenAI Gym on Google Colab
เพื่อจะดูการเล่นเกม Pong ของ AI Agent กับ Bot เราจะใช้วิธีสร้าง Video ดังต่อไปนี้
- ติดตั้ง Package xvfb
!apt update
!apt install xvfb
- ติดตั้ง Library pyvirtualdisplay เพียงครั้งเดียว โดยการเก็บไฟล์ใน Google Drive (colabpro_drive/lib)
nb_path = "/content/drive/My Drive/colabpro_drive/lib"
sys.path.append(nb_path)
!pip install pyvirtualdisplay --target="{nb_path}" --upgrade 
หลังจากติดตั้ง Library ในครั้งแรกแล้วให้เปิด Comment ดังตัวอย่าง Code ด้านล่าง โดยไม่ต้องรันใหม่อีกต่อไป
# !pip install pyvirtualdisplay --target="{nb_path}" --upgrade - Import Library สำหรับการบันทึก Video
import pyvirtualdisplay
import gym
from gym.wrappers.monitoring.video_recorder import VideoRecorder
import glob
import io
import base64
from IPython import display as ipythondisplay
from IPython.display import HTML- Start Virtual Display สำหรับการบันทึก Video
d = pyvirtualdisplay.Display()
d.start()
- นิยาม Function สำหรับ Replay Video
def show_video():
mp4list = glob.glob('video/*.mp4')
if len(mp4list) > 0:
mp4 = mp4list[0]
video = io.open(mp4, 'r+b').read()
encoded = base64.b64encode(video)
ipythondisplay.display(HTML(data='''<video alt="test" autoplay loop controls style="height: 400px;">
<source src="data:video/mp4;base64,{0}" type="video/mp4" />
</video>'''.format(encoded.decode('ascii'))))
else:
print("Could not find video")- เล่นเกม Pong กับ Bot โดยการสุ่ม Action ซึ่งเมื่อจบเกมเราจะได้ไฟล์ MP4 เอาไว้ Replay ทีหลัง
env = gym.make('Pong-v4', render_mode='human')
video_recorder = VideoRecorder(env, 'video/test.mp4')
state = env.reset()while True:
env.render()
video_recorder.capture_frame()
action = env.action_space.sample()
state, reward, done, _, info = env.step(action)
if done:
break;
video_recorder.close()
video_recorder.enabled = False
env.close()
show_video()

Exploration Strategy
อย่างไรก็ตาม ในช่วงแรกของการฝึกสอน เราจะต้องสุ่ม Action ในอัตราที่มากพอโดยให้มันเลือกว่าจะค้นหาแนวทางใหม่ (Explore) เพื่อไม่ก่อให้เกิดปัญหา Local Minima หรือจะทำในแบบที่คิดว่าดีอยู่แล้ว (Exploit)
โดยการกำหนด epsilon ซึ่งเป็นค่าที่จะบอกให้มีการสุ่ม Action มากหรือน้อย ที่ถ้า epsilon เท่ากับ 1.0 จะมีโอกาสสุ่ม Action 100%
ในการฝึกสอนเราจะลดค่า epsilon จาก 1.0 จนถึง 0.1 เมื่อผ่านไปแล้ว 1 ล้าน Frame นอกจากนี้เราจะบังคับให้มีโอกาสในการสุ่ม 100% ตั้งแต่เริ่มต้นฝึกสอน จนถึง Frame Count เท่ากับ 50,000
epsilon = 1.0
epsilon_min = 0.1
epsilon_max = 1.0
epsilon_interval = (
epsilon_max - epsilon_min
)
epsilon_greedy_frames = 1000000.0
epsilon_random_frames = 50000
eps_memory = []for frame_count in range(2000000):
if frame_count < epsilon_random_frames:
eps_memory.append(1)
else:
eps_memory.append(epsilon)
epsilon -= epsilon_interval/epsilon_greedy_frames
epsilon = max(epsilon, epsilon_min)h1 = go.Scatter(y=eps_memory,
mode="lines", line=dict(
width=2,
color='blue'),
name="epsilon"
)
data = [h1]
layout1 = go.Layout(title='Epsilon Schedule',
xaxis=dict(title='Frame Count'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
fig1.show(renderer="colab")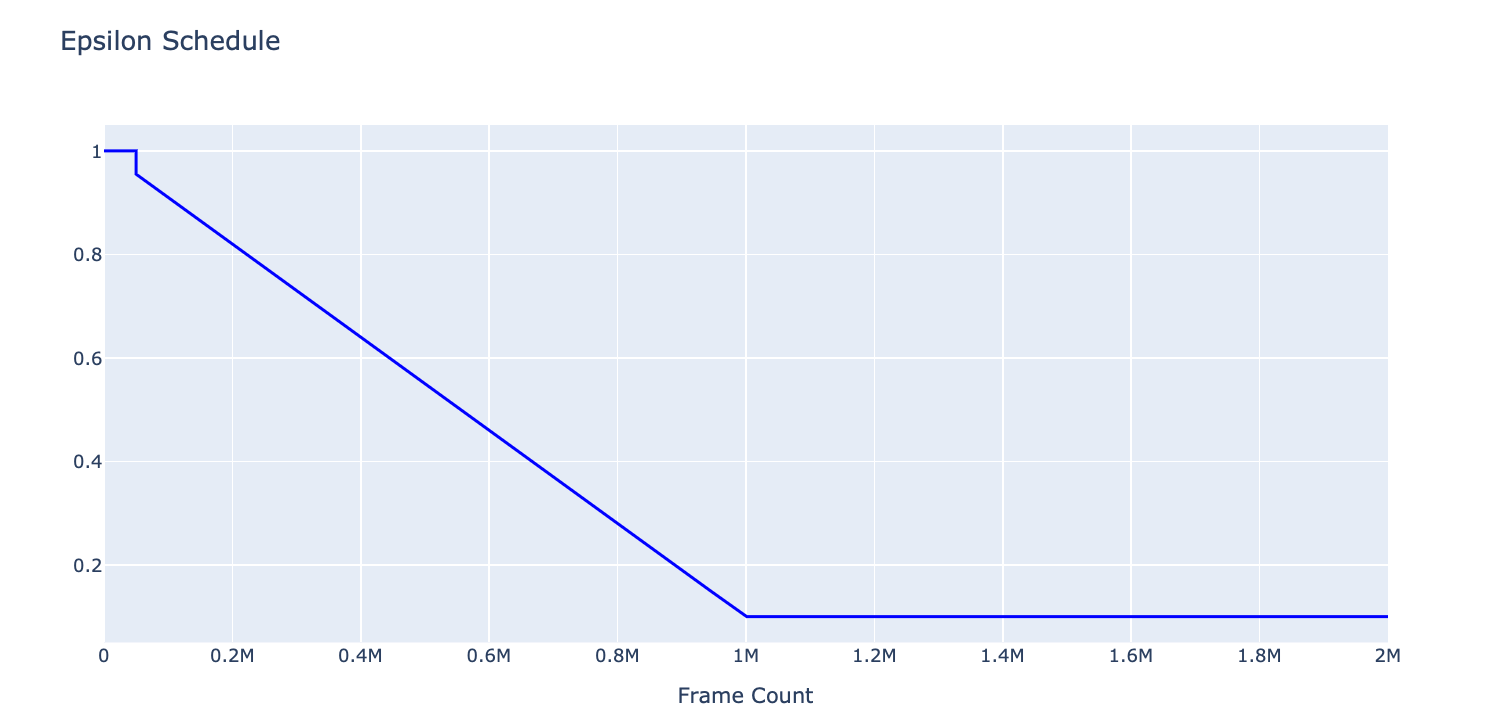
Collect Dataset
ขณะที่มีการฝึกสอน จะมีการบันทึก Screen Pixel, Reward และ Action ลง Buffer เพื่อจะได้สุ่มเลือกมา Train Model ตามขนาด Batch Size ในภายหลัง แต่ด้วยข้อจำกัดของ Memory ที่ได้รับการจัดสรรตามโควต้าของ Colab Pro ทำให้ผู้เขียนสามารถกำหนดขนาด Buffer ได้สูงสุดเพียง 40,000 เพื่อไม่ให้เกิด Session Crash เมื่อ Memory เต็ม
โดยเราจะรวบรวม 4 Screen Pixel ที่อยู่ติดกันลงในตัวแปร pre_state และ state เมื่อผ่านไป x Step ดังตัวอย่างต่อไปนี้
frame_id = 0
state = []
pre_state = []
def sample():
return np.random.choice(6)
def step(action):
global frame_id
frame_id+=1
return frame_id
def update_state(state, observation):
state.append(observation)
if len(state) > 4:
del state[:1]
def predict(state):
return 1update_state(state, None)
for num_step in range(5):
if len(state) < 4:
action = sample()
else:
action = predict(state)
pre_state.append(state[-1])
if len(pre_state) > 4:
del pre_state[:1]
observation = step(action)
update_state(state,observation)pre_state, state([1, 2, 3, 4], [2, 3, 4, 5])
*Frame ID ที่เก็บอยู่ใน pre_state และ state
จาก Frame ID ใน pre_state และ state ในการฝึกสอนจริง เราจะนำ Screen Pixel ตามลำดับดังตัวอย่าง ที่มี Shape เป็น 105x80x4 ไปบันทึกลงใน Buffer (state_memory และ state_next_memory)
Double DQN
ในอีก 2 ปีหลังจากการตีพิมพ์ Paper ชื่อ Playing Atari with Deep Reinforcement Learning DeepMind ก็ได้ตีพิมพ์ Paper ที่แสดงให้เห็นว่าการฝึกสอน AI Agent ที่ใช้ DQN 2 ตัว (Double DQN) สามารถเพิ่มประสิทธิภาพในการเล่นเกมได้อีก ดังนั้นในการทดลอง ผู้เขียนจึงใช้เทคนิคดังกล่าวในการฝึกสอนด้วย

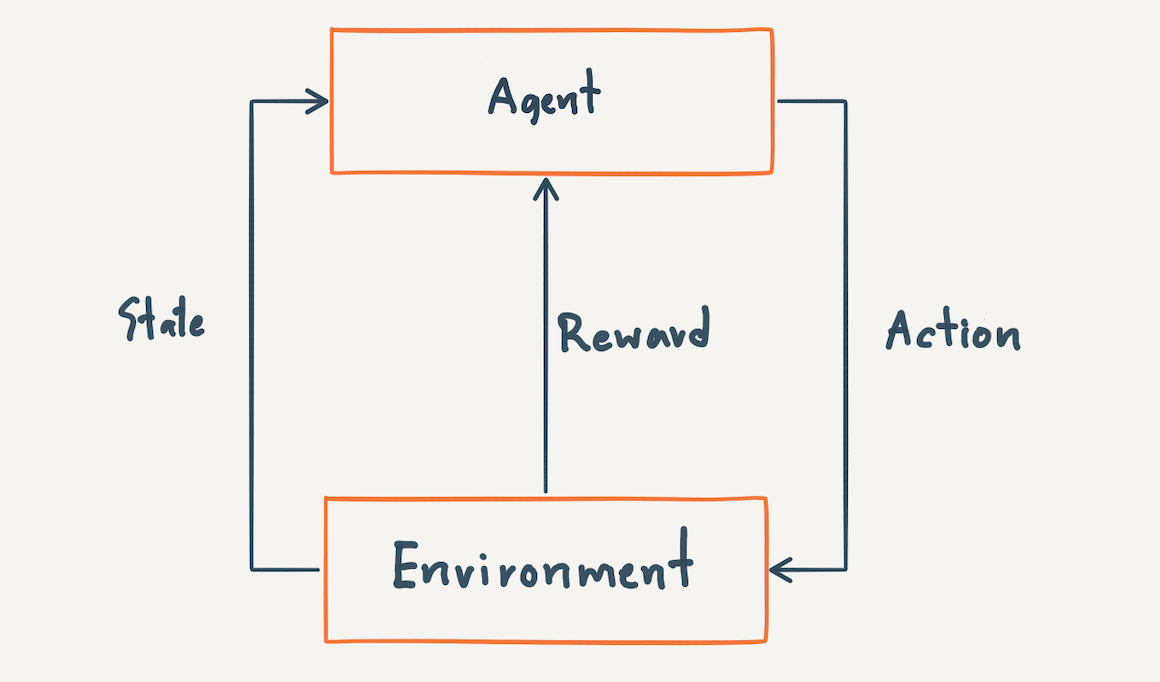
ภาพต่อไปนี้แสดง AI Agent Architecture สำหรับการฝึกสอน Model แบบ Double DQN (1. model และ 2. taget_model) โดย model จะเป็น DQN ตัวหลักที่มีปฏิสัมพันธ์กับ Gym Environment ด้วย Exploration Strategy ดังที่ได้อธิบายไปแล้วข้างต้น ซึ่งขณะที่เล่นเกม เราจะบันทึกข้อมูล reward, action, state และ state_next ลง Buffer (reward_memory, action_memory, state_memory และ state_next_memory ) เพื่อใช้ในการ Train Model ต่อไป
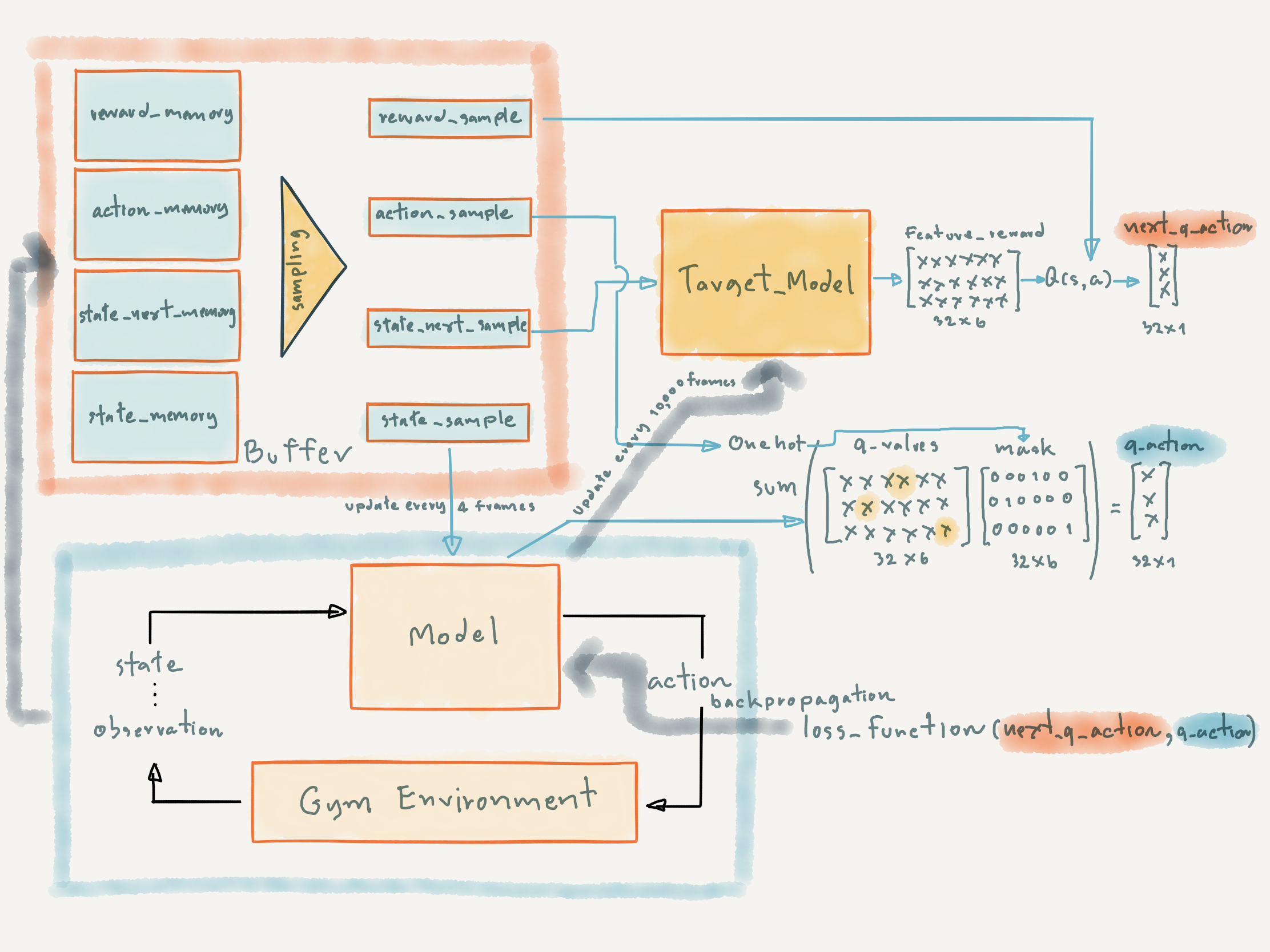
ในการ Train Model เราจะมีการ Update Weight ที่ DQN ตัวหลัก (model) ทุกๆ 4 Frame โดยใช้ผลเฉลย (next_q_action) ที่ได้จากการ Predict ด้วย target_model ขณะที่ target_model จะถูก Update Weight ทุกๆ 10,000 Frame
ซึ่งการชลอการ Update ของ target_model จะทำให้สามารถเพิ่มประสิทธิภาพในการเล่นเกมของ AI Agent ได้ (https://arxiv.org/pdf/1509.06461.pdf)
การ Train Model จะมีขั้นตอนดังนี้
- นิยาม update_state Function สำหรับรวบรวม 4 Screen Pixel
def update_state(state, observation):
observation = screen_pixel_preprocess(observation)
state.append(observation)
if len(state) > 4:
del state[:1]- นิยาม save_history Function สำหรับบันทึก Reward ในแต่ละเกม
def save_history(filename, history):
with open(filename, 'wb') as file:
pic.dump(history, file)- นิยามตัวแปร และกำหนด Parameter ที่ต้องใช้
action_memory = []
state_memory = []
state_next_memory = []
rewards_memory = []
done_memory = []
history= []
num_episode = 2000
frame_count = 0
epsilon_random_frames = 50000
epsilon_greedy_frames = 1000000.0
max_memory_length = 40000
update_after_actions = 4
update_target_network = 10000
num_action = env.action_space.n
batch_size = 32
gamma = 0.99 # Discount factor for past rewards
epsilon = 1.0
epsilon_min = 0.1
epsilon_max = 1.0
epsilon_interval = (
epsilon_max - epsilon_min
)- Train Model
for i in range(num_episode):
observation = env.reset()
done = False
state = []
pre_state = []
update_state(state,observation)
episode_reward = 0
while not done:
frame_count += 1
if frame_count < epsilon_random_frames or epsilon > random.random() or len(state) < 4:
action = np.random.choice(num_action)
else:
s = np.stack((state[0],state[1],state[2],state[3]),axis=2)
s = np.array([s])
action_probs = model.predict(s)
action = tf.argmax(action_probs[0]).numpy()
epsilon -= epsilon_interval/epsilon_greedy_frames
epsilon = max(epsilon, epsilon_min)
pre_state.append(state[-1])
if len(pre_state) > 4:
del pre_state[:1]
observation, reward, done, _ = env.step(action)
update_state(state, observation)
episode_reward += reward
if len(state) == 4 and len(pre_state) == 4:
action_memory.append(action)
pre_state_for_model = np.stack((pre_state[0],pre_state[1],pre_state[2],pre_state[3]),axis=2)
state_memory.append(pre_state_for_model)
state_for_model = np.stack((state[0],state[1],state[2],state[3]),axis=2)
state_next_memory.append(state_for_model)
rewards_memory.append(reward)
if frame_count % update_after_actions == 0 and len(rewards_memory) > batch_size:
random_index = np.random.choice(range(len(rewards_memory)), size=batch_size)
action_sample = [action_memory[i] for i in random_index]
state_sample = np.array([state_memory[i] for i in random_index])
state_next_sample = np.array([state_next_memory[i] for i in random_index])
rewards_sample = [rewards_memory[i] for i in random_index]
future_rewards = target_model.predict(state_next_sample)
next_q_values = rewards_sample + gamma * tf.reduce_max(
future_rewards, axis=1
)
masks = tf.one_hot(action_sample, num_action)
with tf.GradientTape() as tape:
q_values = model(state_sample)
q_action = tf.reduce_sum(tf.multiply(q_values, masks), axis=1)
loss = loss_function(next_q_values, q_action)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if frame_count % update_target_network == 0:
target_model.set_weights(model.get_weights())
if len(rewards_memory) > max_memory_length:
del action_memory[:1]
del state_memory[:1]
del state_next_memory[:1]
del rewards_memory[:1]
history.append(episode_reward)
print(str(i)+ " episode total reward:",episode_reward)
print("Frame Count = " + str(frame_count))
if i%100 == 0:
print("Saving the model")
model.save("model/model-{}.h5".format(i))
print("Saving the history")
save_history("reward_history", history)- คลิ๊กที่ Terminal แล้วตรวจสอบการใช้ Momery ด้วยคำสั่ง top
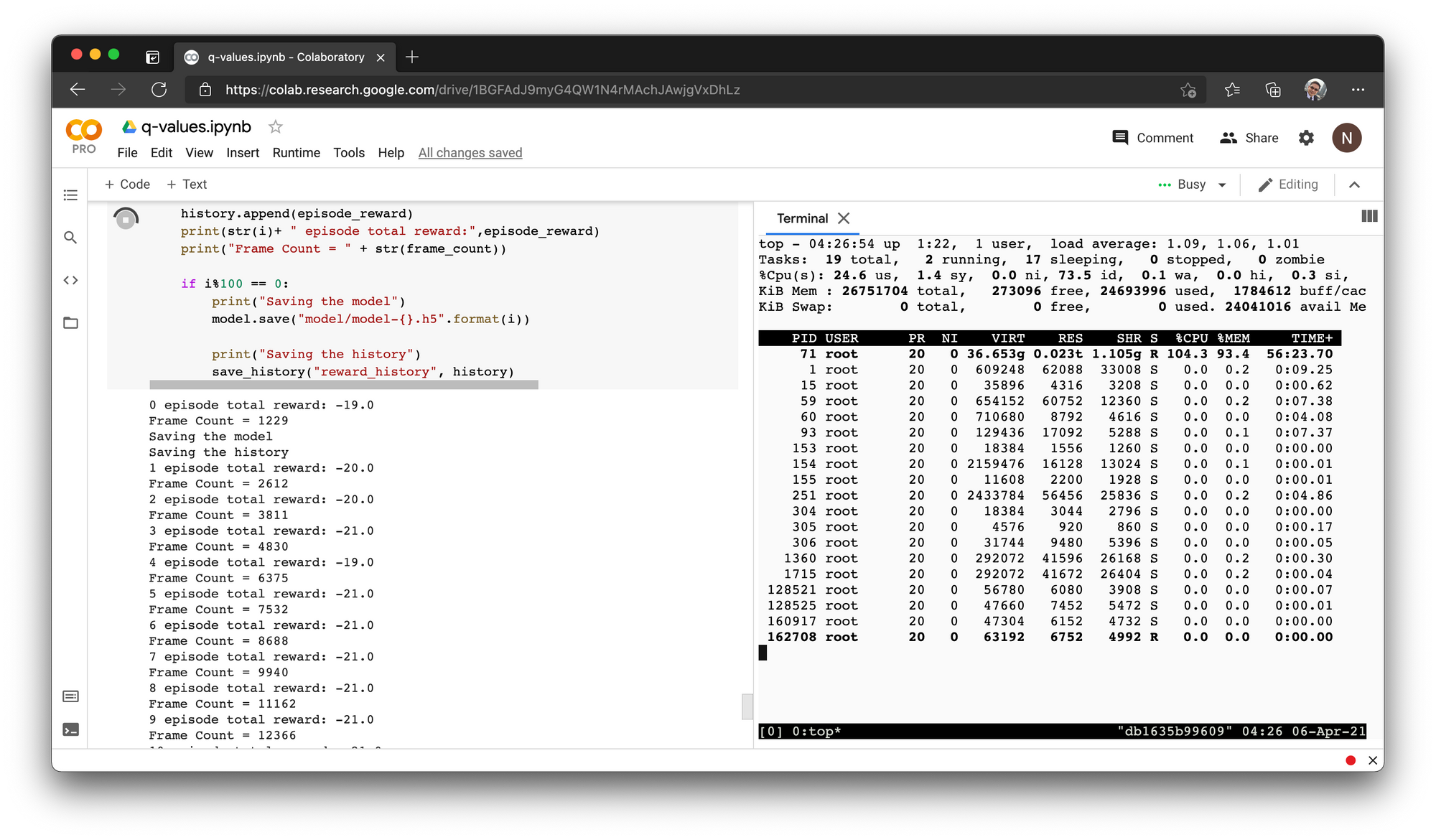
ซึ่งจะพบว่ามีการใช้ Memory ทั้งหมด 93.4%
- กด q เพื่อออกจาก top (ถ้าต้องการ)
- ไปที่ JavaScript Console ของ Browser ที่ผู้อ่านใช้งาน เช่น Tools -> Developer -> JavaScript Console (ของ MS Edge) เพื่อรัน Script รักษา Session ไม่ให้ Timeout

- Copy Code การรักษา Session ไปวางที่ JavaScript Console แล้วกด Enter เพื่อรัน Script
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,80000);
ผู้เขียน Train AI Agent บน Google Colab Pro ทั้งหมด 700 เกม (Episode) เป็นเวลากว่า 16 ชั่วโมง จนกระทั่งหมดโควต้าการใช้งาน GPU ซึ่งมีการเรียนรู้จาก Screen Pixel ไปทั้งสิ้นกว่า 1.5 ล้าน Frame โดยมีการบันทึก Model ทุกๆ 100 Episode
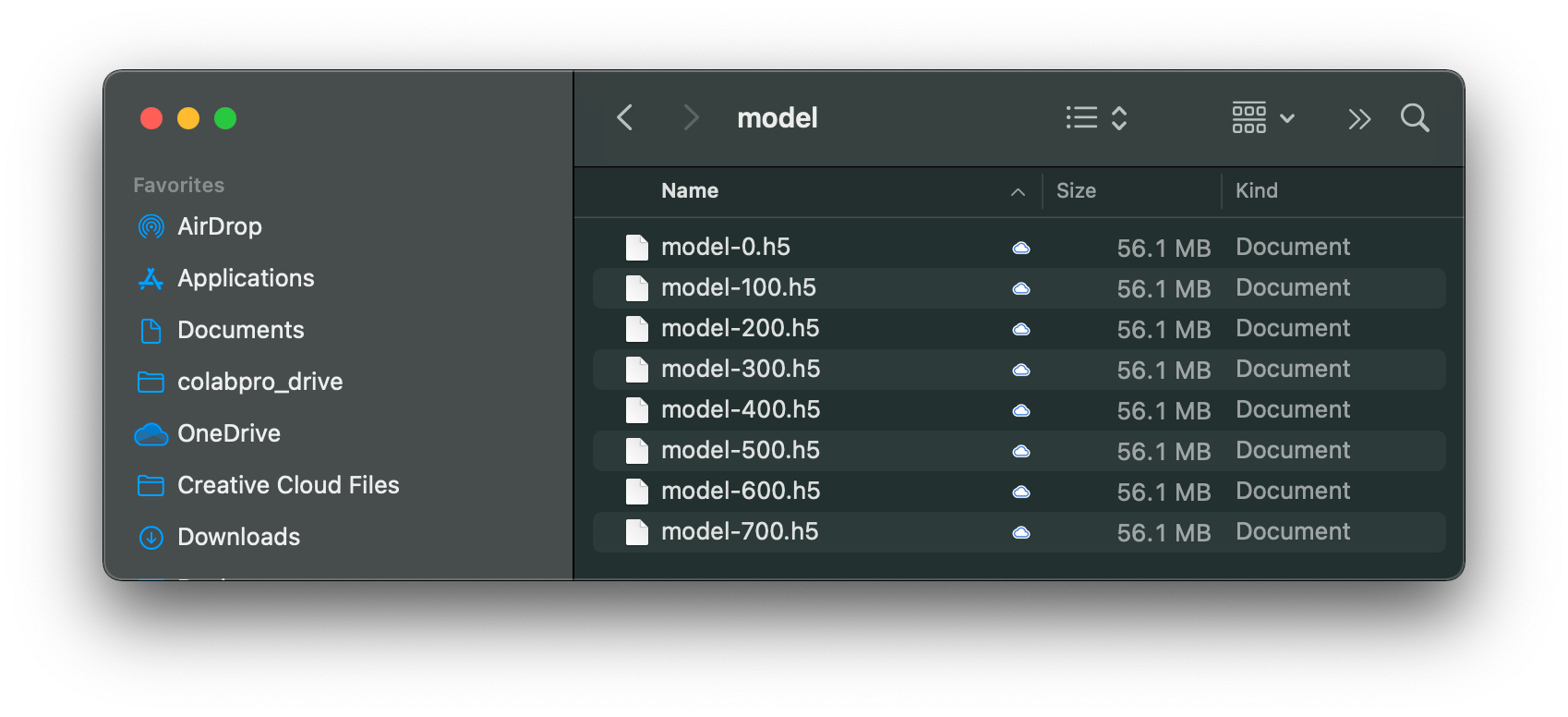
Play the Game
เราจะเล่นเกมจาก Notebook ไฟล์ใหม่ ดังนี้
- คลิ๊กที่ File -> New notebook
- คลิ๊กที่ Untitled0.ipynb ตั้งชื่อไฟล์เป็น play.ipynb แล้วเลือกเมนู Runtime -> Change runtime type
- เลือกชนิดของ Hardware accelerator เป็น GPU และ Runtime shape เป็น High-RAM แล้วคลิ๊ก SAVE
- ตรวจสอบการใช้งาน GPU ด้วยคำสั่งต่อไปนี้
!nvidia-smi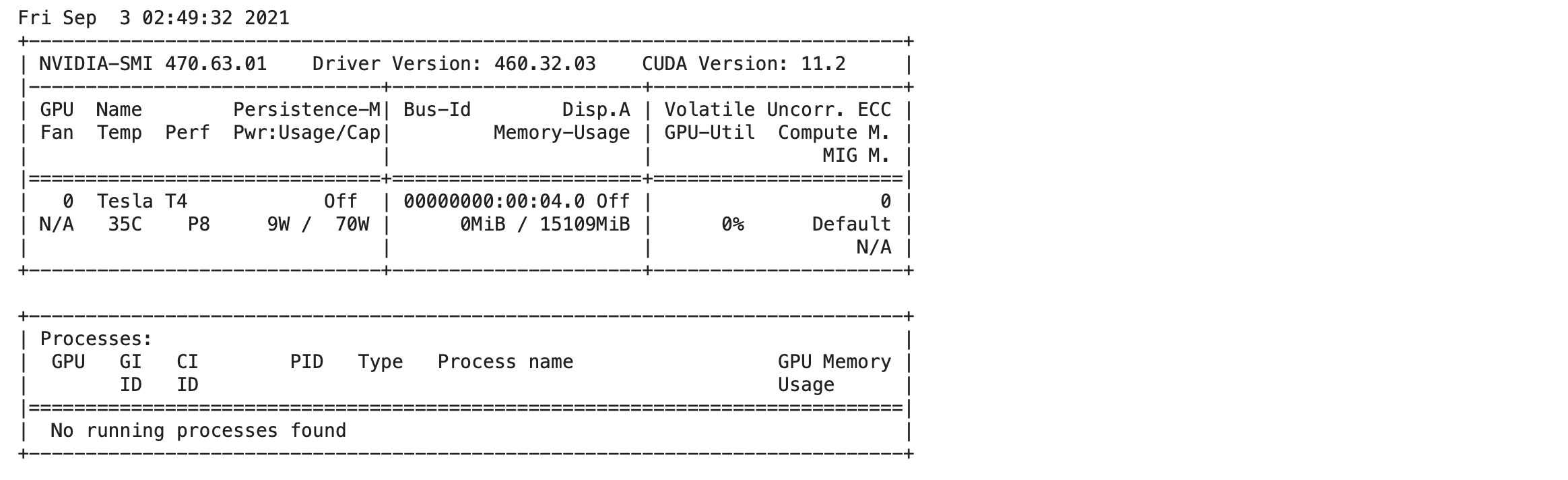
- แสดงจำนวน Core ของ CPU ที่ได้รับการจัดสรร
from psutil import *
cpu_count()4
- แสดงข้อมูลของ CPU ในแต่ละ Core
!cat /proc/cpuinfo
- Mount Colab กับ Google Drive
from google.colab import drive
drive.mount('/content/drive')- เปลี่ยน Directory (Folder) ปัจจุบันเป็น colabpro_drive
os.chdir("drive/My Drive/colabpro_drive")- ตรวจสอบ Directory ปัจจุบัน
pwd'/content/drive/My Drive/colabpro_drive'
- ติดตั้ง Package xvfb
!apt update
!apt install xvfb- Import Library สำหรับการบันทึก Video
import sys
nb_path = "/content/drive/My Drive/colabpro_drive/lib"
sys.path.append(nb_path)
# !pip install pyvirtualdisplay --target="{nb_path}" --upgrade
import pyvirtualdisplay
from gym.wrappers import Monitor
import glob
import io
import base64
from IPython import display as ipythondisplay
from IPython.display import HTML- Start Virtual Display สำหรับการบันทึก Video
d = pyvirtualdisplay.Display()
d.start()- นิยาม Function สำหรับ Replay Video
def show_video():
mp4list = glob.glob('video/*.mp4')
if len(mp4list) > 0:
mp4 = mp4list[0]
video = io.open(mp4, 'r+b').read()
encoded = base64.b64encode(video)
ipythondisplay.display(HTML(data='''<video alt="test" autoplay loop controls style="height: 400px;">
<source src="data:video/mp4;base64,{0}" type="video/mp4" />
</video>'''.format(encoded.decode('ascii'))))
else:
print("Could not find video")
def wrap_env(env):
env = Monitor(env, './video', force=True)
return env- Import Library อื่นๆ ที่จำเป็น
import gym
import cv2
import numpy as np
import plotly.graph_objs as go
import pickle as p
from sklearn.manifold import TSNE
import pandas as pd
import plotly.express as px
import tensorflow as tf
load_model = tf.keras.models.load_model- Load Reward History
with open('reward_history', 'rb') as file:
history = p.load(file)- Plot กราฟ Reward
h1 = go.Scatter(y=history,
mode="lines", line=dict(
width=2,
color='blue'),
name="reward"
)
data = [h1]
layout1 = go.Layout(title='Total Reward',
xaxis=dict(title='Episode'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
fig1.show(renderer="colab")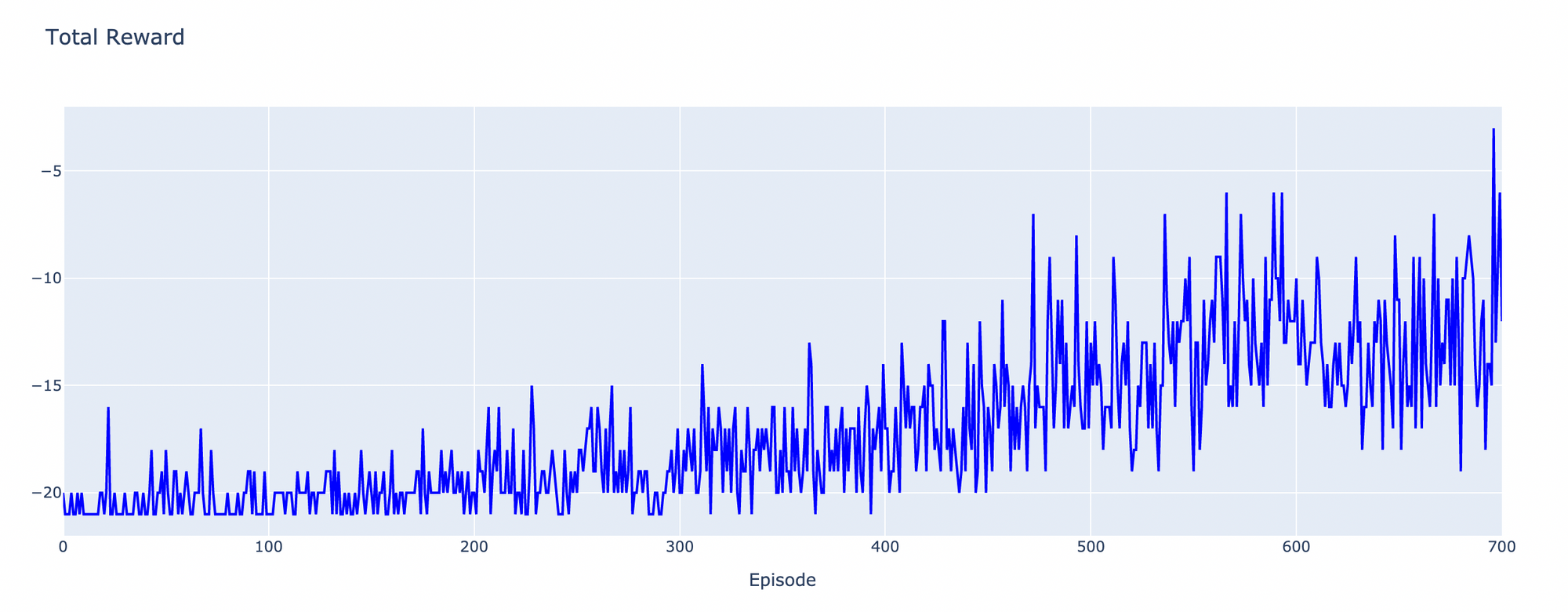
- นิยาม screen_pixel_preprocess, update_state และ predict_action Function
def screen_pixel_preprocess(observation):
s = cv2.cvtColor(observation, cv2.COLOR_BGR2GRAY)
s = cv2.resize(s, (0, 0), fx=0.5, fy=0.5, interpolation = cv2.INTER_AREA)
# cv2.imwrite('image.png',s)
s = s/236.0
return s
def update_state(state,observation):
ds_observation = screen_pixel_preprocess(observation)
state.append(ds_observation)
if len(state) > 4:
del state[:1]
def predict_action(model, s):
return np.argmax(model.predict(np.array([np.stack((s[0],s[1],s[2],s[3]),axis=2)]))[0])- Load Model
model = load_model('model/model-700.h5')
model.summary()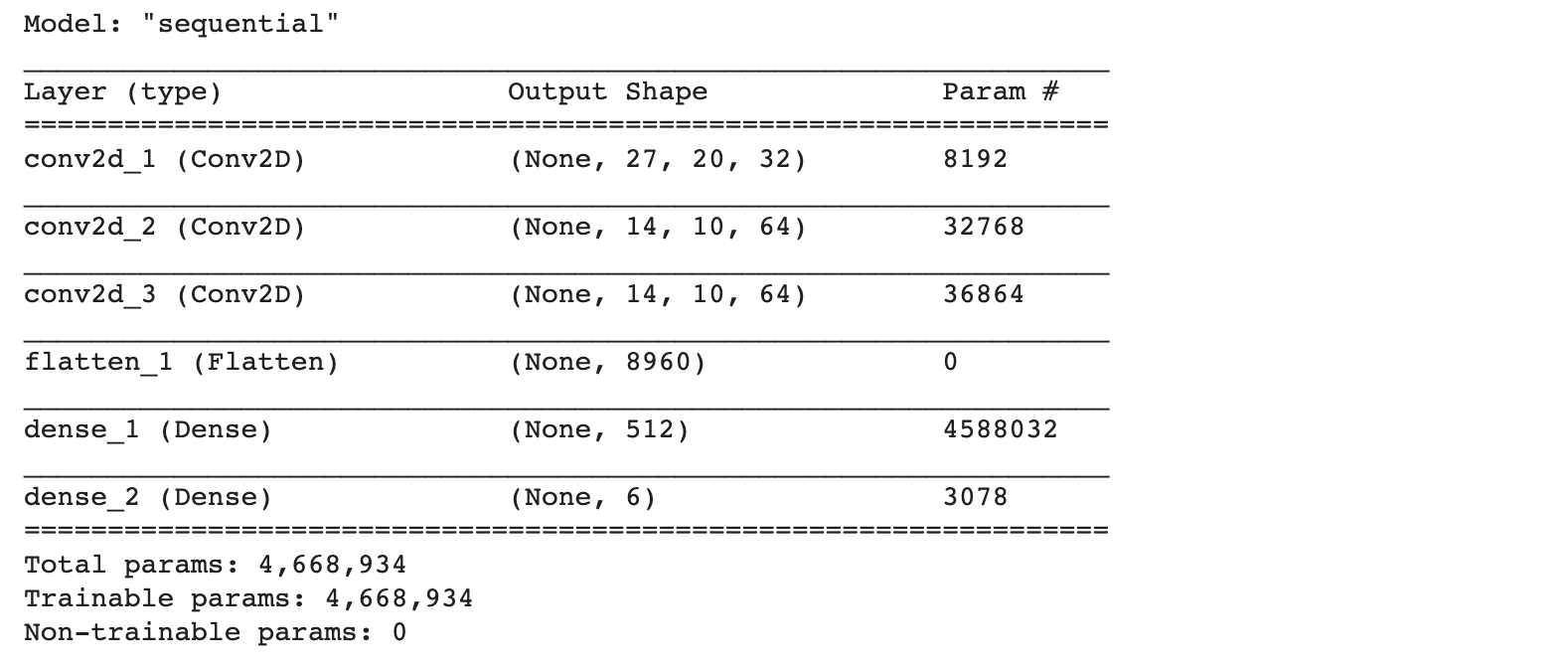
- ติดตั้ง Atari Environment สำหรับเกม Pong (ROM)
!wget http://www.atarimania.com/roms/Roms.rar
!mkdir ROM
!unrar e Roms.rar ROM
!python -m atari_py.import_roms ROM- เล่นเกม Pong กับ Bot โดยเมื่อจบเกมเราจะได้ไฟล์ MP4 เอาไว้ Replay ทีหลัง
env = wrap_env(gym.make('Pong-v0'))
observation = env.reset()
state = []
update_state(state,observation)
while True:
env.render()
if len(state) < 4:
action = env.action_space.sample()
else:
action = predict_action(model, state)
observation, reward, done, _ = env.step(action)
update_state(state,observation)
if done:
break
env.close()
show_video()
Show the State
แม้ว่า State ของ Pong จะมีจำนวนมาก แต่เราสามารถแสดง State ทุกๆ State ขณะที่ AI Agent กำลังเล่นเกม ด้วย DQN โดยการนิยาม intermediate_model ซึ่งจะมีการ Tranfer Weight มาจาก Model เดิม แต่ตัดชั้น Dense ออกทั้งหมด ดังต่อไปนี้
- นิยาม intermediate_model
intermediate_model = tf.keras.models.Model(inputs=model.inputs, outputs=model.layers[3].output)
intermediate_model.summary()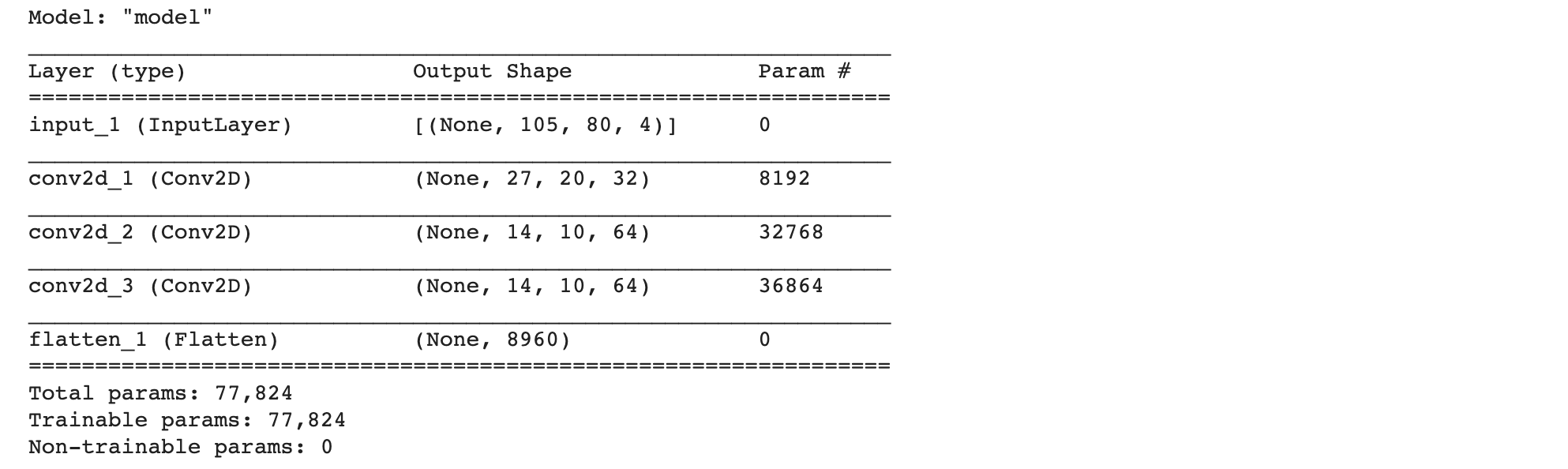
- ปรับปรุง predict_action Function โดยนอกจากจะทำนาย Action จาก 4 Screen Pixel (State) แล้ว ยังจะต้อง Return Vector จาก CNN Layer กลับมาด้วย
def predict_action(model, intermediate_model, s):
vector = intermediate_model.predict(np.array([np.stack((s[0],s[1],s[2],s[3]),axis=2)]))[0]
return np.argmax(model.predict(np.array([np.stack((s[0],s[1],s[2],s[3]),axis=2)]))[0]), vector- เล่นเกม Pong กับ Bot โดยเมื่อจบเกมเราจะได้ไฟล์ MP4 เอาไว้ Replay ทีหลัง รวมทั้งเก็บ Logs การเล่นไว้สำหรับ Plot กราฟ
env = wrap_env(gym.make('Pong-v0'))
feature_vector = []
y = []
point = 0
num_frame = 0
observation = env.reset()
state = []
update_state(state,observation)
while True:
if len(state) < 4:
action = env.action_space.sample()
else:
action, vector = predict_action(model, intermediate_model, state)
feature_vector.append(vector)
y.append(point)
num_frame+=1
observation, reward, done, _ = env.step(action)
if reward != 0:
point+=1
for i in range(len(y) - num_frame, len(y)):
y[i] = y[i]*reward
num_frame = 0
update_state(state,observation)
if done:
break
env.close()
show_video()
- แสดงจำนวน State ทั้งหมด และมิติของ Vector
len(feature_vector), feature_vector[0].shape
- ลดมิติของ Vector จาก 8,960 ให้เหลือ 2 มิติ โดยใช้ TSNE
tsne = TSNE(random_state = 99, n_components=2,verbose=1, n_iter=3000).fit_transform(feature_vector)
tsne.shape
- Plot State
tsne_pd = pd.DataFrame(tsne, columns=['x', 'y'])
y_pd = pd.DataFrame(y, columns=['point'])
df = pd.concat([tsne_pd, y_pd], axis=1)
df["point"] = df["point"].astype(str)
fig = px.scatter(df, x="x", y="y", color="point")
fig.update_layout(autosize=False, width=1200, height=600)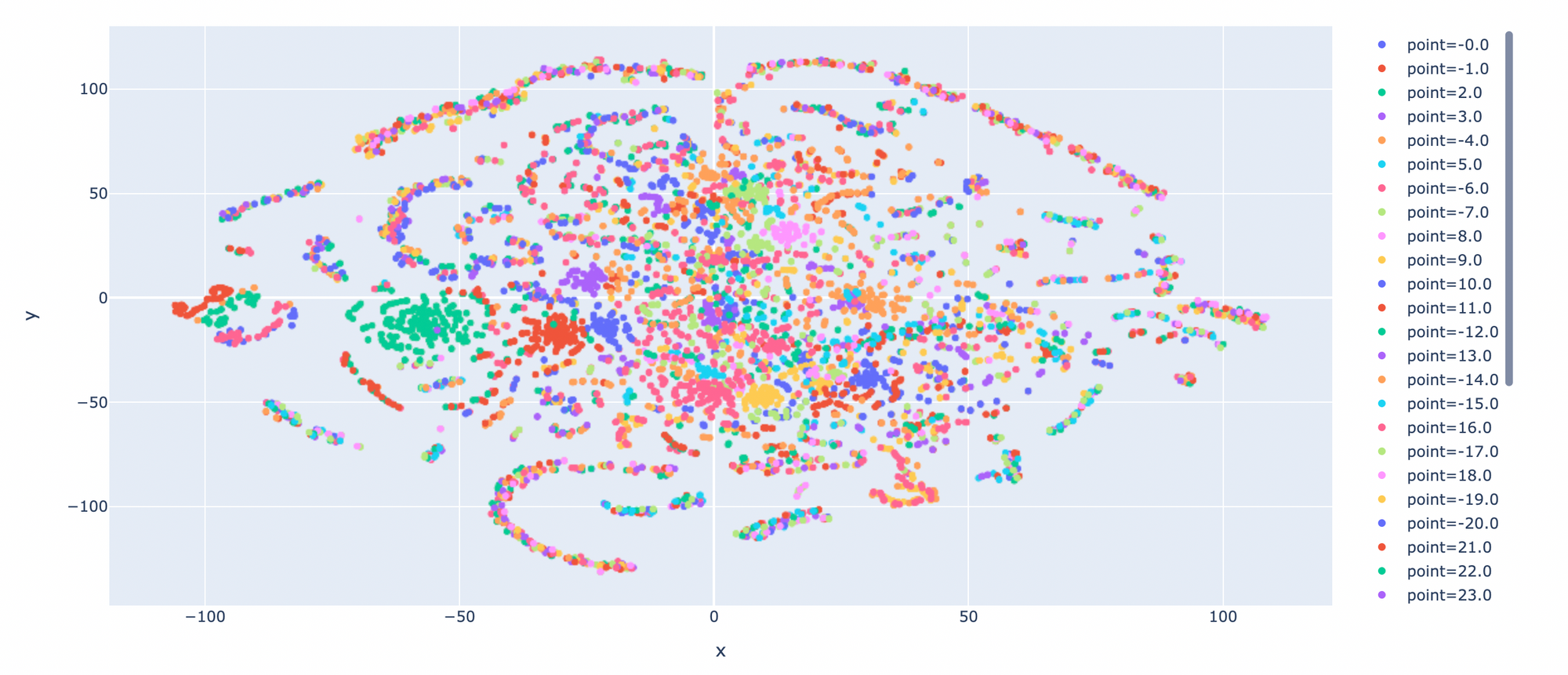
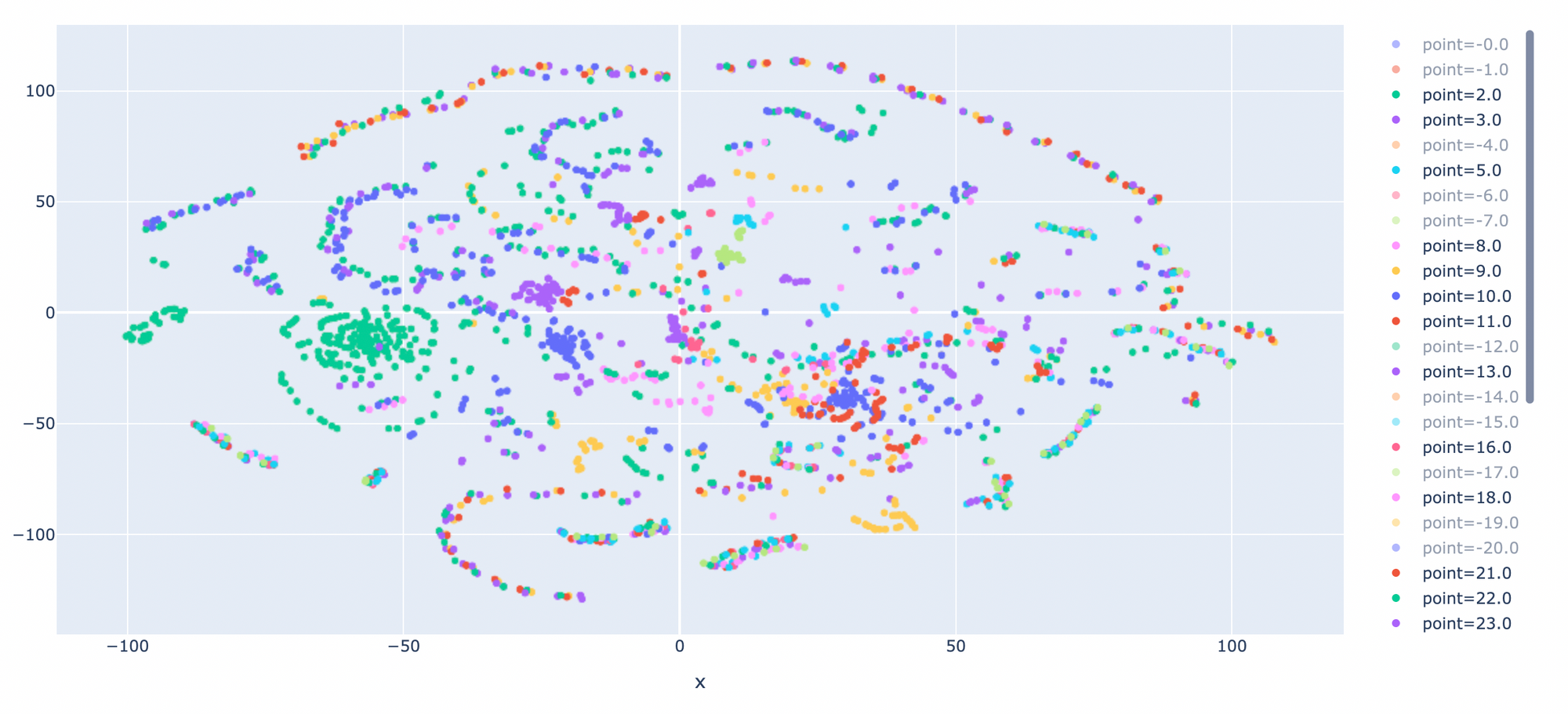
- คลิ๊กที่ Point ที่ AI Agent ชนะ (+)
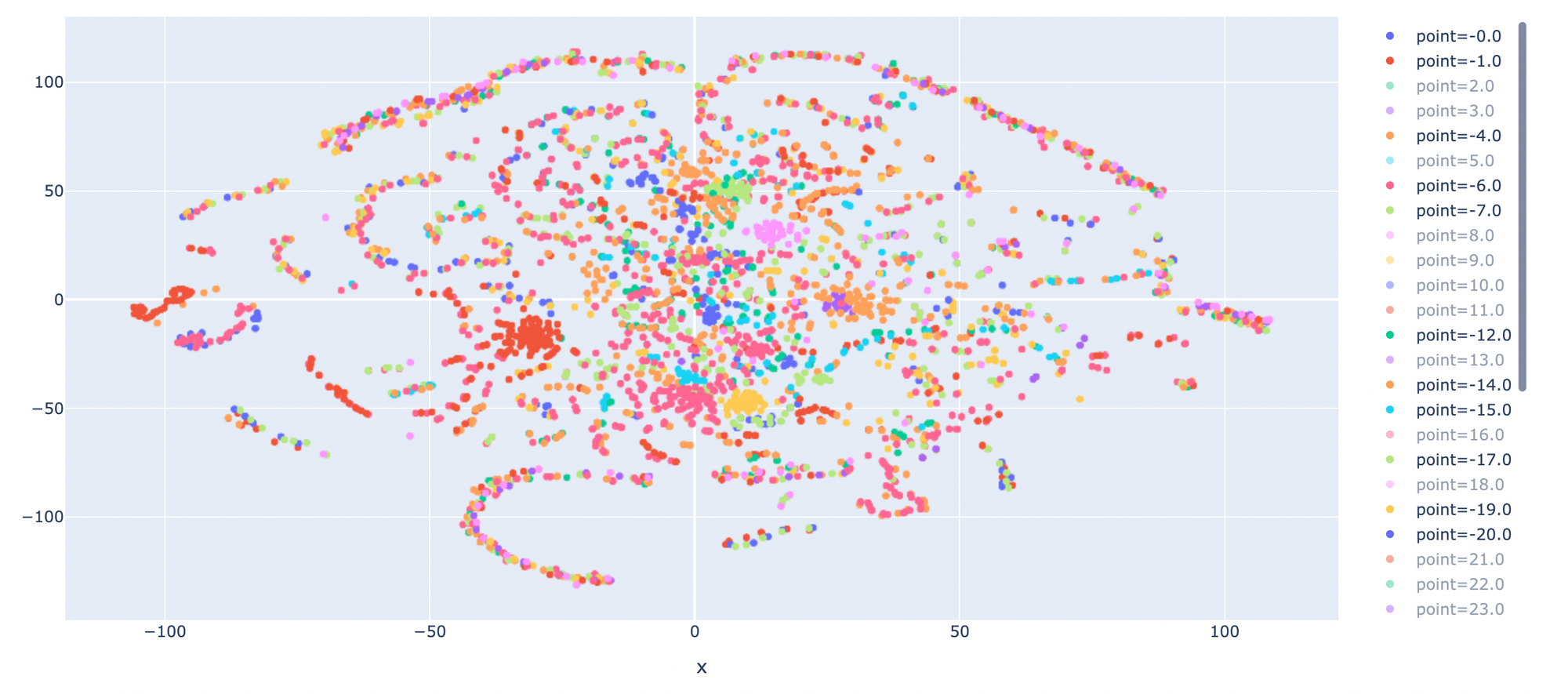
- คลิ๊กที่ Point ที่ AI Agent แพ้ (-)
** ผู้เขียนได้นำแนวคิด และ Code บางส่วนมาจาก Deep Q-Learning for Atari Breakout