Introduction to NLP


บทความโดย ผศ.ดร.ณัฐโชติ พรหมฤทธิ์
ภาควิชาคอมพิวเตอร์
คณะวิทยาศาสตร์
มหาวิทยาลัยศิลปากร
NLP (Natural Language Processing) เป็น Field หนึ่งของ Artificial Intelligence (AI) ที่จะทำให้มนุษย์มีปฏิสัมพันธ์กับคอมพิวเตอร์ด้วยภาษาธรรมชาติ หรือช่วยให้คอมพิวเตอร์เข้าใจภาษาธรรมชาติของมนุษย์
โดยในการแก้ปัญหาของงานทางด้าน NLP สมัยใหม่ มักใช้เทคนิคทาง Machine Learning เพื่อสร้าง Model จากข้อมูลอย่างเช่น ข้อความ (Text) คำพูด (Speech) หรือแม้แต่รูปภาพ (Image) หรือ Video
ปัจจุบันมี Application ทางด้าน NLP มากมาย เช่น
Speech Recognition

มีการวิจัยและพัฒนาทางด้าน Speech Recognition ในหลายสิบปีที่ผ่านมา แต่ไม่กี่ปีมานี้เราเพิ่งได้เห็นความก้าวหน้าในงานทางด้านนี้อย่างชัดเจน ปัจจุบันเรามี Software ทางด้าน Speech Recognition ที่หลากหลายบนโทรศัพท์มือถือ รวมทั้ง Virtual Assistance, Home Automation และ Video Game เป็นต้น
Document Summarization

Document Summarization คือ การสรุปเนื้อหาในเอกสารให้สั้นลง โดยยังคงได้ความหมายหลักเหมือนเอกสารต้นฉบับ แต่การทำ Document Summarization ด้วยมือ เป็นงานที่ค่อนข้างใช้เวลาและใช้แรงงานอย่างมาก การทำ Document Summarization แบบอัตโนมัติจึงได้รับความสนใจจากนักวิจัยในปัจจุบัน งานที่จะใช้ประโยชน์ต่อจากการทำ Document Summarization เช่น การแยกประเภทข้อความ (Text Classification) การถามตอบ (Question Answering) และการสรุปข่าว (News Summarization) เป็นต้น
Machine Translation
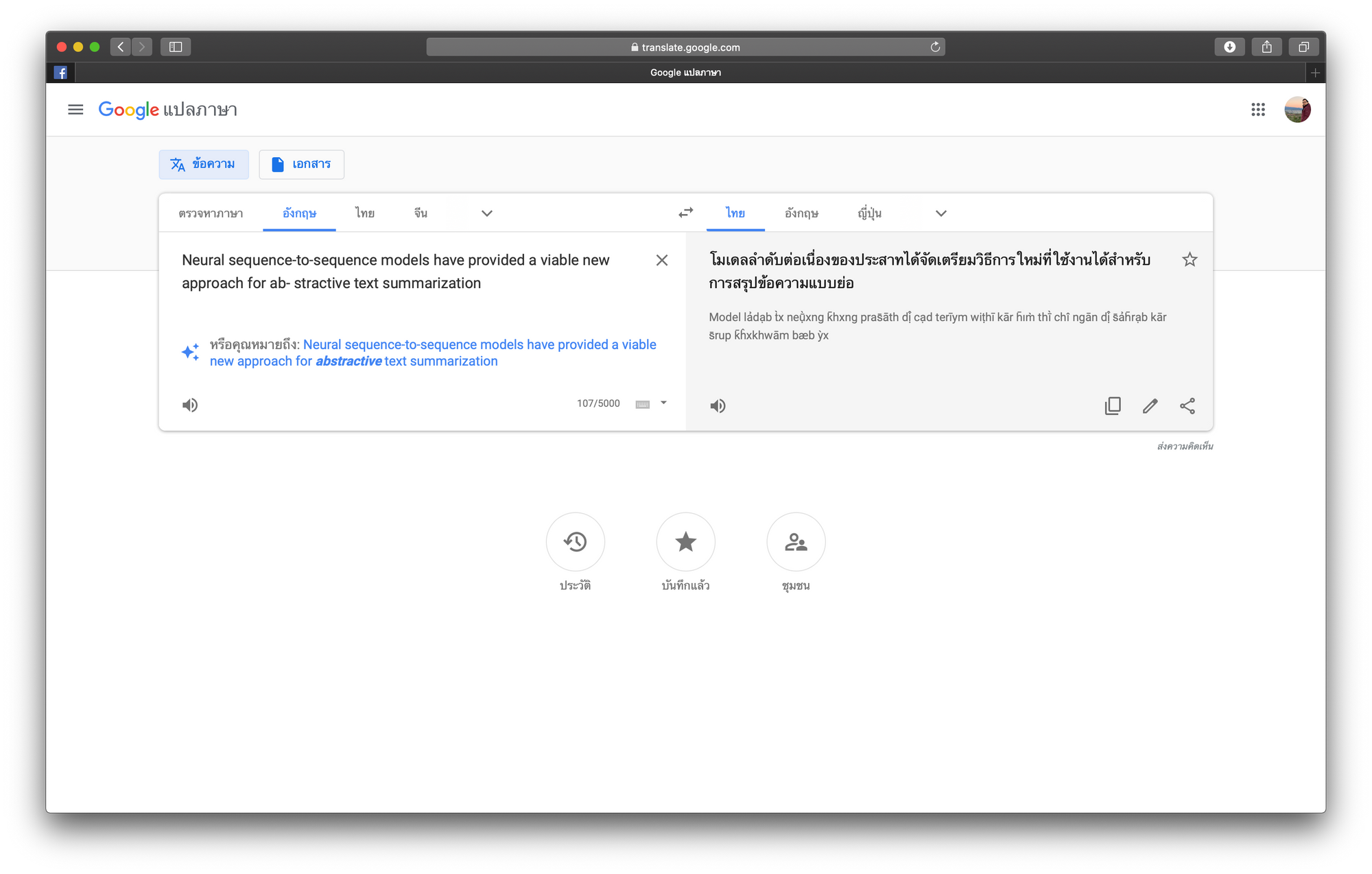
การจะให้ Computer แปลภาษามนุษย์จากภาษาหนึ่งไปอีกภาษาหนึง เป็นเรื่องที่สะดวกในปัจจุบัน ตัวอย่างของ Application ทางด้านนี้ที่ประสบความสำเร็จ คือ Google Translate แต่การแปลให้ดียิ่งขึ้นเพื่อให้เข้าใจความหมายที่แท้จริงในประโยคที่มีความคลุมเครือ และความยืดหยุ่นในการใช้ภาษาของมนุษย์ยังคงเป็นเรื่องท้าทาย
Spam Detection
Spam Detection เป็นการตรวจจับข้อความไม่พึงประสงค์ที่มักจะส่งมาทาง Email เป็นจำนวนมาก ซึ่งเมื่อตรวจจับข้อความเหล่านี้ได้จะมีการคัดแยกไว้ใน Junk Mail Box แต่ความผิดพลาดจากการทำ Spam Detection โดยเฉพาะเมื่อมีการนำนาย Email สำคัญๆ เป็น Junk Mail (False Positive) ก็อาจก่อให้เกิดความเสียหายได้ไม่น้อยครับ
Question Answering

Question Answering เป็นการค้นหาคำตอบที่ถูกต้องเพื่อตอบคำถามของมนุษย์โดยอัตโนมัติ ปัจจุบันการทำ Question Answering มีความก้าวหน้าไปพอสมควร อย่างเช่น Siri ที่สามารถตอบคำถามมนุษย์ในบางเรื่องได้ ในอนาคตเราอาจได้เห็นระบบ Question Answering ที่เต็มรูปแบบยิ่งขึ้น
Autocomplete Search
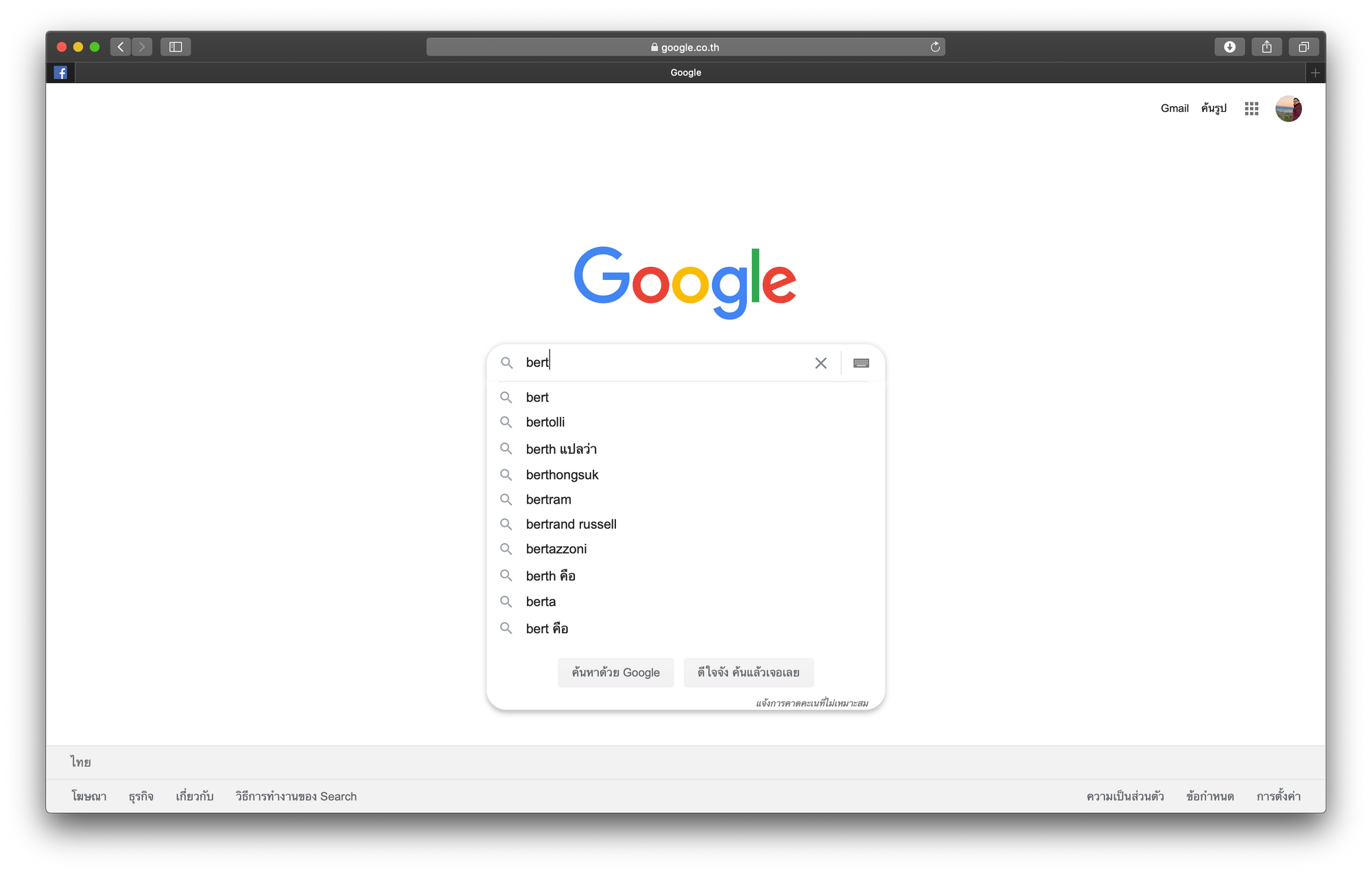
Autocomplete Search เป็นการเดาข้อความ เพื่อช่วยแนะนำ Keyword ที่สอดคล้องกับข้อความที่ผู้ใช้ได้พิมพ์ไปก่อนหน้า และอาจจะมีการแสดงข้อความแนะนำโดยเรียงตามลำดับคะแนน การเดาข้อความที่ดีจะช่วยผู้ใช้ค้นหาสิ่งที่ต้องการได้อย่างมีประสิทธิภาพครับ
Predictive Typing
Predictive Typing จะมีลักษณะที่คล้ายกับการทำ Autocomplete Search แต่มีวัตถุประสงค์ที่ต่างกัน โดย Predictive Typing จะมีการเดาข้อความเพื่อให้เราเลือก สำหรับสร้างข้อความให้สมบูรณ์ขึ้นเพื่อลดเวลาในการพิมพ์
จาก Application ทางด้าน NLP เหล่านี้ หลาย Application จะมี Input แบบ Text ซึ่งจะต้องมีกระบวนการปรับเปลี่ยนข้อมูล หรือดึง Information บางอย่างออกมา เพื่อนำไปใช้งานในขั้นต่อไป (Text Preprocessing)
Text Preprocessing
โดยผู้เขียนจะขอยกตัวอย่างเครื่องมือในการทำ Text Preprocessing ได้แก่
- การตัดประโยค
- การตัดคำ
- การเปลี่ยนรูปคำ
- การกำจัดคำที่ไม่สำคัญ (Stopwords)
- Regular Expression
- การลบ Whitespaces
- การสร้าง Bag of Word
- การสร้าง Vector แบบ TF-IDF
- การทำ Part of Speech Tagging (POS)
- การจัดกลุ่ม (Shallow Parsing)
- การทำ Named Entity Recognition
- Context Free Grammar
ก่อนอื่นเราจะ Import Natural Language Toolkit Libraries ตามตัวอย่างด้านล่าง
import nltk
#Sentence tokenizer
nltk.download('punkt')1 การตัดประโยค
ในภาษาอังกฤษเราสามารถตัดประโยคได้อย่างง่ายๆ ด้วย nltk Library ซึ่งภาษาอังกฤษมีการจบประโยคโดยใช้เครื่องหมาย '.' หรือ '?' แต่เราไม่สามาถตัดประโยคภาษาไทยได้โดยใช้ '.' หรือ '?'
ปัจจุบันยังไม่มีเครื่องมือสำหรับการตัดประโยคภาษาไทยที่มีประสิทธิภาพเพียงพอครับ
text = "Let’s start with an important point for NLP in general — this past year there has been progress in NLP by scaling up transformer type models such that each larger model, progressively improved final task accuracy by simply building a larger and larger pre-trained model. In the original BERT paper, they showed that larger hidden sizes, more hidden layers and more attention heads resulted in progressive improvements and tested up to 1024 hidden size."
sentences = nltk.sent_tokenize(text)
for sentence in sentences:
print(sentence)
text2 = 'ประเทศไทยตอนบนมีฝนฟ้าคะนองและลมกระโชกแรงบางแห่ง ขอให้ระวังอันตรายจากฝนฟ้าคะนองและลมกระโชกแรง ภาคใต้ยังมีฝนต่อเนื่อง'
sentences2 = nltk.sent_tokenize(text2)
for sentence in sentences2:
print(sentence)
print()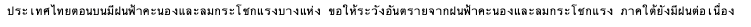
2 การตัดคำ
เราสามารถใช้ nltk ตัดคำในภาษาอังกฤษได้เช่นเดียวกับการตัดประโยค เพราะภาษาอังฤษมีการเว้นวรรคระหว่างคำ ขณะที่การตัดคำภาษาไทยนั้นค่อนข้างซับซ้อนกว่า เพราะการเขียนประโยคภาษาไทยจะไม่มีการเว้นวรรคระหว่างคำเหมือนในภาษาอังกฤษ แต่ปัจจุบันก็มีการพัฒนา Package/Library โดยฝีมือคนไทยสำหรับการตัดคำภาษาไทย ที่มีความสามารถค่อนข้างดี เช่น Deepcut และ PyThaiNLP เป็นต้น
การตัดคำภาษาอังกฤษโดยใช้ nltk.word_tokenize
for sentence in sentences:
words = nltk.word_tokenize(sentence)
print(words)
การตัดคำภาษาไทยโดยใช้ nltk.word_tokenize
for sentence in sentences2[0]:
words = nltk.word_tokenize(sentence)
print(words)
การตัดคำภาษาไทยโดยใช้ deepcut และ pythainlp
# ตัดคำด้วย deepcut
# pip install deepcut
import deepcut
tokens = deepcut.tokenize(sentences2[0])
tokens
# ตัดคำด้วย pythainlp
# pip install pythainlp
from pythainlp.tokenize import word_tokenize
text='ผมรักคุณนะครับโอเคบ่พวกเราเป็นคนไทยรักภาษาไทยภาษาบ้านเกิด'
a=word_tokenize(text)
a3 การเปลี่ยนรูปคำ
ด้วยไวยากรณ์ทางภาษา เช่นในภาษาอังกฤษ ทำให้แต่ละประโยคอาจมีรูปของคำที่แตกต่างกัน เช่น problems, problem, seen และ see ฯลฯ ซึ่งในบางครั้งความหลากหลายของรูปคำเช่นนี้อาจส่งผลต่อประสิทธิภาพในการทำนายของ Model ได้ ดังนั้นเราอาจต้องแปลงคำเหล่านี้เป็นรูปคำพื้นฐาน โดยการทำ Stemming และ Lemmatization
from nltk.stem import PorterStemmer, WordNetLemmatizer
from nltk.corpus import wordnet
nltk.download('wordnet')3.1 Stemming (การตัดส่วนขยาย)
เช่น ตัด s, es, ing หรือ ed
3.2 Lemmatization (การเปลี่ยนรูปคำให้อยู่ในรูปแบบดั้งเดิม)
am, are, is, was ‐> be
saw, seen ‐> see
def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos):
print("Stemmer:", stemmer.stem(word))
print("Lemmatizer:", lemmatizer.lemmatize(word, pos))
print("\n")
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "problems", pos = wordnet.VERB)
compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB)
compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB)
compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "are", pos = wordnet.VERB)
4 การกำจัดคำที่ไม่สำคัญ (Stopwords)
Stop Word เป็นคำที่เรานำออกไปจากข้อความแล้วยังทำให้สามารถเข้าใจความหมายของมันได้ แต่ถ้าคำเหล่านี้ยังอยู่ก็อาจจะทำให้เกิด Noise เมื่อมีการใช้เทคนิคอย่างเช่น Machine Learning
from nltk.corpus import stopwords
nltk.download('stopwords')
print(stopwords.words("english"))
stop_words = set(stopwords.words("english"))
sentence = "Our mission is to ensure that artificial general intelligence benefits all of humanity."
words = nltk.word_tokenize(sentence)
without_stop_words = []
for word in words:
if word not in stop_words:
without_stop_words.append(word)
print(without_stop_words)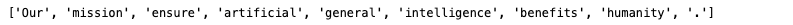
5 Regular Expression
เป็นการเขียนลำดับของตัวอักษรเพื่อสร้าง Pattern ที่ Match กับข้อความ (Text) สำหรับการลบอักขระ ตัวเลข หรือการค้นหาข้อความที่ตรงกับ Pattern ที่กำหนด ฯลฯ ดังเช่นตัวอย่างต่อไปนี้
5.1 ลบอักขระอื่นที่ไม่ใช่ตัวอักษรภาษาอังกฤษและตัวเลข
import re
sentence = "Give 100%!"
pattern = r"[^\w]"
print(re.sub(pattern, " ", sentence))
5.2 ลบตัวเลข
input_str = "Box A contains 30 red and 5 white balls, while Box B contains 4 red and 2 blue balls."
result = re.sub(r"\d", "", input_str)
print(result)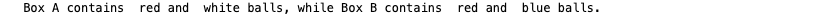
5.3 การค้นหา
txt = "ประเทศไทย ตอนบนมีฝนฟ้าคะนอง"
x = re.search("^ประเทศไทย.*ฝนฟ้าคะนอง$", txt)
# ^ Matches the start of the string
# . Any character
# + one or more
# * Zero or more occurrences
# $ Ends with
if (x):
print("YES! We have a match!")
else:
print("No match")
6 ลบ Whitespaces
input_str = " \t Hello NLP in AI course\t "
input_str = input_str.strip()
input_str
7 Bag of Word
เทคนิคทาง Machine Learnig ต่างๆ จะไม่สามารถประมวลผลข้อมูลได้จากข้อความ (Text) โดยตรง ดังนั้นเราจึงจำเป็นต้องเปลี่ยนรูปของ Text ให้เป็นกลุ่มของตัวเลข หรือ Vector โดย Bag of Word เป็นเทคนิคสำหรับการสร้าง Vector ของคำหรือประโยคที่นิยมให้กันในยุคแรกๆ ของงานทางด้าน NLP
7.1 Load Data
Load Data แล้วอ่านไฟล์
with open("test.txt", "r") as file:
documents = file.read().splitlines()
print(documents)
import pandas as pd
df = pd.DataFrame(documents, columns = ['sentence'])
df
7.2 การสร้าง Bag of Word และแสดงข้อความด้วย Vector
from sklearn.feature_extraction.text import CountVectorizer
count_vectorizer = CountVectorizer()
bag_of_words = count_vectorizer.fit_transform(documents)
feature_names = count_vectorizer.get_feature_names()
feature_names
print(df)
bag_of_words.toarray()
#แปลงเป็น Pandas Frame
wc = pd.DataFrame(bag_of_words.toarray(), columns = feature_names)
wc
8 Vector แบบ TF-IDF
อย่างไรก็ตาม Vector แบบ Bag of Word นั้นยังขาด Information ของคำสำหรับการสร้าง Model ที่มีความแม่นยำ วิธีการหนึ่งที่จะช่วยสร้าง Vector คือ เทคนิคแบบ TF-IDF
โดย TF-IDF จะใช้วิธีการทางสถิติในการประมาณความสำคัญของคำในเอกสารที่เป็นส่วนหนึ่งของ Text Dataset หรือ Corpus
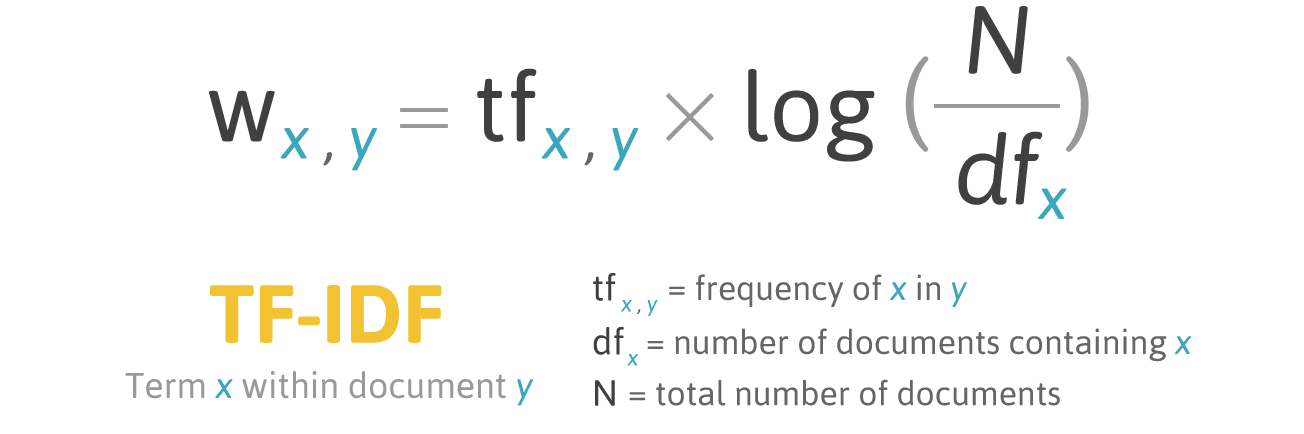
ตัวอย่างการคำนวน TF-IDF ของ "cat" ในประโยค "The cat sat on my face"
tf = 1/6
N = 2
df = 1
TF-IDF = 1/6*log(2/1) = 0.050172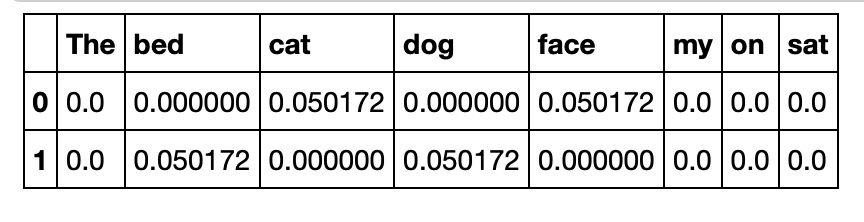
9 Part of Speech Tagging (POS)
เป็นวิธีการกำกับหน้าที่ของคำในประโยค เช่น Noun, Adjective และ Verb เป็นต้น โดยจะขอแสดงตัวอย่างการกำกับหน้าที่ของคำในประโยคโดยใช้ textblob Libraries ด้วยคำสั่งต่อไปนี้
# ภาษาอังกฤษ Work!
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from textblob import TextBlob
input_str="I like this movie, it's funny"
result = TextBlob(input_str)
print(result.tags)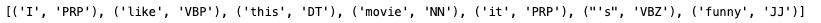
#ภาษาไทยยังไม่ Work!
input_str="ฉัน ชอบ กิน ข้าว"
result = TextBlob(input_str)
print(result.tags)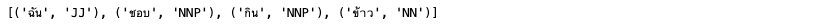
POS tag:
CC coordinating conjunction
CD cardinal digit
DT determiner (คำนำหน้านาม)
EX existential there (like: "there is" ... think of it like "there exists")
FW foreign word
IN preposition/subordinating conjunction
JJ adjective 'big' (คำคุณศัพท์)
JJR adjective, comparative 'bigger'
JJS adjective, superlative 'biggest'
LS list marker 1)
MD modal could, will
NN noun, singular 'desk' (คำนาม)
NNS noun plural 'desks'
NNP proper noun, singular 'Harrison'
NNPS proper noun, plural 'Americans'
PDT predeterminer 'all the kids'
POS possessive ending parent\'s
PRP personal pronoun I, he, she (คำสรรพนาม)
PRP$ possessive pronoun my, his, hers
RB adverb very, silently,
RBR adverb, comparative better
RBS adverb, superlative best
RP particle give up
TO to go 'to' the store.
UH interjection errrrrrrrm
VB verb, base form take
VBD verb, past tense took
VBG verb, gerund/present participle taking
VBN verb, past participle taken
VBP verb, sing. present, non-3d take (คำกิริยา)
VBZ verb, 3rd person sing. present takes (คำกิริยา)
WDT wh-determiner which
WP wh-pronoun who, what
WP$ possessive wh-pronoun whose
WRB wh-abverb where, when10 การจัดกลุ่ม (Shallow Parsing)
เป็นการจัดกลุ่มของคำตามไวยกรณ์ที่กำหนดเอง โดยก่อนจะจัดกลุ่ม เราจะต้องทำ Part of Speech Tagging กับประโยคหรือวลี แล้วนำเข้าเป็น Input เพื่อจัดกลุ่มตามไวยกรณ์ที่กำหนดไว้ต่อไป
from textblob import TextBlob
input_str="I like this movie, it's funny."
result = TextBlob(input_str)
print(result.tags)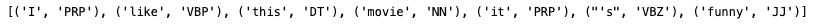
reg_exp = "NP: {<DT>?<JJ>*<NN>}"
rp = nltk.RegexpParser(reg_exp)
res = rp.parse(result.tags)
print(res)
res.draw()
? มีหรือไม่มีก็ได้
* มีอย่างน้อย 1

11 Named Entity Recognition
Named Entity คือ คำที่มีความหมายเฉพาะ เช่น ชื่อคน ชื่อหน่วยงาน เวลา หรือ ตัวเลข ฯลฯ โดยการทำ Named Entity Recognition จะช่วยในการตอบคำถามของมนุษย์ เช่น ศรีสุวรรณ ไปพักค้างคืนที่ไหน จากวรรคหนึ่งของกลอนเรื่องพระอภัยมณี ดังต่อไปนี้ "ศรีสุวรรณนั้นมาค้างอยู่ปรางศ์มาส"
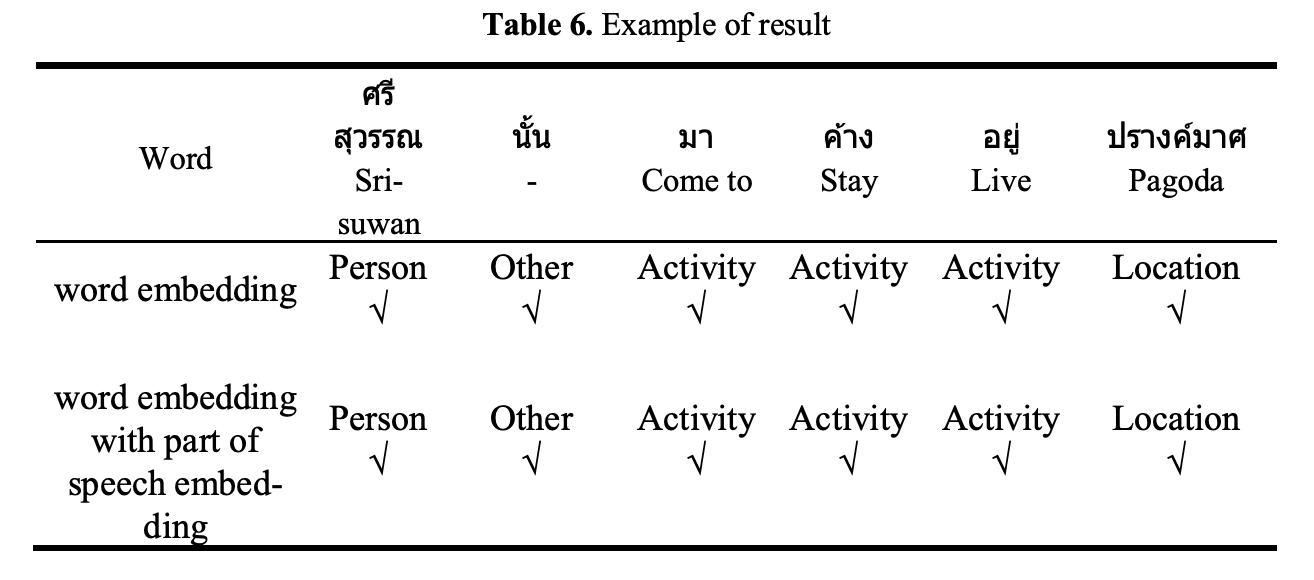
from nltk import word_tokenize, pos_tag, ne_chunk
nltk.download('maxent_ne_chunker')
nltk.download('words')
input_str = "Bob works for Silpakorn University so he went to Japan for a conference."
print(ne_chunk(pos_tag(word_tokenize(input_str))))
ตัวอย่าง NE tags
geo = Geographical Entity
org/ORGANIZATION = Organization
per/PERSON = Person
gpe = Geopolitical Entity
tim = Time indicator
art = Artifact
eve = Event
nat = Natural Phenomenon
12 Context Free Grammar
Context Free Grammar (CFG) เป็นเครื่องมือในการนิยามไวยากรณ์สำหรับภาษาต่างๆ
my_grammar = nltk.CFG.fromstring("""
S -> N V O
N -> "ฉัน" | "สุนัข" | "แมว"
V -> "กิน" | "เล่น" | "เรียน"
O -> "ข้าว" | "เกม" | "หนังสือ"
""")N : Noun (นาม)
V : Verb (กริยา)
O : OBJECT (กรรม)
sent = "ฉัน เล่น เกม".split()
rd_parser = nltk.RecursiveDescentParser(my_grammar)
for tree in rd_parser.parse(sent):
print(tree)
การสร้างประโยคอย่างง่ายจาก Context Free Gramma
from nltk.parse.generate import generate
for sentence in generate(my_grammar, n=20):
print(' '.join(sentence))
ลองทำดูครับ
"เป็นการเขียนลำดับของตัวอักษรเพื่อสร้าง Pattern ที่ Match กับข้อความ (Text) ใช้สำหรับการลบอักขระ ตัวเลข การค้นหา เป็นต้น"
จากข้อความด้านบน ลองเขียน Program โดยใช้ Regular Expression เพื่อให้ได้ผลลัพธ์ ดังนี้


Guideline
- แยกภาษาอังกฤษออกจากภาษาไทย
- แปลงข้อความภาษาอังกฤษ เป็นตัวพิมพ์เล็กทั้งหมด
- ตัดคำ และนับคำภาษาอังกฤษ
- ตัดคำ และนับคำภาษาไทย
Bonus -> TF-IDF from Scratch