Regex and SQL with Pandas for Text Preprocessing
บทความโดย อ.ดร.ณัฐโชติ พรหมฤทธิ์ และ อ.ดร.สัจจาภรณ์ ไวจรรยา
ภาควิชาคอมพิวเตอร์
คณะวิทยาศาสตร์
มหาวิทยาลัยศิลปากร
git clone http://gitlab.cpsudevops.com/nuttachot/aucc_dataset.git# pip install ipython-sqlimport pandas as pd
import sqlite3
import numpy as np%load_ext sqlIntro to Pandas (DataFrame, Series)
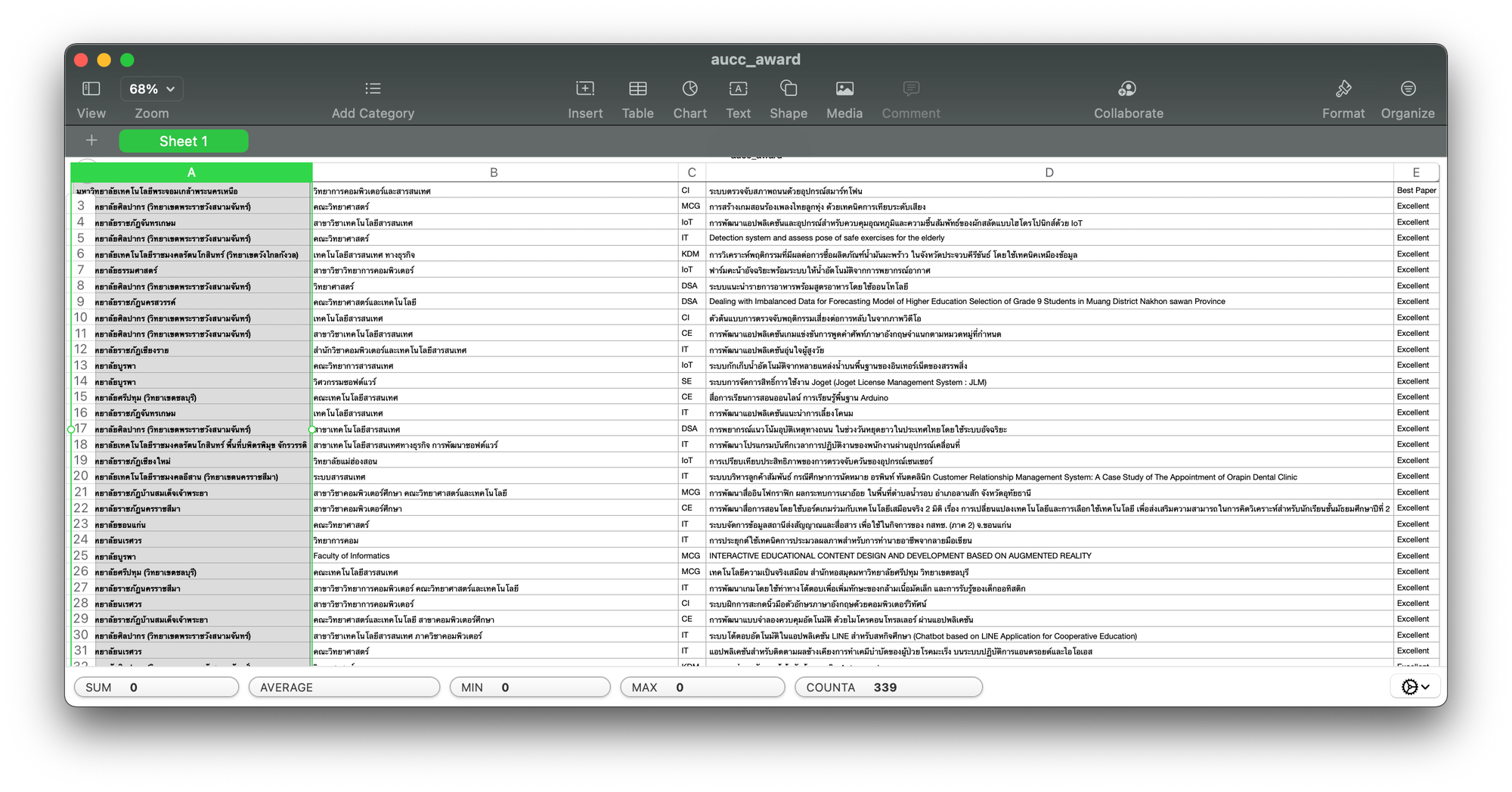
df = pd.read_csv('aucc_award.csv')
df.shape(338, 5)
df.columnsIndex(['university', 'faculty', 'Track', 'title', 'award'], dtype='object')
df.rename(columns={'Track':'track'}, inplace=True)
df.columnsIndex(['university', 'faculty', 'track', 'title', 'award'], dtype='object')
df.head()
connect = sqlite3.connect('aucc2021.db')df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)%sql sqlite:///aucc2021.db%sql select * from aucc_award_table limit 5* sqlite:///aucc2021.db
Done.
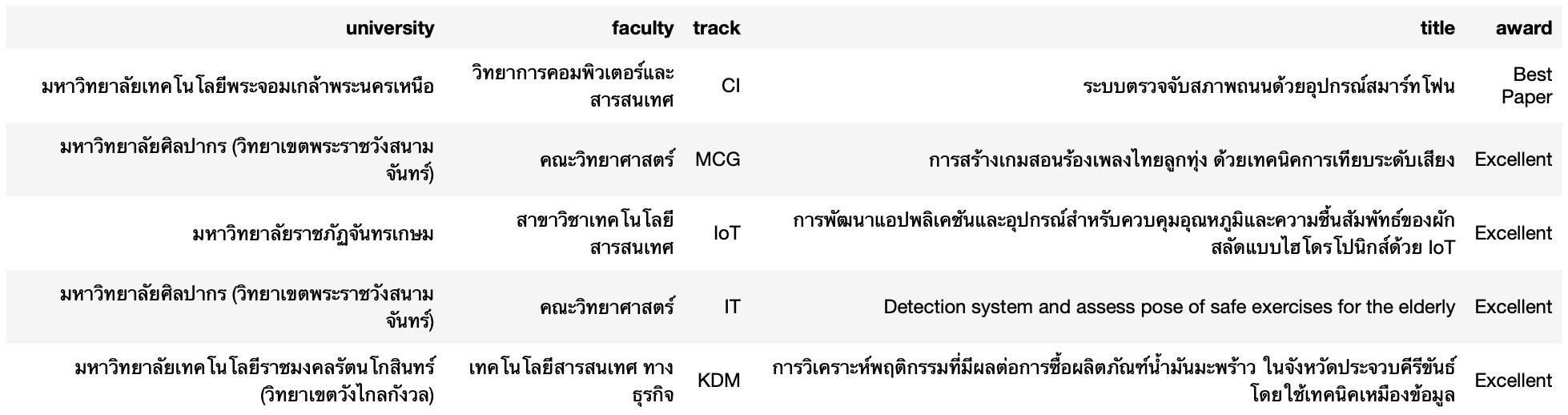
result = %sql select * from aucc_award_table* sqlite:///aucc2021.db
Done.
result.DataFrame().head()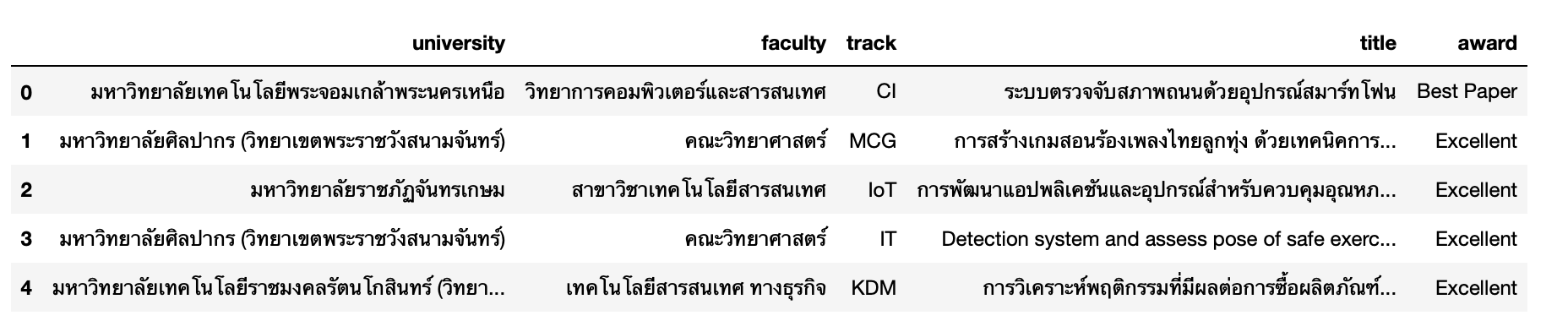
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()iloc: Select by position
loc: Select by index/label
df.iloc[1]
type(df.iloc[1])pandas.core.series.Series
df.iloc[0,2]'CI'
df.iloc[:,2]
df.iloc[:2,2]0 CI
1 MCG
Name: track, dtype: object
df.iloc[0:2]['university']
df.loc[:2,'university']
df.loc[:2, :'faculty']
df.loc[2, :'faculty']
df.loc[:,'faculty']
df['faculty']
Pandas Extract, Replace and Contains
1. แยกวิทยาเขต ออกจากชื่อมหาวิทยาลัย
example
test_df = pd.DataFrame({'university':['มหาวิทยาลัยศิลปากร (วิทยาเขตพระราชวังสนามจันทร์)','มหาวิทยาลัยเกษตรศาสตร์ (วิทยาเขตกำแพงแสน)', 'มหาวิทยาลัยเทคโนโลยีราชมงคลรัตนโกสินทร์ (พื้นที่ศาลายา)', 'มหาวิทยาลัยเกษตรศาสตร์ (วิทยาเขตเฉลิมพระเกียรติ จังหวัดสกลนคร)']})
test_df
test_df['campus']=test_df['university'].str.extract(r'(\(วิทยาเขต.*\)|\(พื้นที่.*\))')
test_df
sol
df['campus']=df['university'].str.extract(r'(\(วิทยาเขต.*\)|\(พื้นที่.*\))')
df.sample(5)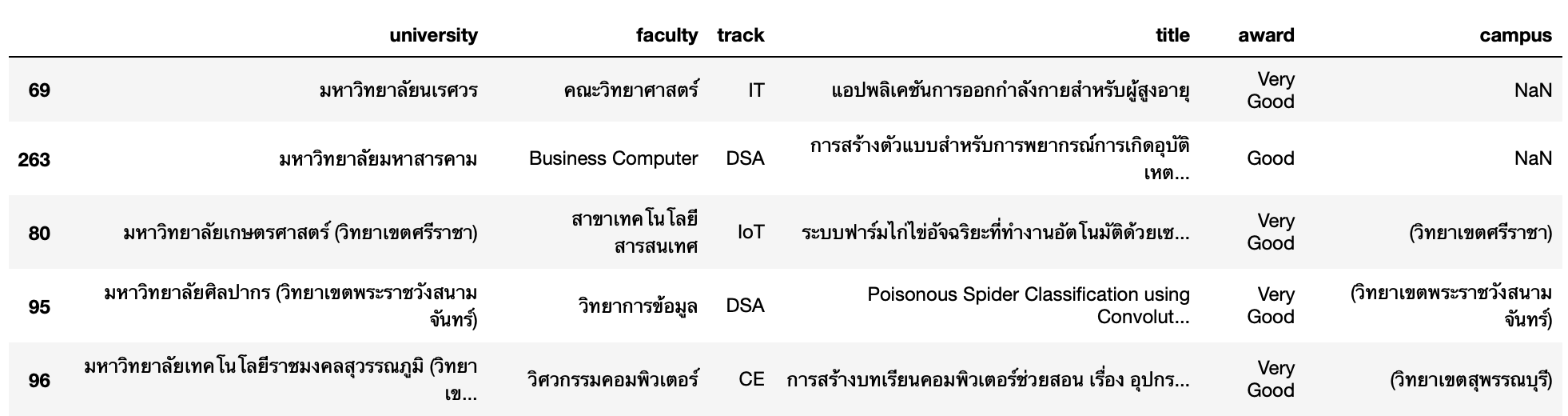
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)%%sql
select count(*)
from aucc_award_table
where campus is not Null
example
S=pd.Series(['มหาวิทยาลัยศิลปากร (วิทยาเขตพระราชวังสนามจันทร์)','มหาวิทยาลัยเกษตรศาสตร์ (วิทยาเขตกำแพงแสน)', 'มหาวิทยาลัยเทคโนโลยีราชมงคลรัตนโกสินทร์ (พื้นที่ศาลายา)', 'มหาวิทยาลัยเกษตรศาสตร์ (วิทยาเขตเฉลิมพระเกียรติ จังหวัดสกลนคร)'])
S
S.replace(r'(\(.*\))', '', regex=True, inplace = True)
S
S[0], S[0].strip() ('มหาวิทยาลัยศิลปากร ', 'มหาวิทยาลัยศิลปากร')
sol
df['university'] = df['university'].str.replace(r'(\(.*\))', '', regex=True)
df.sample(5)
df['university'] = df['university'].str.strip()
df.sample(5)
df['campus'] = df['campus'].str.replace(r'([\(\)])', '', regex=True)
df.sample(5)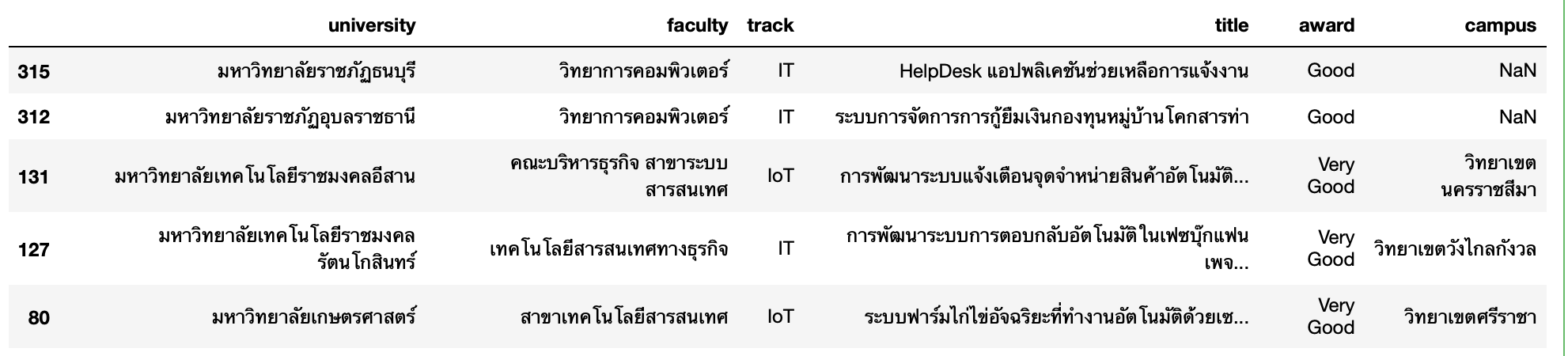
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)%%sql
select count(*)
from aucc_award_table
where campus is not Null
%%sql
select *
from aucc_award_table
where campus is Null* sqlite:///aucc2021.db
Done.
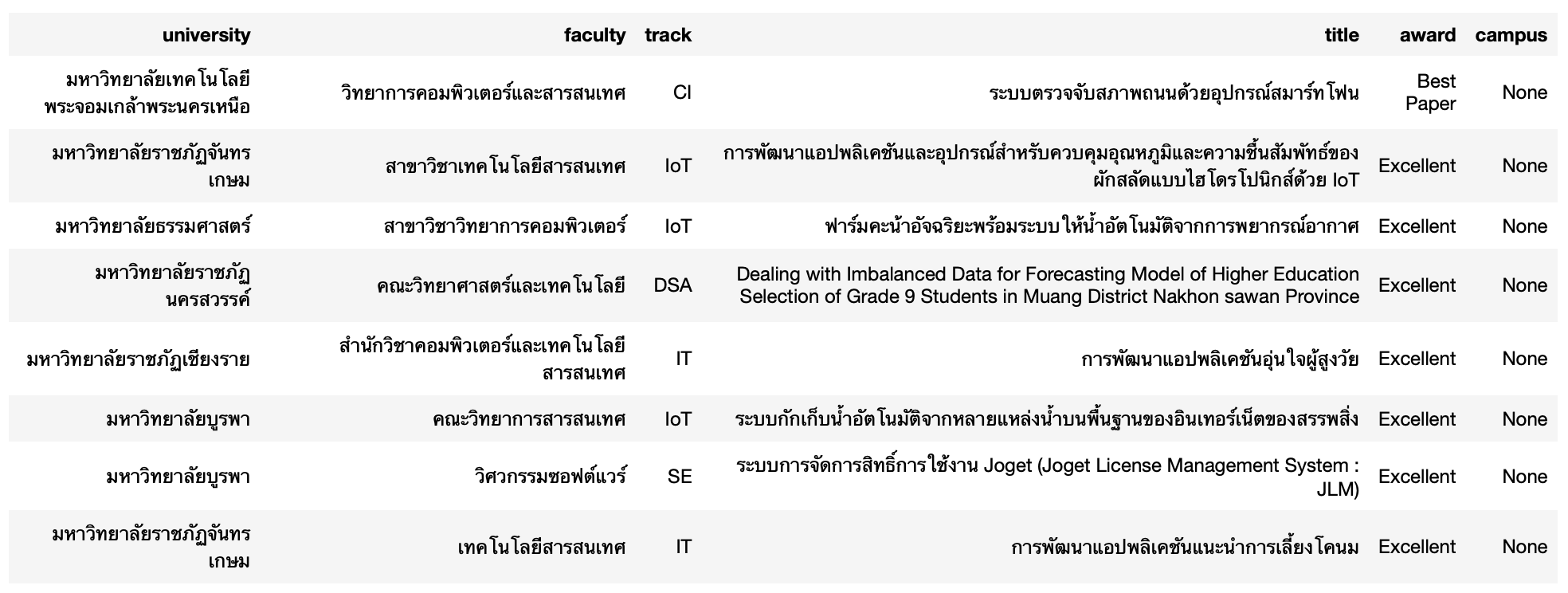
2. จำนวน paper ของแต่ละมหาวิทยาลัย (รวมทุกวิทยาเขต)
%%sql
select university, count(*) as paper
from aucc_award_table
group by university
order by paper desc* sqlite:///aucc2021.db
Done.

%%sql result <<
select university, count(*) as paper
from aucc_award_table
group by university
order by paper desc* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()
df.to_csv('university_paper.csv', encoding='utf8', index=False)
3. แยกภาควิชา สาขา ออกจากคณะ
example
S=pd.Series(['ภาควิชา คอมพิวเตอร์','สาขา วิทยาการคอมพิวเตอร์', 'สาขาวิชา วิทยาการข้อมูล', 'คณะ บริหารธุรกิจ', 'สำนักวิชา คอมพิวเตอร์และเทคโนโลยีสารสนเทศ', 'หลักสูตร การจัดการเทคโนโลยีสารสนเทศ'])
S
S.replace(r'(ภาควิชา )', 'ภาควิชา', regex=True, inplace = True)
S.replace(r'(สาขา )', 'สาขา', regex=True, inplace = True)
S.replace(r'(สาขาวิชา )', 'สาขาวิชา', regex=True, inplace = True)
S.replace(r'(คณะ )', 'คณะ', regex=True, inplace = True)
S.replace(r'(สำนักวิชา )', 'สำนักวิชา', regex=True, inplace = True)
S.replace(r'(หลักสูตร )', 'หลักสูตร', regex=True, inplace = True)
S
S.replace(r'(ภาควิชา +)', 'ภาควิชา', regex=True, inplace = True)
S.replace(r'(สาขา +)', 'สาขา', regex=True, inplace = True)
S.replace(r'(สาขาวิชา +)', 'สาขาวิชา', regex=True, inplace = True)
S.replace(r'(คณะ +)', 'คณะ', regex=True, inplace = True)
S.replace(r'(สำนักวิชา +)', 'สำนักวิชา', regex=True, inplace = True)
S.replace(r'(หลักสูตร +)', 'หลักสูตร', regex=True, inplace = True)
S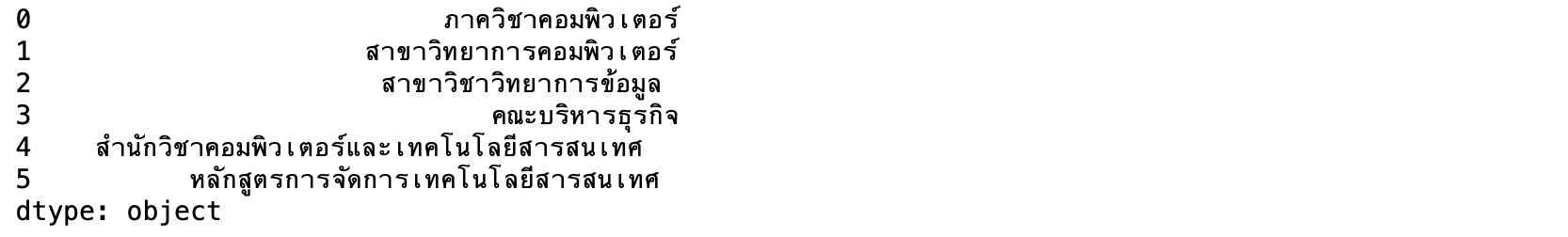
sol
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()df['faculty'] = df['faculty'].str.replace(r'(ภาควิชา +)', 'ภาควิชา', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(สาขา +)', 'สาขา', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(สาขาวิชา +)', 'สาขาวิชา', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(คณะ +)', 'คณะ', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(สำนักวิชา +)', 'สำนักวิชา', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(หลักสูตร +)', 'หลักสูตร', regex=True)
df['faculty'] = df['faculty'].str.replace(r'(วิทยาลัย +)', 'วิทยาลัย', regex=True)df.sample(5)
example
test_df = pd.DataFrame({'faculty':['ภาควิชาวิทยาการคอมพิวเตอร์และสารสนเทศ', 'ภาควิชาคอมพิวเตอร์ คณะวิทยาศาสตร์ มหาวิทยาลัยศิลปากร', 'คณะวิทยาศาสตร์ ภาควิชาวิทยาการคอมพิวเตอร์และเทคโนโลยีสารสนเทศ']})
test_df
test_df['department'] = test_df['faculty'].str.extract(r'(ภาควิชา\S+ )')
test_df
test_df['department'] = test_df['faculty'].str.extract(r'(ภาควิชา\S+ *)')
test_df
sol
df['department'] = df['faculty'].str.extract(r'(ภาควิชา\S+ *)')df['department'] = df['department'].str.strip()
df.sample(5)
df['faculty'] = df['faculty'].str.replace(r'(ภาควิชา\S+ *)', '', regex=True)
df.sample(5)
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)%%sql
select * from aucc_award_table
where department is not Null* sqlite:///aucc2021.db
Done.

example
# คณะ สำนัก วิทยาศาสตร์ วิทยาศาสตร์และเทคโนโลยี Faculty of Informatics บริหารศาสตร์ วิทยาลัยtest_df = pd.DataFrame({'faculty':['คณะวิทยาศาสตร์และเทคโนโลยี สาขาวิทยาการคอมพิวเตอร์', 'สำนักวิชาคอมพิวเตอร์และเทคโนโลยีสารสนเทศ', 'วิทยาศาสตร์', 'วิทยาศาสตร์และเทคโนโลยี','บริหารศาสตร์', 'วิทยาลัยแม่ฮ่องสอน', 'Faculty of Informatics']})
test_df
test_df['new_faculty'] = test_df['faculty'].str.extract(r'(คณะ\S+ *|สำนัก\S+ *|วิทยาลัย\S+ *|วิทยาศาสตร์และเทคโนโลยี *|วิทยาศาสตร์ *|บริหารศาสตร์ *|Faculty +of +\S+ *)')
test_df['new_faculty'] = test_df['new_faculty'].str.strip()
test_df
test_df['faculty'] = test_df['faculty'].str.replace(r'(คณะ\S+ *|สำนัก\S+ *|วิทยาลัย\S+ *|วิทยาศาสตร์และเทคโนโลยี *|วิทยาศาสตร์ *|บริหารศาสตร์ *|Faculty +of +\S+ *)', '', regex=True)
test_df['faculty'] = test_df['faculty'].str.strip()
test_df
sol
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()df['new_faculty'] = df['faculty'].str.extract(r'(คณะ\S+ *|สำนัก\S+ *|วิทยาลัย\S+ *|วิทยาศาสตร์และเทคโนโลยี *|วิทยาศาสตร์ *|บริหารศาสตร์ *|Faculty +of +\S+ *)')df['new_faculty'] = df['new_faculty'].str.strip()
df.sample(5)
df['faculty'] = df['faculty'].str.replace(r'(คณะ\S+ *|สำนัก\S+ *|วิทยาลัย\S+ *|วิทยาศาสตร์และเทคโนโลยี *|วิทยาศาสตร์ *|บริหารศาสตร์ *|Faculty +of +\S+ *)', '', regex=True)
df['faculty'] = df['faculty'].str.strip()df.sample(5)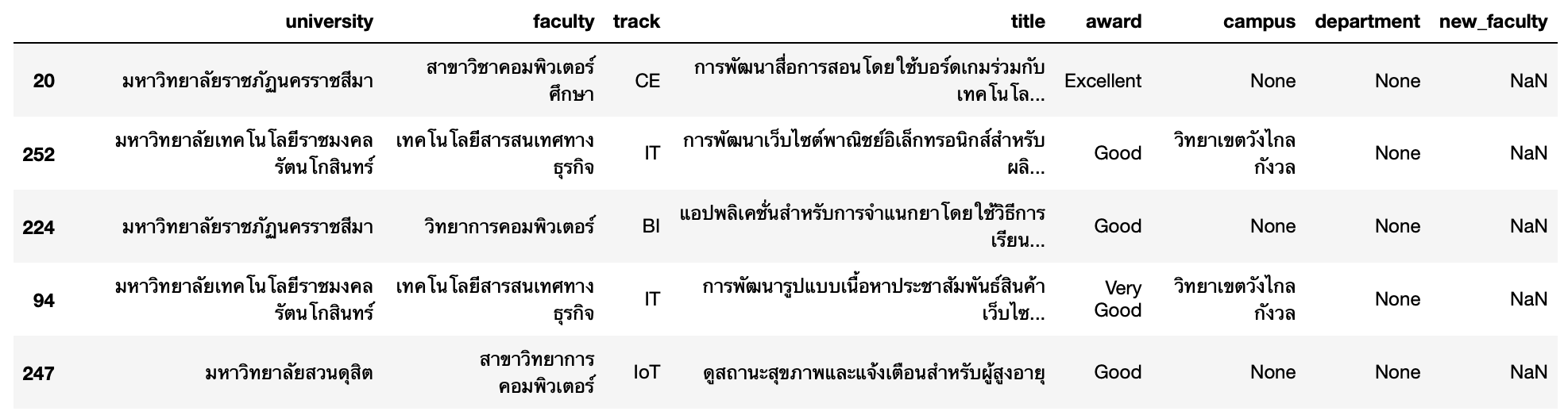
df.rename(columns={'faculty':'program'}, inplace=True)
df.columns
df.rename(columns={'new_faculty':'faculty'}, inplace=True)
df.columns
df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)%%sql
select * from aucc_award_table
where program is not ''* sqlite:///aucc2021.db
Done.
4. แต่ละมหาวิทยาลัย มีคณะ ภาควิชา สาขา อะไรบ้างที่ส่งผลงาน
%%sql
select distinct faculty
from aucc_award_table
where university = 'มหาวิทยาลัยศิลปากร' and faculty is not null
%%sql
select distinct department
from aucc_award_table
where university = 'มหาวิทยาลัยศิลปากร' and department is not null
%%sql
select distinct program
from aucc_award_table
where university = 'มหาวิทยาลัยศิลปากร' and program is not null
* ให้ นศ ปรับไม่ให้ชื่อ faculty, department และ program ซ้ำ
5. แต่ละมหาวิทยาลัยส่ง paper track อะไรบ้าง จำนวนเท่าไหร่
%%sql
select track, count(*) as paper
from aucc_award_table
where university = 'มหาวิทยาลัยศิลปากร'
group by track
%%sql
select university, track, count(*) as paper
from aucc_award_table
group by university, track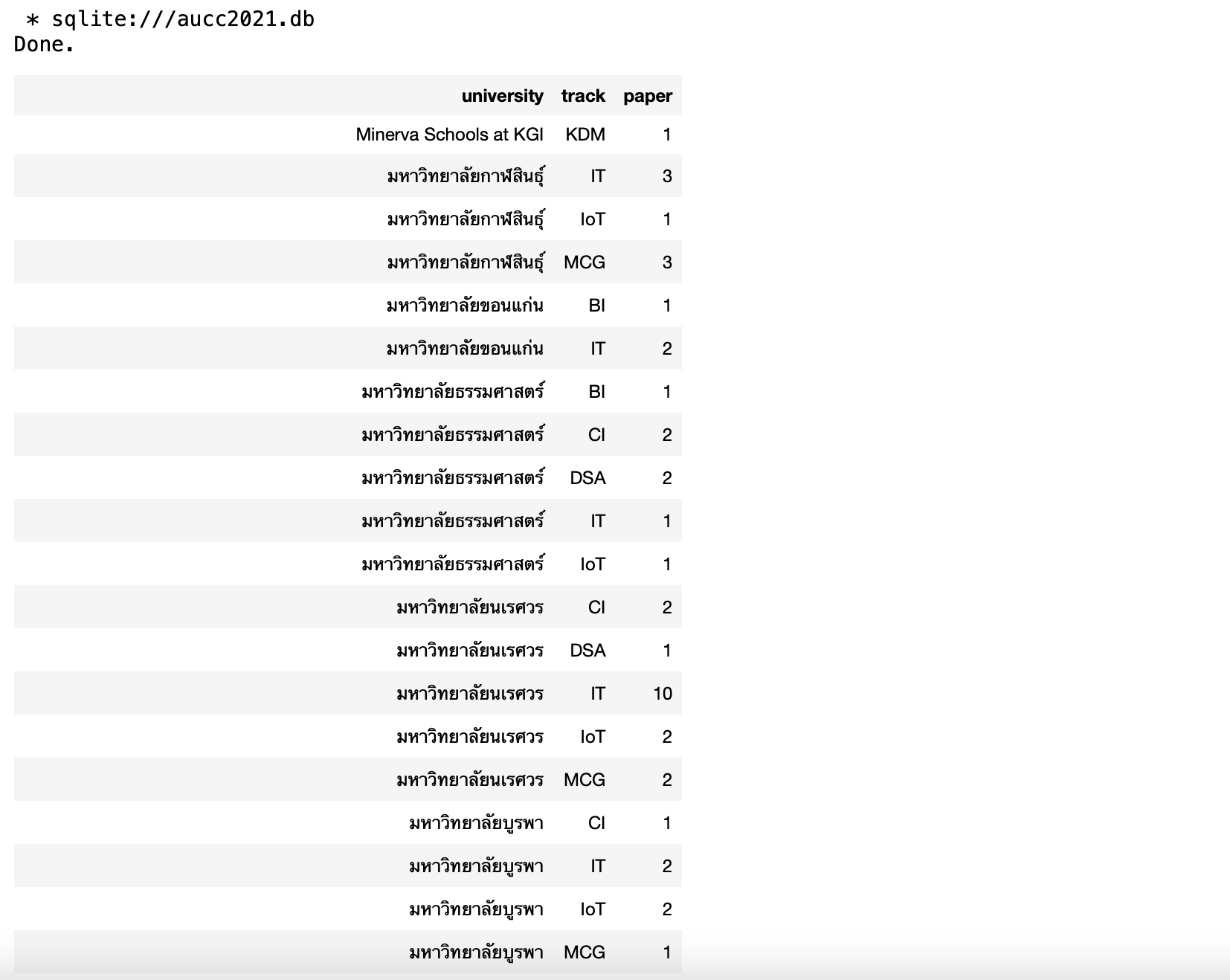
%%sql result <<
select university, track, count(*) as paper
from aucc_award_table
group by university, track* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()df.shape(102, 3)
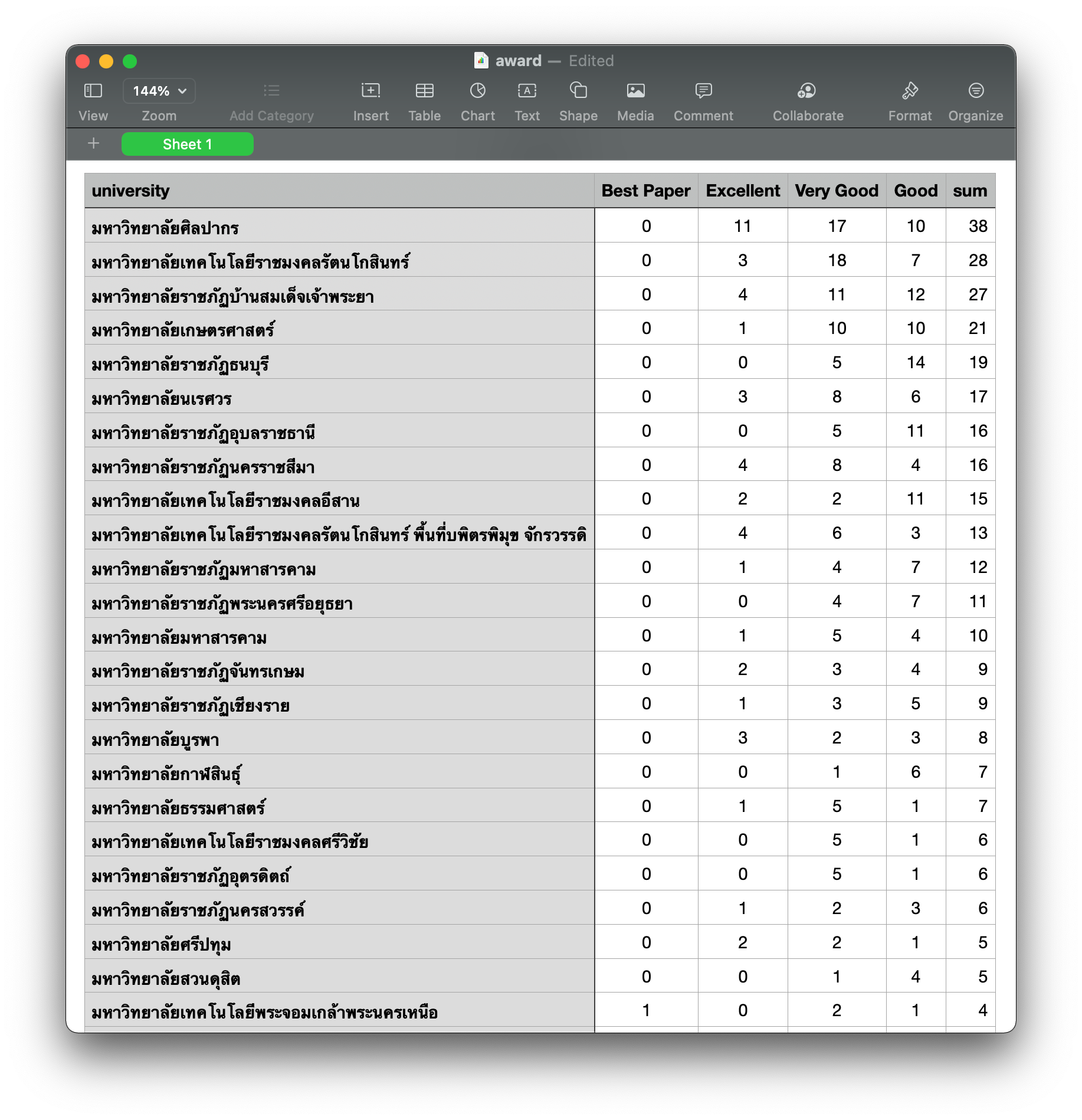
matrix = df.pivot(index='university', columns='track', values='paper')matrix.head()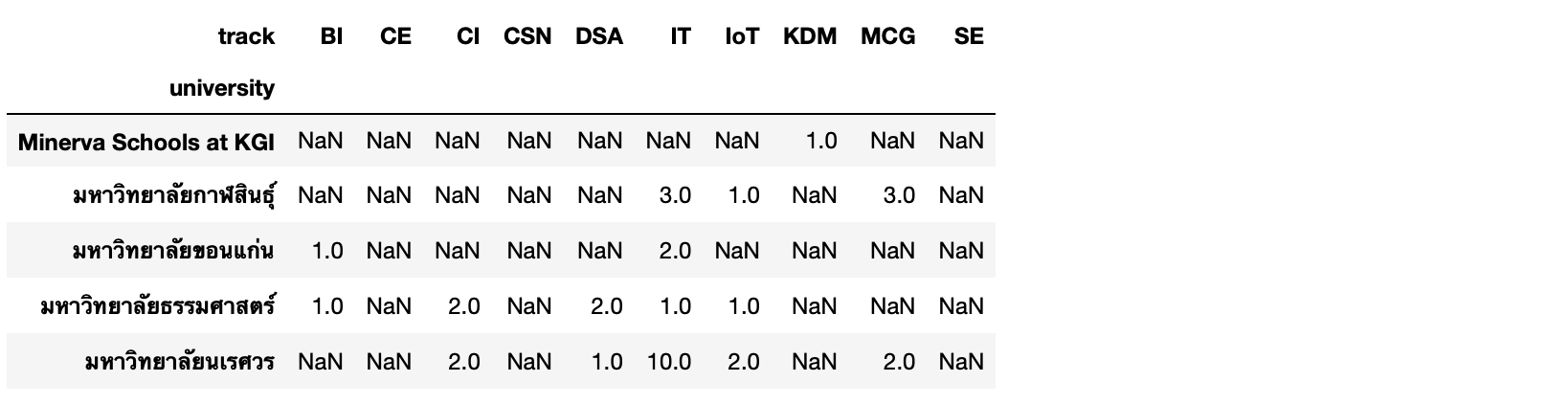
matrix.fillna(0, inplace=True)
matrix.head()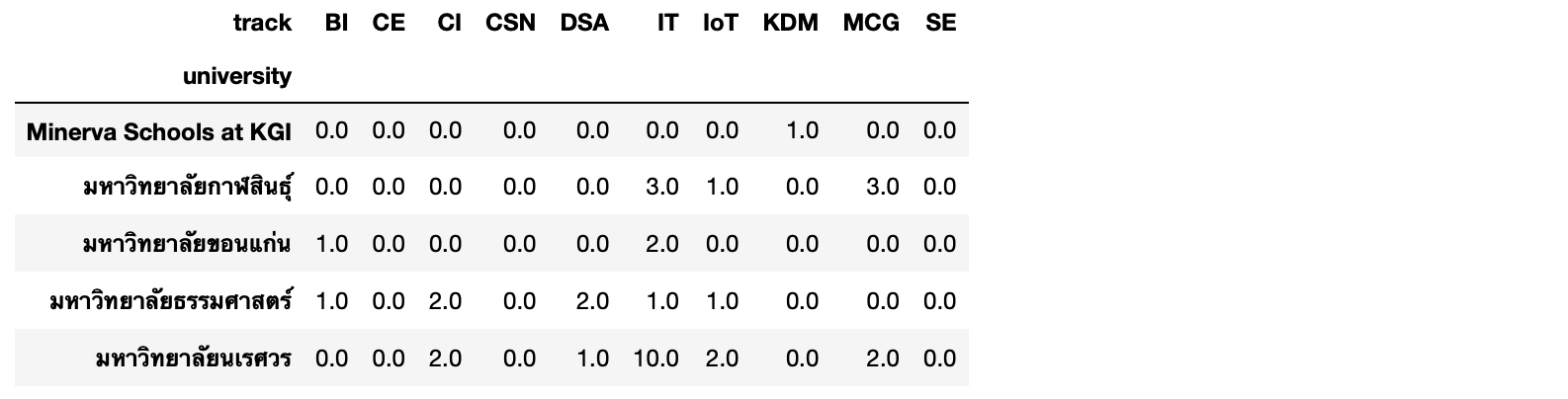
matrix = matrix.astype(int)matrix.head()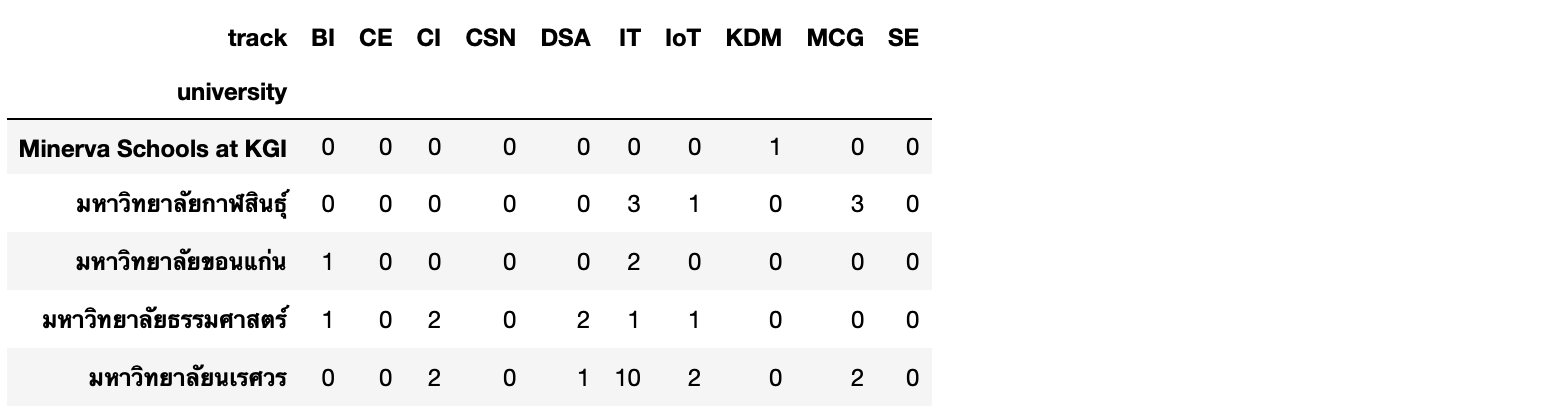
matrix['sum'] = matrix.sum(axis=1)matrix.head()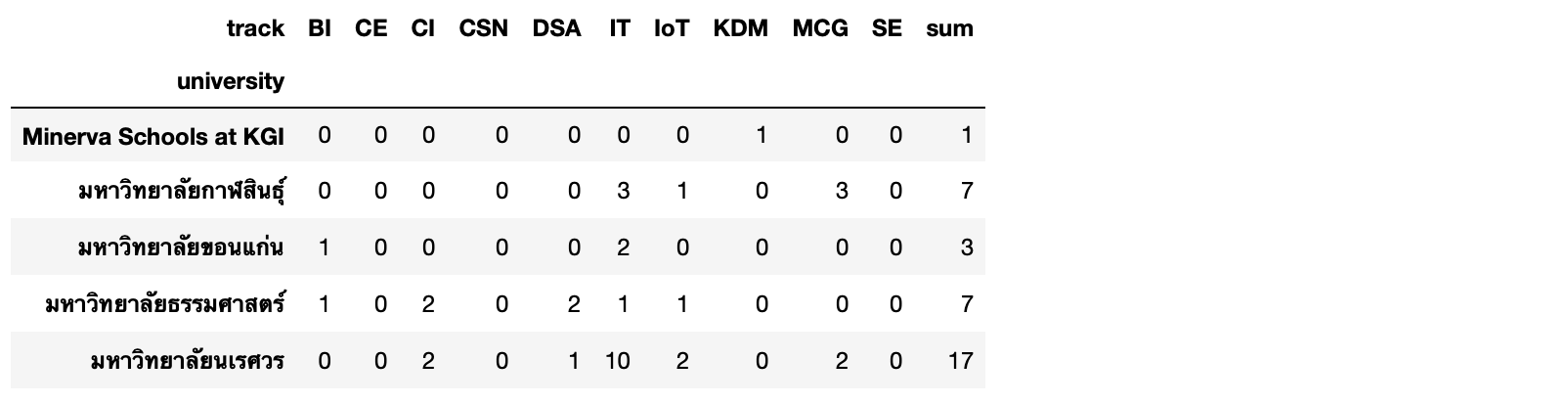
matrix = matrix.sort_values('sum', ascending=False)matrix.head()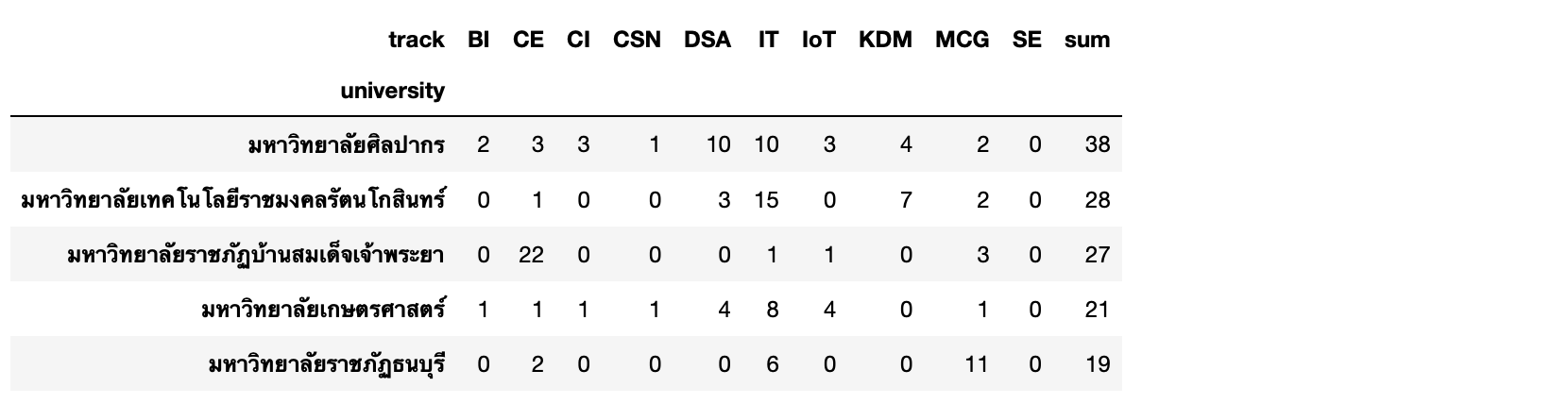
matrix.to_csv('track.csv', encoding='utf8')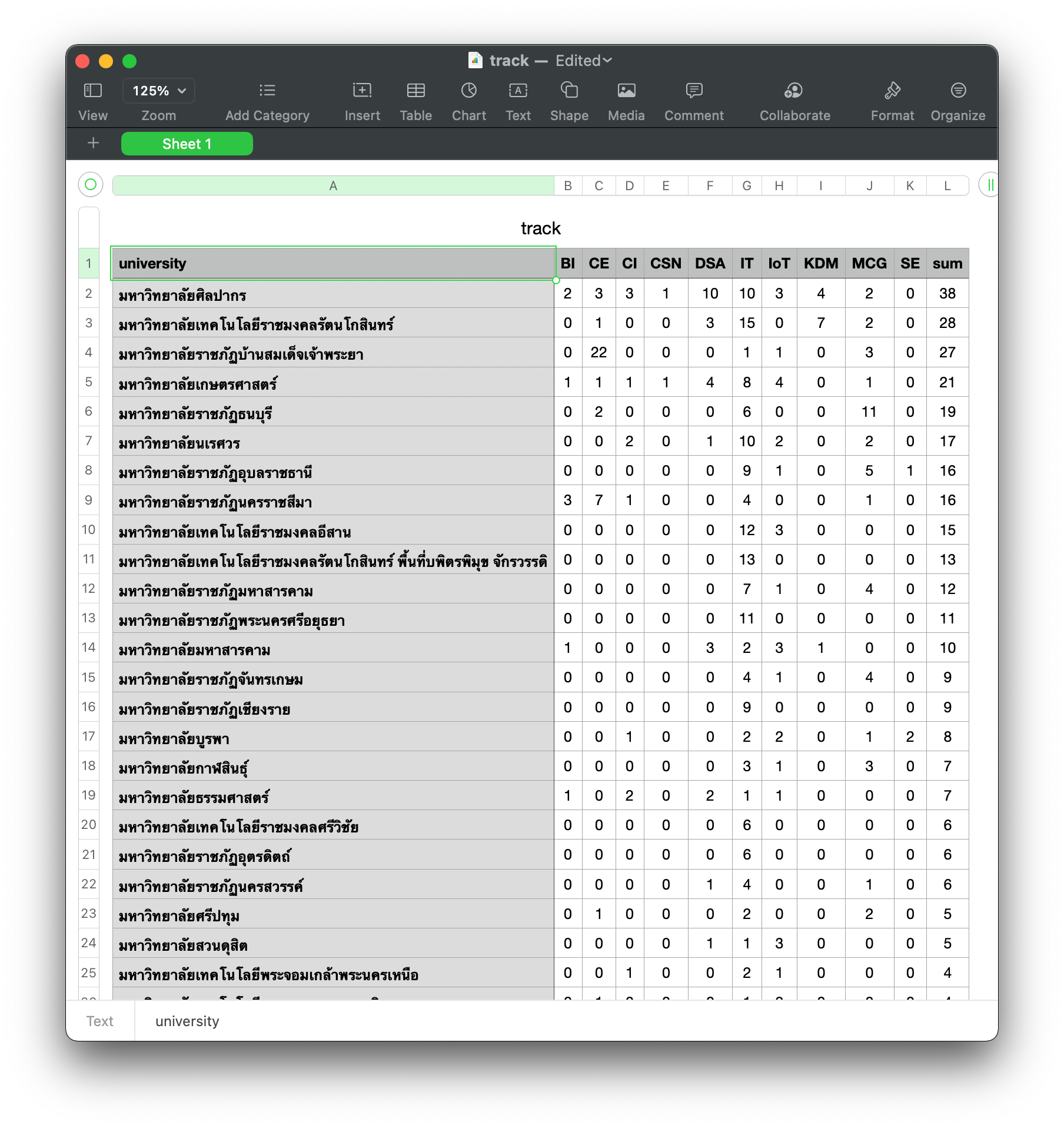
6. จำนวน paper ของแต่ละ track
%%sql
select track, count(*) as paper
from aucc_award_table
group by track
7. จำนวน Paper ภาษาไทย จำนวน paper ภาษาอังกฤษ
example
S=pd.Series(['ดูสถานะสุขภาพและแจ้งเตือนสำหรับผู้สูงอายุ','Detection system and assess pose of safe exercises for the elderly','ระบบการชำระเงินผ่านธนาคารไทยพาณิชย์ SCB EasyApp Payment'])
S
S.str.contains('[ก-๙]')
sol
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()df['th'] = df['title'].str.contains('[ก-๙]')df.to_sql("aucc_award_table", connect, if_exists='replace', index=False)%%sql
select count(*) as thai
from aucc_award_table
where th=True
%%sql
select count(*) as eng
from aucc_award_table
where th=False
%%sql
select count(*)
from aucc_award_table
*ไม่มีชื่อ Paper 1
8. จำนวน Paper ที่เกี่ยวกับการพัฒนา Chatbot (โต้ตอบอัตโนมัติ)
example
S=pd.Series(['การพัฒนาระบบโต้ตอบอัตโนมัติด้วยไดอล็อกโฟลสำหรับเฟซบุ๊กแฟนเพจ','ระบบโต้ตอบอัตโนมัติในแอปพลิเคชัน LINE สำหรับสหกิจศึกษา (Chatbot based on LINE Application for Cooperative Education)','ระบบติดตามสถานการณ์ดำเนินงานของเจ้าหน้าที่ผ่าน Line chatbot', 'การสร้างเกมสอนร้องเพลงไทยลูกทุ่ง ด้วยเทคนิคการเทียบระดับเสียง'])
S
S.str.contains(r'โต้ตอบอัตโนมัติ|[Cc]hatbot')
sol
%%sql result <<
select *
from aucc_award_table* sqlite:///aucc2021.db
Done.
Returning data to local variable result
df = result.DataFrame()df[df['title'].str.contains(r'โต้ตอบอัตโนมัติ|[Cc]hatbot')==True]
df[df['title'].str.contains(r'โต้ตอบอัตโนมัติ|[Cc]hatbot')==True].shape(3, 9)
9. จำนวน Paper ที่เกี่ยวกับการจำแนกข้อมูล
example
S=pd.Series(['การจำแนกเสียงอ่านร้อยกรองไทย โดยใช้โครงข่ายประสาทเทียม (Thai Poetry Reading Sound Classification using Neural Network)','Poisonous Spider Classification using Convolutional Neuron', 'ระบบจัดการร้านรับซื้อ-ขายผ้าอเนกประสงค์'])
S
S.str.contains(r'จำแนก|[Cc]lassification')
sol
df[df['title'].str.contains(r'จำแนก|[Cc]lassification')==True]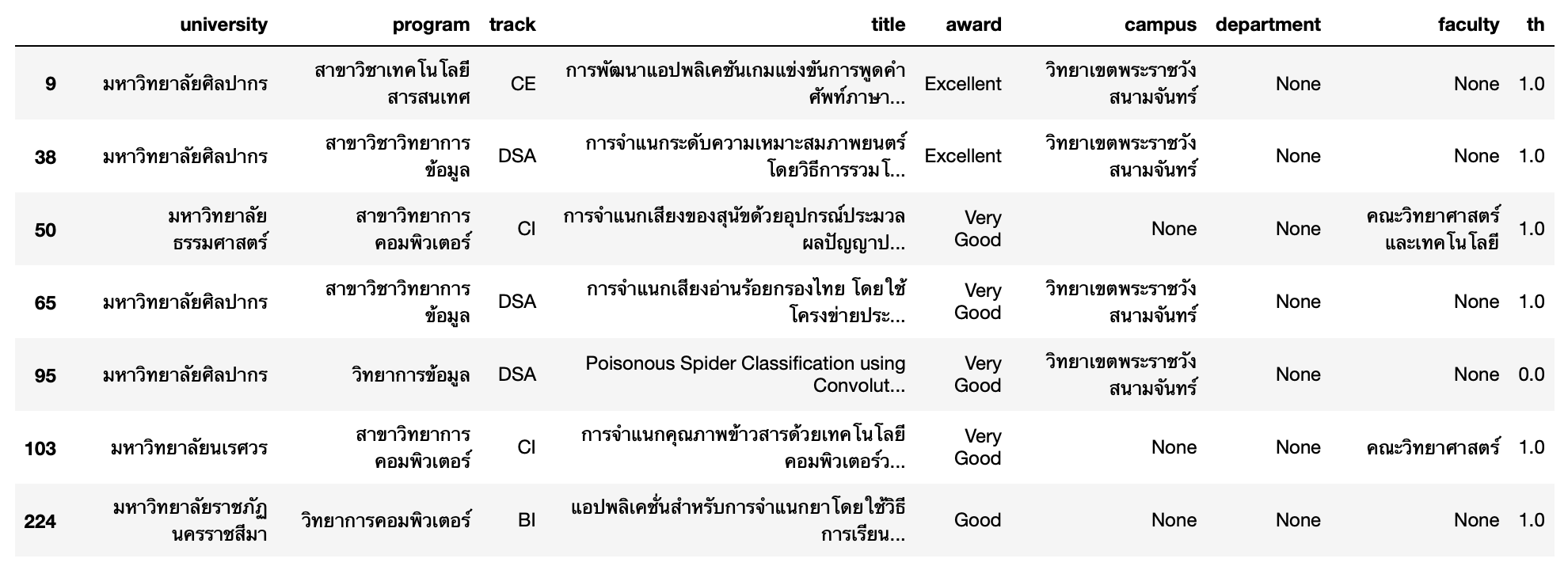
df[df['title'].str.contains(r'จำแนก|[Cc]lassification')==True].shape(7, 9)
10. จำนวนรางวัล แต่ละรางวัลที่แต่ละมหาวิทยาลัยได้รับ?