การวิเคราะห์ประสิทธิภาพ Machine Learning Model ด้วย Learning Curve


บทความโดย ผศ.ดร.ณัฐโชติ พรหมฤทธิ์
ภาควิชาคอมพิวเตอร์
คณะวิทยาศาสตร์
มหาวิทยาลัยศิลปากร
Learning Curve เป็นสิ่งที่แสดงถึงประสิทธิภาพการเรียนรู้ของ Model จาก Training Dataset ซึ่งแกน x ของกราฟจะเป็น Epoch และแกน y จะเป็นประสิทธิภาพของ Model โดยประสิทธิภาพของ Model จะถูกวัดหลังจากการปรับปรุง Weight และ Bias ด้วยข้อมูล 2 ชนิด ได้แก่ "Training Dataset ที่ Model กำลังเรียนรู้" และ "Validation Dataset ที่ไม่เคยถูกใช้สอน Model มาก่อน"
ประสิทธิภาพของ Model จะวัดจาก Loss และ Accuracy โดยยิ่งค่า Loss หรือ Error ของ Model น้อย แสดงว่า Model มีการเรียนรู้ที่ดี แต่สำหรับค่า Accuracy จะเป็นในทางตรงกันข้าม คือยิ่งค่า Accuracy มากแสดงว่า Model มีการเรียนรู้ที่ดี
การวินิจฉัยและแก้ไขปัญหาการเรียนรู้ของ Model อย่างเช่น ปัญหา Underfitting และ Overfitting ได้ เราจะต้องมีความเข้าใจรูปแบบ Learning Curve ที่เกิดขึ้น นอกจากนี้เรายังสามารถพิจารณาจาก Learning Curve ได้ว่า Training Dataset และ Validation Dataset เป็นตัวแทนของ Data ที่เหมาะสมในกระบวนการพัฒนา Model หรือไม่
ในบทความนี้ผู้อ่านจะได้ทำความเข้าใจรูปแบบของ Learning Curve ที่สำคัญได้แก่ Underfit Learning Curve, Overfit Learning Curve, Good Fit Learning Curve รวมทั้งรูปแบบของ Learning Curve ที่แสดงว่า Training Dataset และ Validation Dataset เป็นตัวแทนของ Data ที่ไม่ดีครับ
Underfit Learning Curve
Learning Curve แบบ Underfitting จะบ่งบอกว่า Model ไม่สามารถเรียนรู้ได้จาก Training Dataset
โดยเราจะจำลองสถานการณ์ของ Model ที่มีปัญหาการเรียนรู้แบบ Underfit ด้วยการพัฒนา Model เพื่อทำ Sentiment Analysis จาก IMDB Dataset ซึ่งเป็นคำวิจารณ์ภาพยนตร์ต่างประเทศ ตามขั้นตอนดังต่อไปนี้
- ก่อนอื่นเราจะ Import Library ที่จำเป็นต้องใช้ในการทดลองดังต่อไปนี้
import tensorflow as tf
imdb = tf.keras.datasets.imdb
to_categorical = tf.keras.utils.to_categorical
sequence = tf.keras.preprocessing.sequence
import plotly
import plotly.graph_objs as go
import plotly.express as px
from matplotlib import pyplot
import numpy
from sklearn.datasets import make_circles, make_blobs
from sklearn.model_selection import train_test_split
from pandas import DataFrame
import pandas as pd
import warnings
warnings.filterwarnings('ignore')- Load IMDB Dataset
top_words = 5000
(x_train, y_train), (x_val, y_val) = imdb.load_data(num_words=top_words)
max_words = 500
x_train.shape, y_train.shape, x_val.shape, y_val.shape((25000,), (25000,), (25000,), (25000,))
imdb.get_word_index()
- Concat Train และ Validate Dataset เพื่อคำนวณคำที่ไม่ซ้ำทั้งหมด
x = numpy.concatenate((x_train, x_val), axis=0)
print("Number of words:", len(numpy.unique(numpy.hstack(x))))Number of words: 4998
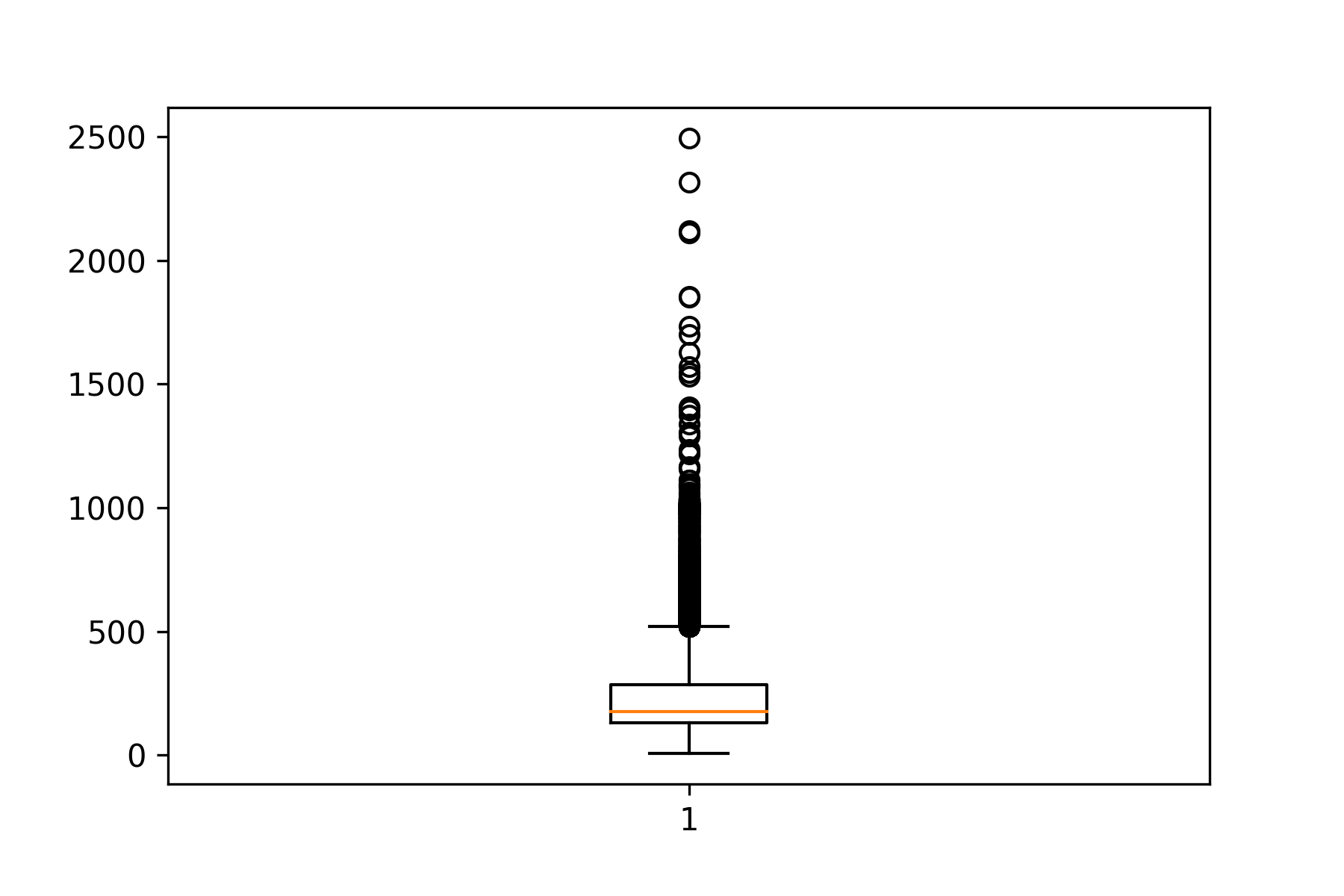
- ดูความยาวของคำในประโยค
print("Review length: ")
result = [len(st) for st in x]
print("Mean %.2f words (%f)" % (numpy.mean(result), numpy.std(result)))
pyplot.boxplot(result)
pyplot.savefig('review_length.png', dpi = 300)
- เติม 0 (ศูนย์) เพื่อทำให้ความยาวของประโยคเท่ากัน (Padding)
x_train = sequence.pad_sequences(x_train, maxlen=max_words)
x_val = sequence.pad_sequences(x_val, maxlen=max_words)
x_train.shape(25000, 500)
- นิยาม Model
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(4, input_dim=max_words, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
- Train Model
history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=200, batch_size=128, verbose=2)
- Plot Loss
h1 = go.Scatter(y=history.history['loss'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="loss"
)
h2 = go.Scatter(y=history.history['val_loss'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_loss"
)
data = [h1,h2]
layout1 = go.Layout(title='Loss',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Underfit')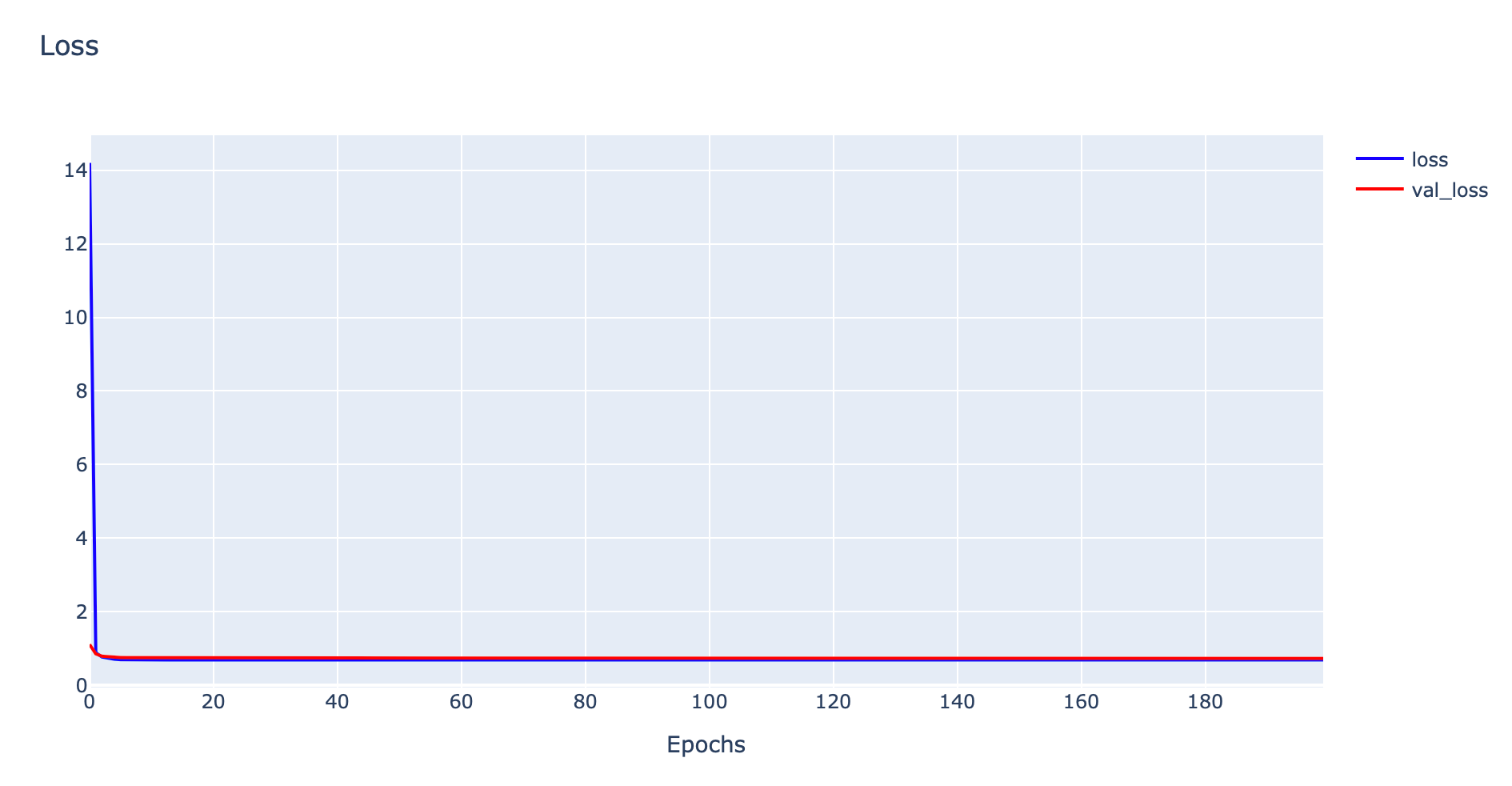
- Plot Accuracy
h1 = go.Scatter(y=history.history['accuracy'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="acc"
)
h2 = go.Scatter(y=history.history['val_accuracy'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_acc"
)
data = [h1,h2]
layout1 = go.Layout(title='Accuracy',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Underfit')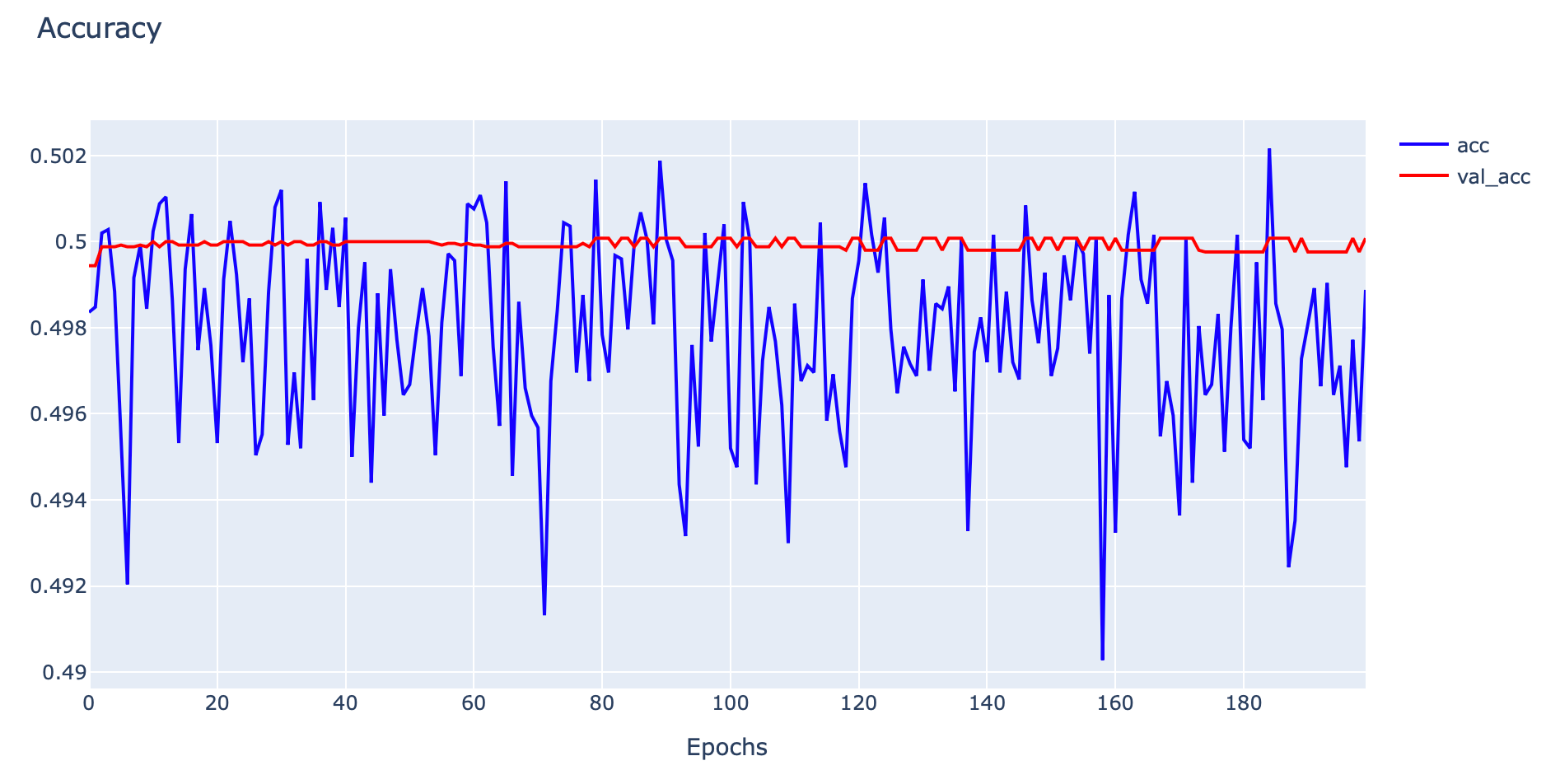
จากกราฟ Loss จะเห็นว่าตั้งแต่ Epoch ที่ 1 ค่า Training Loss จะค่อนข้างราบเรียบ ไม่ลดลง และจากกราฟ Accuracy ค่า Training Accuracy จะเหวี่ยงไปมา ไม่มีแนวโน้มจะเพิ่มขึ้น ซึ่งรูปแบบ Learning Curve ดังกล่าว แสดงให้เห็นว่า Model ของเราเกิดปัญหา Underfitting ครับ
Overfit Learning Curve
Learning Curve แบบ Overfitting จะบ่งบอกว่า Model มีการเรียนรู้ที่ดีเกินไปจาก Training Dataset ซึ่งรวมทั้งรูปแบบของ Noise หรือความผันผวนของ Training Dataset
ซึ่งเราจะจำลองสถานการณ์ของ Model ที่มีปัญหาการเรียนรู้แบบ Overfitting ด้วยการพัฒนา Model เพื่อ Classfify ข้อมูลจำนวน 2 Class โดยมีขั้นตอนดังต่อไปนี้
- สร้าง Dataset แบบ 2 Class โดยใช้ Function make_circles ของ Sklearn
x, y = make_circles(n_samples=500, noise=0.2, random_state=1)- แบ่งข้อมูลสำหรับ Train และ Validate โดยการสุ่มในสัดส่วน 50:50
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.5, shuffle= True)
x_train.shape, y_train.shape, x_val.shape, y_val.shape((250, 2), (250,), (250, 2), (250,))
- นำ Dataset ส่วนที่ Train มาแปลงเป็น DataFrame โดยเปลี่ยนชนิดข้อมูลใน Column "class" เป็น String เพื่อทำให้สามารถแสดงสีแบบไม่ต่อเนื่องได้ แล้วนำไป Plot
x_train_pd = pd.DataFrame(x_train, columns=['x', 'y'])
y_train_pd = pd.DataFrame(y_train, columns=['class'])
df = pd.concat([x_train_pd, y_train_pd], axis=1)
df["class"] = df["class"].astype(str)fig = px.scatter(df, x="x", y="y", color="class")
fig.show()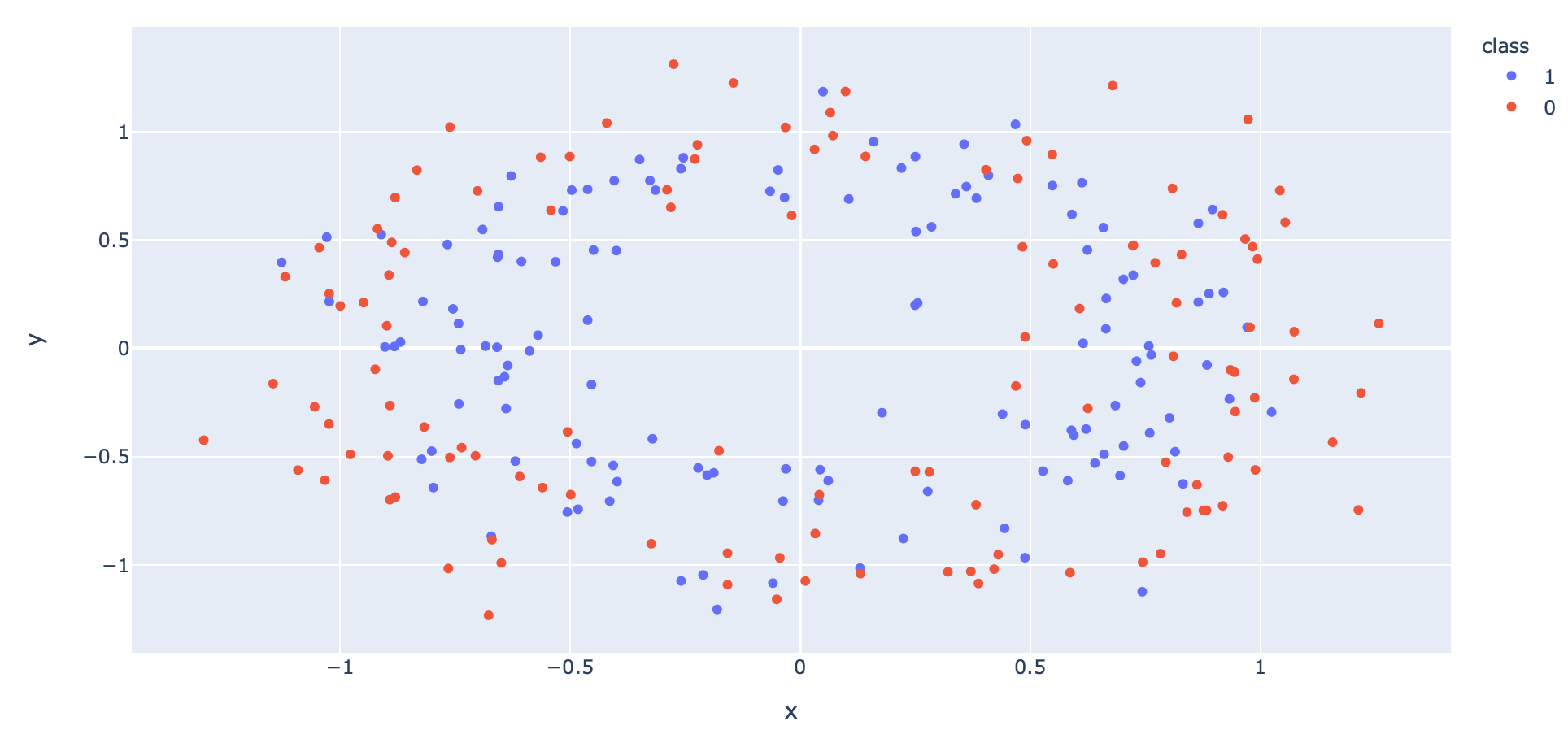
- นิยาม Model
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(60, input_dim=2, activation='relu'))
model.add(tf.keras.layers.Dense(30, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])- Train Model
history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=500, verbose=1)
- Plot Loss
h1 = go.Scatter(y=history.history['loss'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="loss"
)
h2 = go.Scatter(y=history.history['val_loss'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_loss"
)
data = [h1,h2]
layout1 = go.Layout(title='Loss',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Overfit')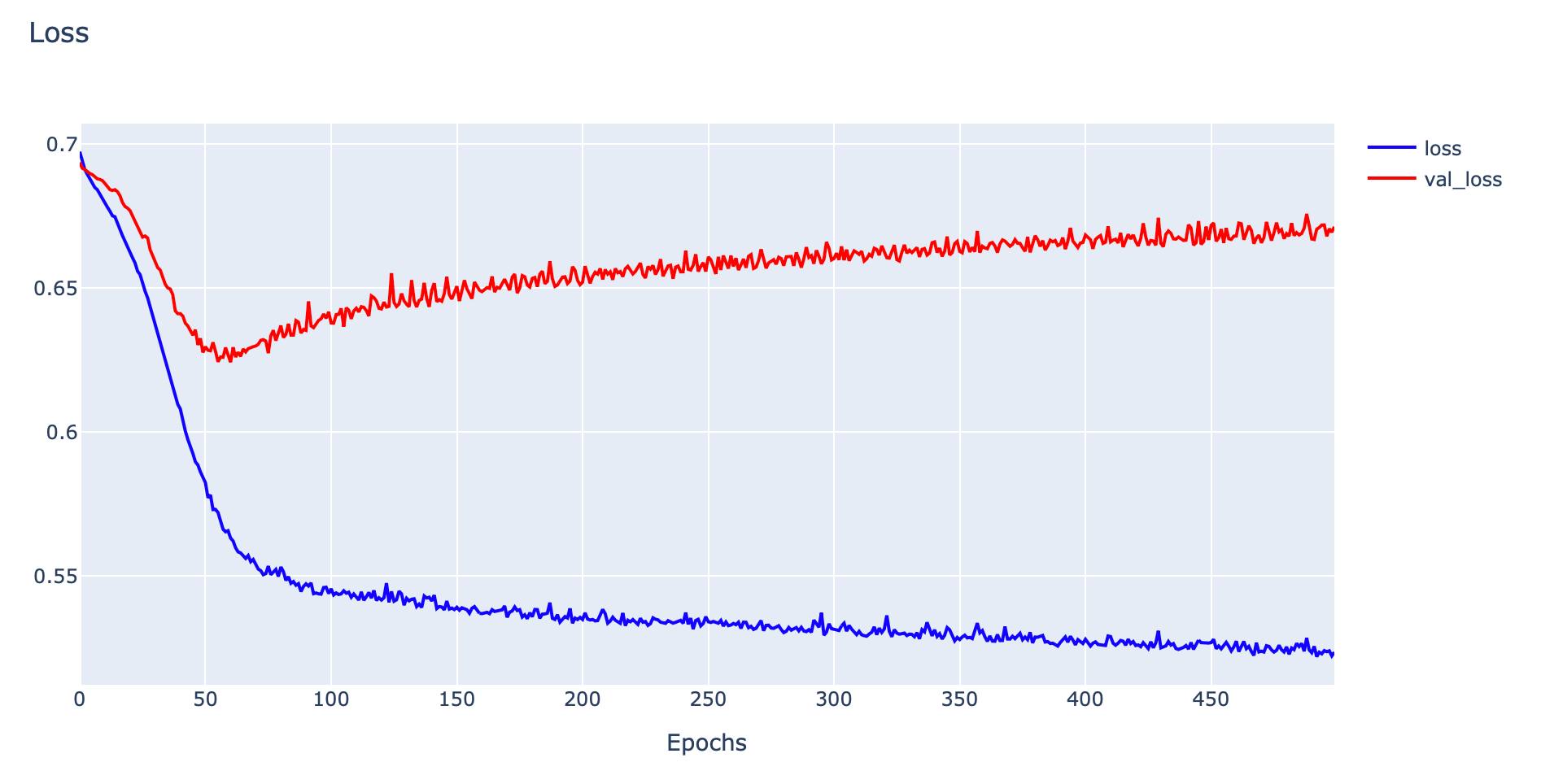
- Plot Accuracy
h1 = go.Scatter(y=history.history['accuracy'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="acc"
)
h2 = go.Scatter(y=history.history['val_accuracy'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_acc"
)
data = [h1,h2]
layout1 = go.Layout(title='Accuracy',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Overfit')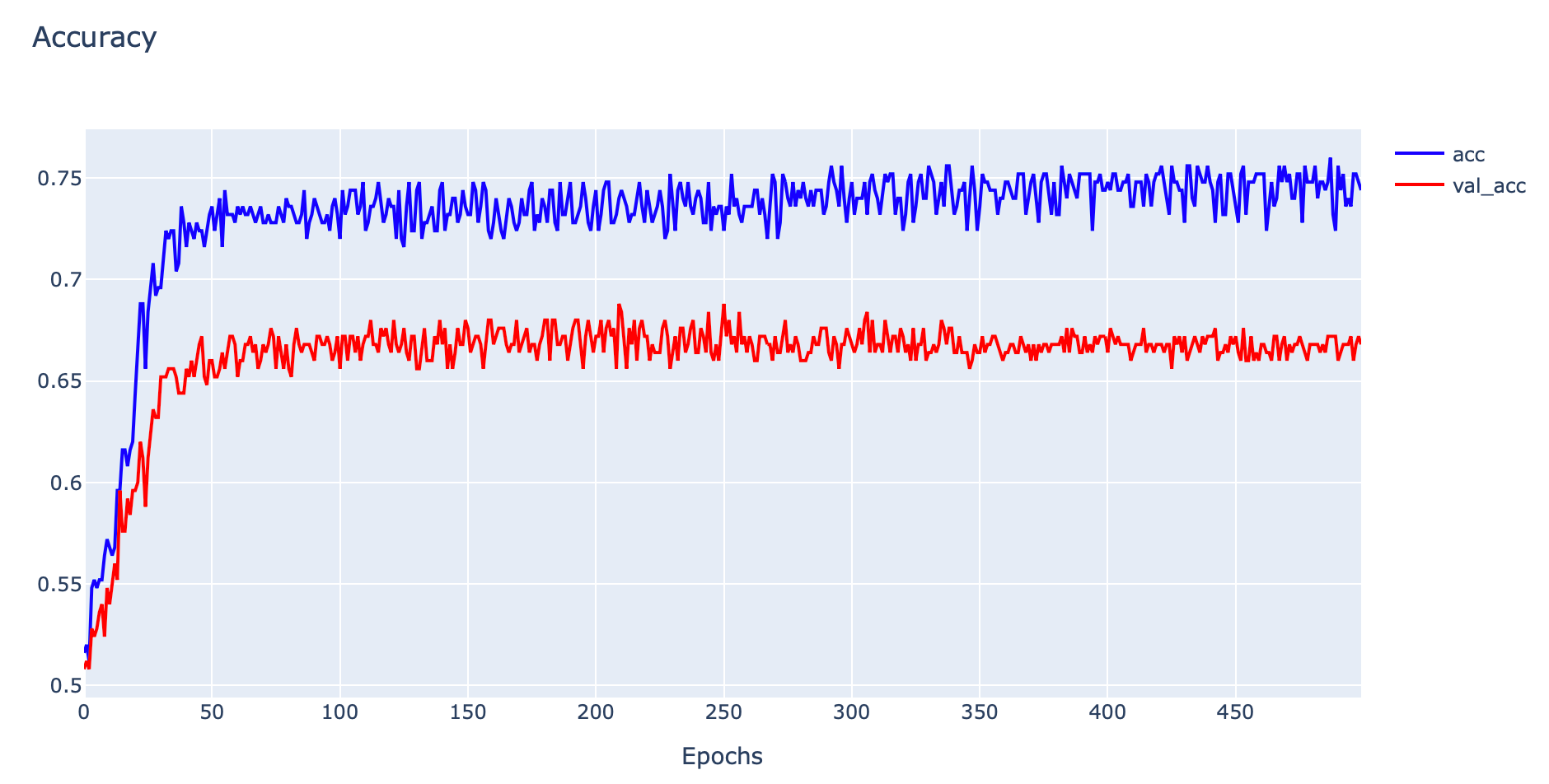
ในการวิเคราะห์ปัญหา Overfitting เราจะพิจารณาจากกราฟ Loss เป็นหลัก ซึ่งจากกราฟ Loss ด้านบน พบว่ายิ่งมีการ Train มากขึ้น ค่า Training Loss จะลงอย่างต่อเนื่อง ขณะที่ Validation Loss จะลดลงถึงจุดหนึ่งแล้วหลังจากนั้นกลับมีการเพิ่มค่าขึ้นเรื่อยๆ
Good Fit Learning Curve
Good Fitting เป็นเป้าหมายในการ Train Model ซึ่งกราฟแบบ Good Fitting จะบ่งบอกว่า Model มีการเรียนรู้ที่ดี เราสามารถนำ Model ไป Predict ข้อมูลที่ไม่เคยพบเห็นได้อย่างแม่นยำ หรือเรียกว่า Model มีความเป็น Generalize ต่อ Data ใหม่ๆ (มี Generalization Error น้อย)
เราจะจำลองสถานการณ์ของ Model แบบ Good Fitting ด้วยการพัฒนา Model เพื่อ Classify ข้อมูลจำนวน 3 Class ตามขั้นตอนดังต่อไปนี้
- สร้าง Dataset แบบ 3 Class โดยใช้ Function make_blobs ของ Sklearn
x, y = make_blobs(n_samples=3000, centers=3, n_features=2, cluster_std=2, random_state=2)- แบ่งข้อมูลสำหรับ Train และ Validate ด้วยการสุ่มในสัดส่วน 60:40
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.4, shuffle= True)
x_train.shape, x_val.shape, y_train.shape, y_val.shape((1800, 2), (1200, 2), (1800,), (1200,))
- นำ Dataset ส่วนที่ Train มาแปลงเป็น DataFrame โดยเปลี่ยนชนิดข้อมูลใน Column "class" เป็น String เพื่อทำให้สามารถแสดงสีแบบไม่ต่อเนื่องได้ แล้วนำไป Plot
x_train_pd = pd.DataFrame(x_train, columns=['x', 'y'])
y_train_pd = pd.DataFrame(y_train, columns=['class'])
df = pd.concat([x_train_pd, y_train_pd], axis=1)
df["class"] = df["class"].astype(str)fig = px.scatter(df, x="x", y="y", color="class")
fig.show()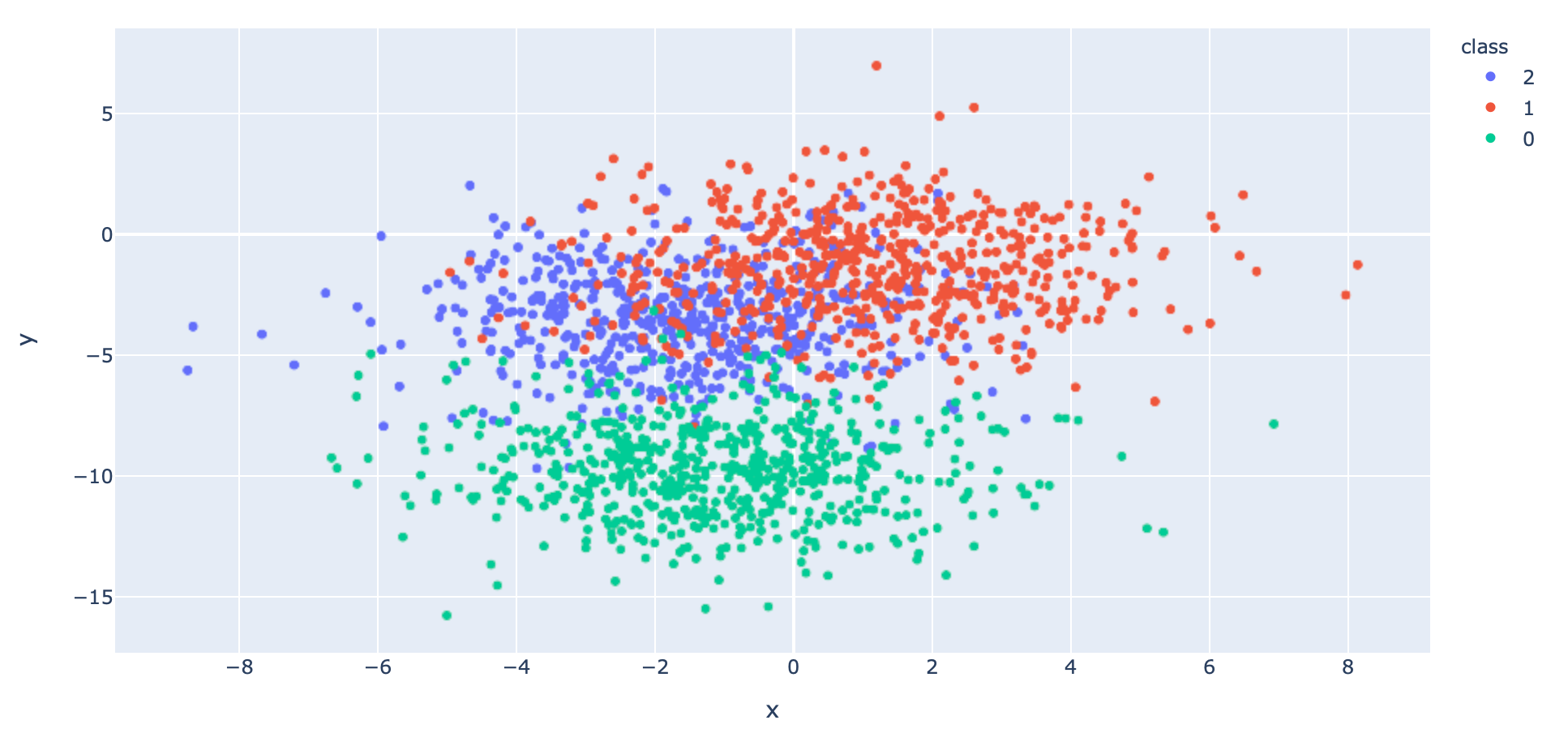
- เข้ารหัสผลเฉลย แบบ One-Hot Encoding เพื่อที่ว่าเมื่อ Model มีการ Predict ว่าเป็น Class ไหน มันจะให้ค่าความมั่นใจ (Confidence) กลับมาด้วย
y_train = to_categorical(y_train)
y_val = to_categorical(y_val)- นิยาม Model
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(tf.keras.layers.Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
- Train Model
history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=200, verbose=1)
- Plot Loss
h1 = go.Scatter(y=history.history['loss'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="loss"
)
h2 = go.Scatter(y=history.history['val_loss'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_loss"
)
data = [h1,h2]
layout1 = go.Layout(title='Loss',
xaxis=dict(title='epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Good Fit')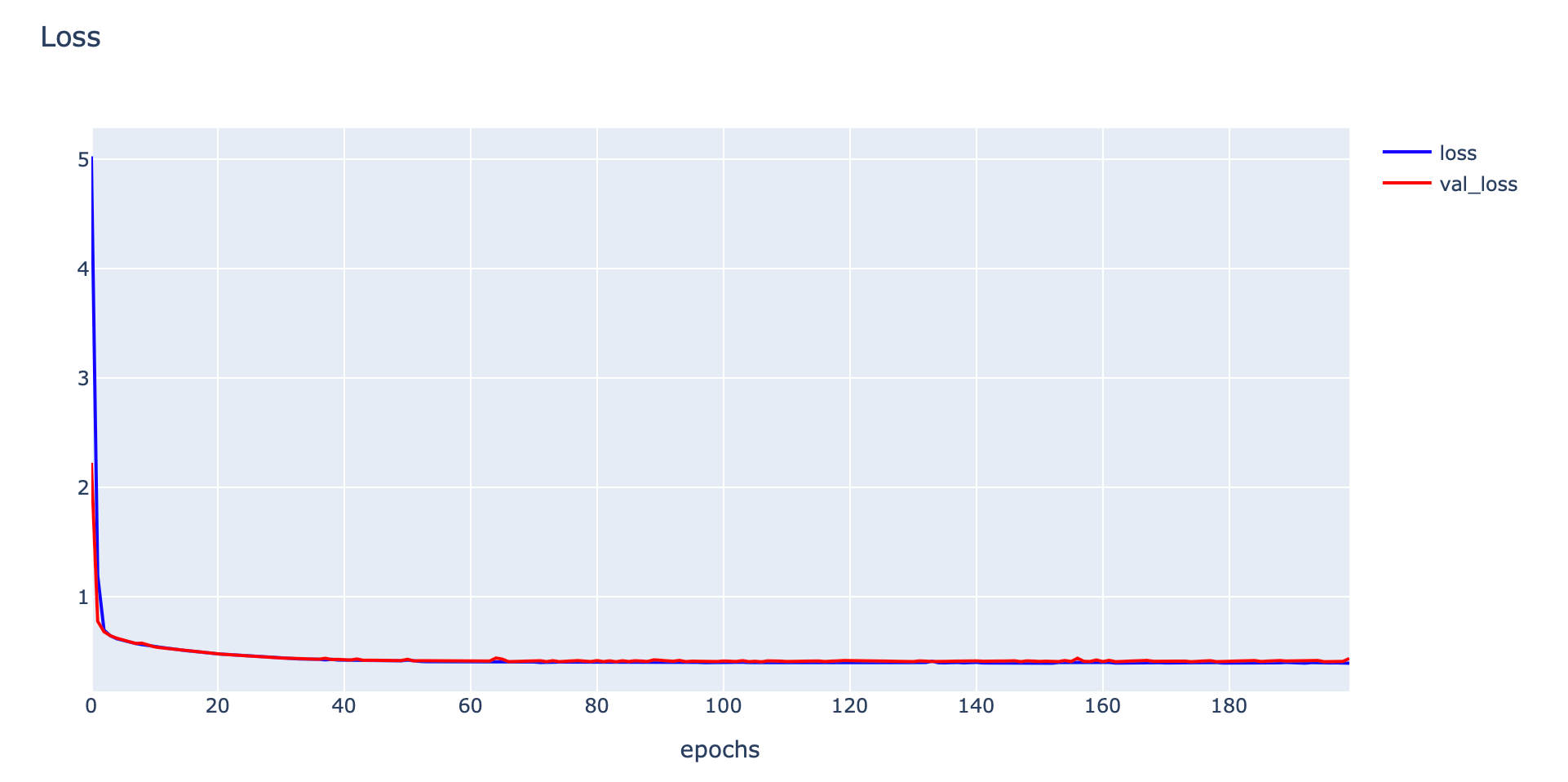
- Plot Accuracy
h1 = go.Scatter(y=history.history['accuracy'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="acc"
)
h2 = go.Scatter(y=history.history['val_accuracy'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_acc"
)
data = [h1,h2]
layout1 = go.Layout(title='Accuracy',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Good Fit')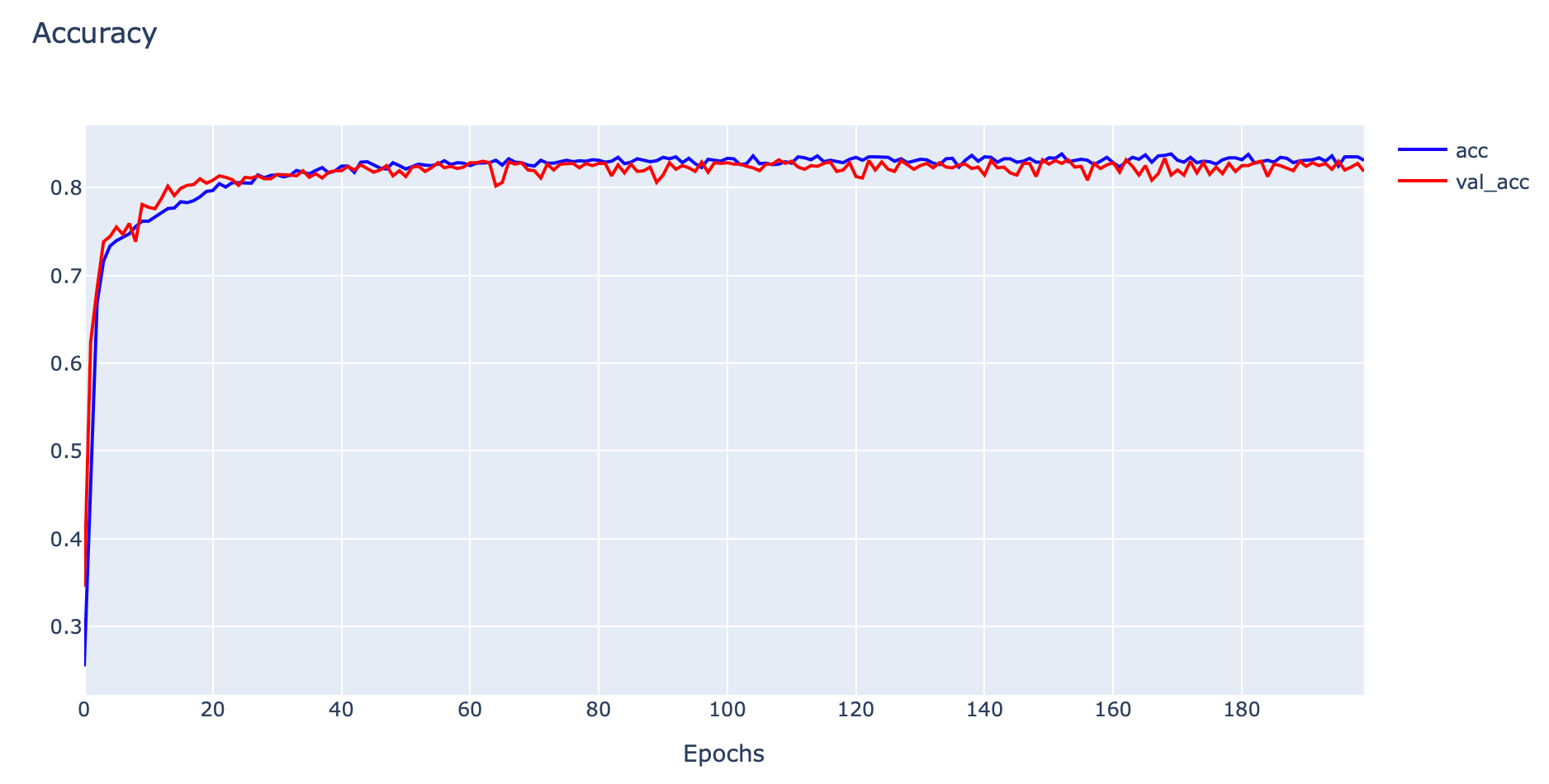
จากกราฟ Loss ด้านบน จะเห็นว่าทั้ง Training Loss และ Validation Loss มีค่าลดลงอย่างต่อเนื่องจนถึงจุดหนึ่งมันจะคงที่ ซึ่งกราฟทั้ง 2 เส้น จะมี Gapระหว่างกันน้อยมาก โดยรูปแบบ Learning Curve ดังกล่าว แสดงว่าเป็น Model แบบ Good Fitting หรือเป็น Model ที่มีการเรียนรู้ที่ดี สามารถนำไป Predict ข้อมูลที่ไม่เคยพบเห็นมาก่อนได้อย่างแม่นยำ
Unrepresentative Train Dataset
นอกจากเราจะใช้ Learning Curve ในการพิจารณาว่า Model มีประสิทธิภาพหรือไม่แล้ว เรายังสามารถพิจารณาจากรูปแบบของ Learning Curve ได้ว่า Dataset (Train และ Validate) ของเราเป็นตัวแทนของข้อมูลที่ดีหรือไม่
โดยจะจำลองสถานการณ์เมื่อ Trainning Dataset ไม่สามารถเป็นตัวแทนของข้อมูลที่ดีได้ ดังขั้นตอนต่อไปนี้
- สร้าง Dataset แบบ 3 Class โดยใช้ Function make_blobs ของ Sklearn
x, y = make_blobs(n_samples=100, centers=3, n_features=2, cluster_std=2, random_state=2)- แบ่งข้อมูลสำหรับ Train และ Validate ด้วยการสุ่มในสัดส่วน 50:50
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.5, shuffle= True)
x_train.shape, x_val.shape, y_train.shape, y_val.shape((50, 2), (50, 2), (50,), (50,))
- นำ Dataset ส่วนที่ Train มาแปลงเป็น DataFrame โดยเปลี่ยนชนิดข้อมูลใน Column "class" เป็น String เพื่อทำให้สามารถแสดงสีแบบไม่ต่อเนื่องได้ แล้วนำไป Plot
x_train_pd = pd.DataFrame(x_train, columns=['x', 'y'])
y_train_pd = pd.DataFrame(y_train, columns=['class'])
df = pd.concat([x_train_pd, y_train_pd], axis=1)
df["class"] = df["class"].astype(str)fig = px.scatter(df, x="x", y="y", color="class")
fig.show()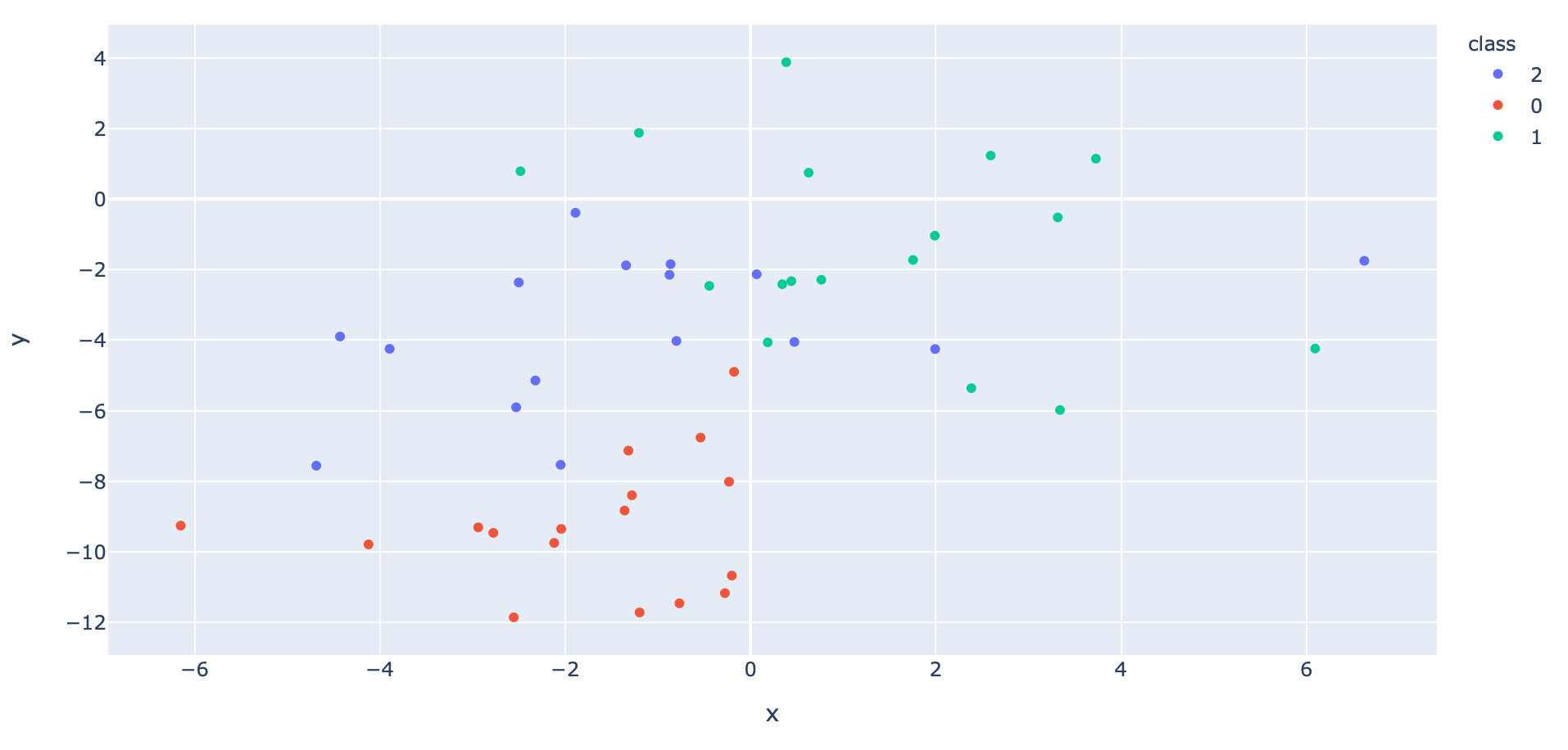
- เข้ารหัสผลเฉลย แบบ One-Hot Encoding เพื่อที่ว่าเมื่อ Model มีการ Predict ว่าเป็น Class ไหน มันจะให้ค่าความมั่นใจ (Confidence) กลับมาด้วย
y_train = to_categorical(y_train)
y_val = to_categorical(y_val)- นิยาม Model
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(tf.keras.layers.Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])- Train Model
history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=200, verbose=1)
- Plot Loss
h1 = go.Scatter(y=history.history['loss'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="loss"
)
h2 = go.Scatter(y=history.history['val_loss'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_loss"
)
data = [h1,h2]
layout1 = go.Layout(title='Loss',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Unrepresentative Train Dataset')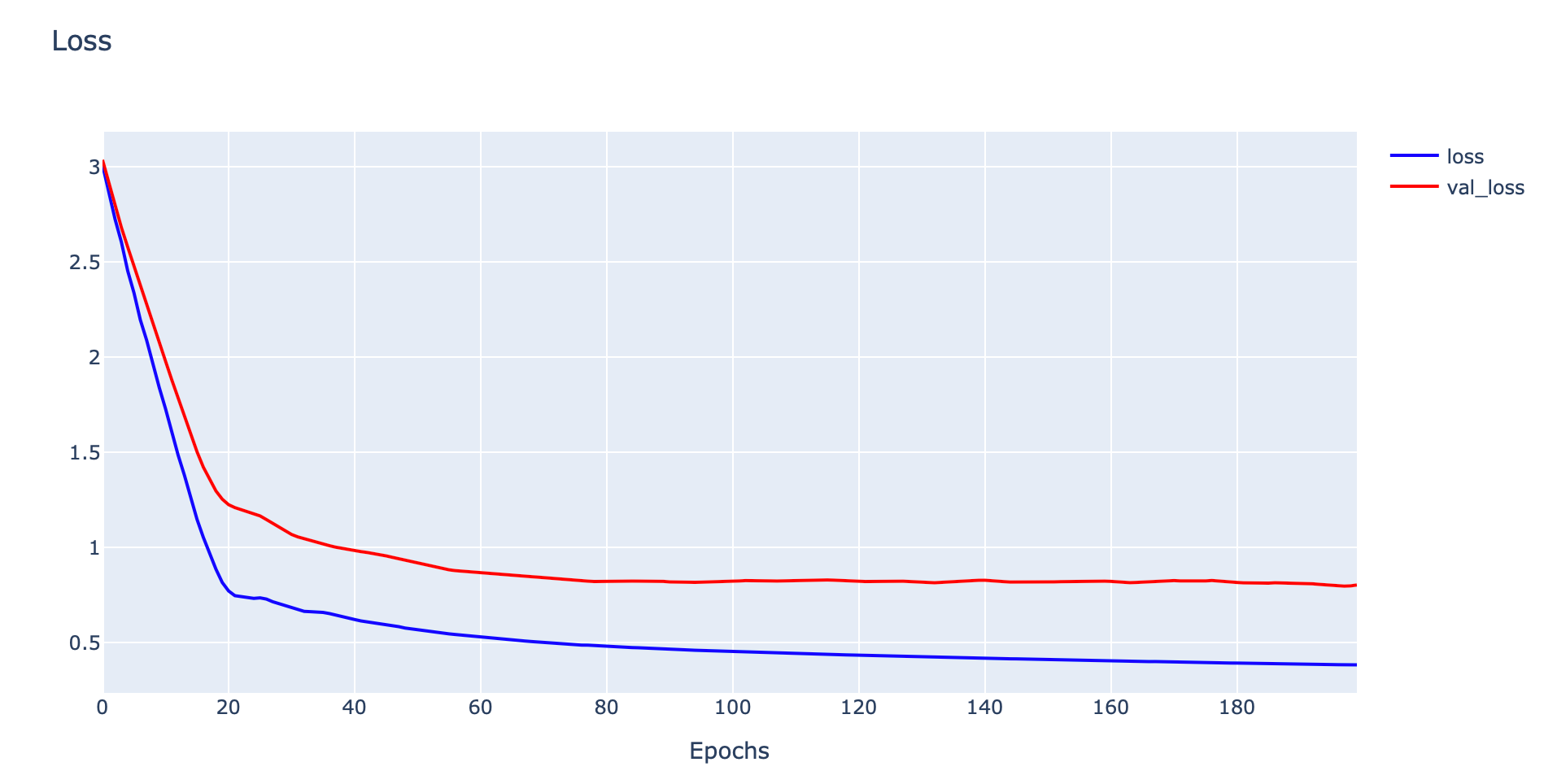
- Plot Accuracy
h1 = go.Scatter(y=history.history['accuracy'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="acc"
)
h2 = go.Scatter(y=history.history['val_accuracy'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_acc"
)
data = [h1,h2]
layout1 = go.Layout(title='Accuracy',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Unrepresentative Train Dataset')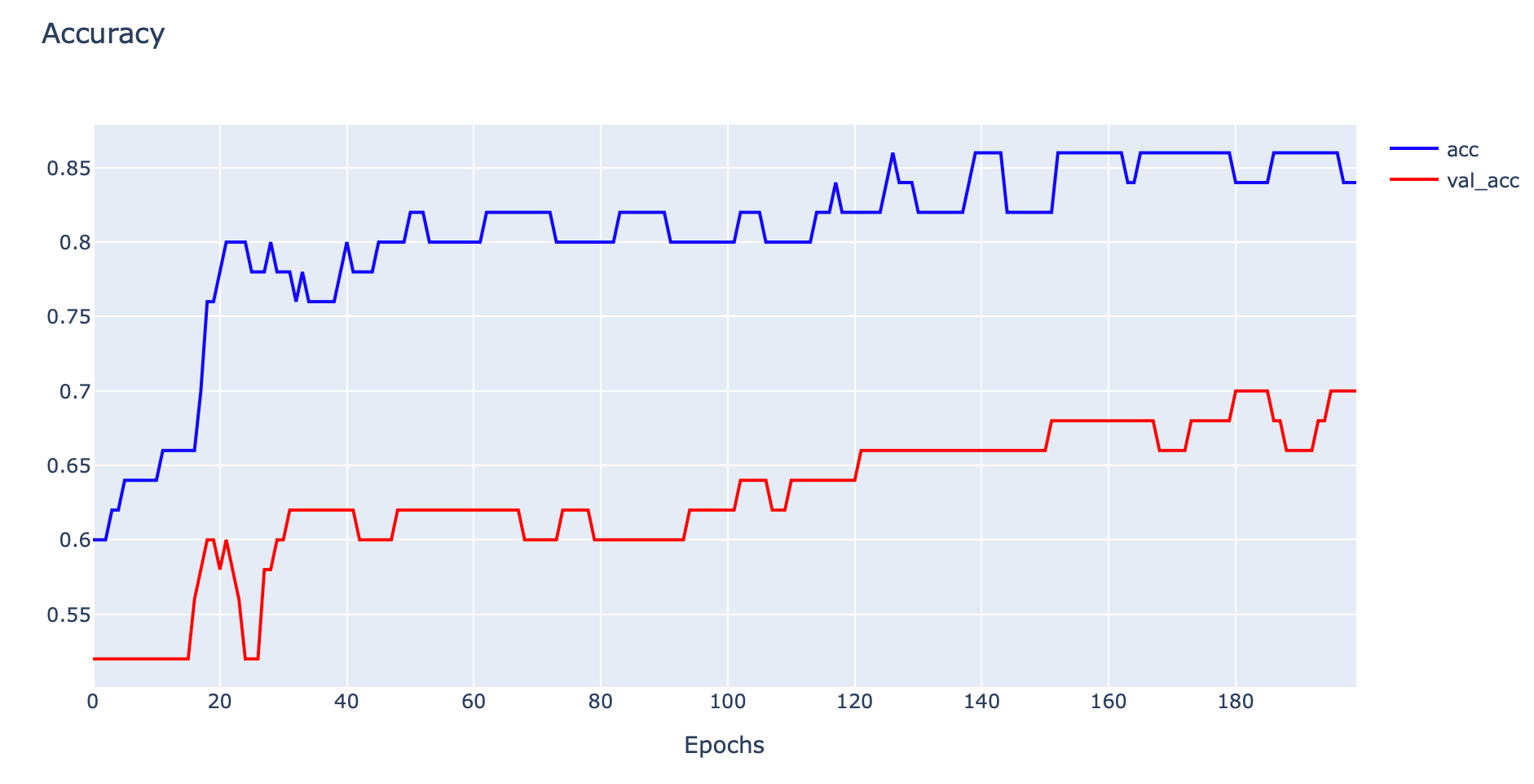
จากกราฟด้านบนพบว่าเมื่อมีการ Train Model มากขึ้น ค่า Loss จะมีแนวโน้มลดลง และ Accuracy มีแนวโน้มเพิ่มขึ้น แต่จะมี Gap ระหว่าง Training Loss กับ Validation Loss รวมทั้ง Gap ระหว่าง Training Accuracy กับ Validation Accuracy สูง ซึ่งแสดงว่าเรามี Training Dataset น้อยไป ไม่เพียงพอในการ Train Model ครับ
Unrepresentative Validation Dataset
เราจะจำลองสถานการณ์ในกรณีที่ Validation Dataset ที่ไม่สามารถเป็นตัวแทนของข้อมูลที่ดี ดังต่อไปนี้
สถานการณ์ที่ 1 Validation Dataset น้อย และไม่สามารถเป็นตัวแทนของ Validation Dataset ได้
สถานการณ์ที่ 2 Validation Dataset น้อย และง่ายเกินไป
สถานการณ์ที่ 1 (Validation Dataset น้อย และไม่สามารถเป็นตัวแทนของ Validation Dataset ได้) มีขั้นตอนการทดลองดังต่อไปนี้
- สร้าง Dataset แบบ 3 Class โดยใช้ Function make_blobs ของ Sklearn
x, y = make_blobs(n_samples=500, centers=3, n_features=2, cluster_std=10, random_state=2)- แบ่งข้อมูลสำหรับ Train และ Validate ด้วยการสุ่มในสัดส่วน 95:5
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.05, shuffle= True)
x_train.shape, x_val.shape, y_train.shape, y_val.shape((475, 2), (25, 2), (475,), (25,))
- นำ Dataset ส่วนที่ Train มาแปลงเป็น DataFrame โดยเปลี่ยนชนิดข้อมูลใน Column "class" เป็น String เพื่อทำให้สามารถแสดงสีแบบไม่ต่อเนื่องได้ แล้วนำไป Plot
x_train_pd = pd.DataFrame(x_train, columns=['x', 'y'])
y_train_pd = pd.DataFrame(y_train, columns=['class'])
df = pd.concat([x_train_pd, y_train_pd], axis=1)
df["class"] = df["class"].astype(str)fig = px.scatter(df, x="x", y="y", color="class")
fig.show()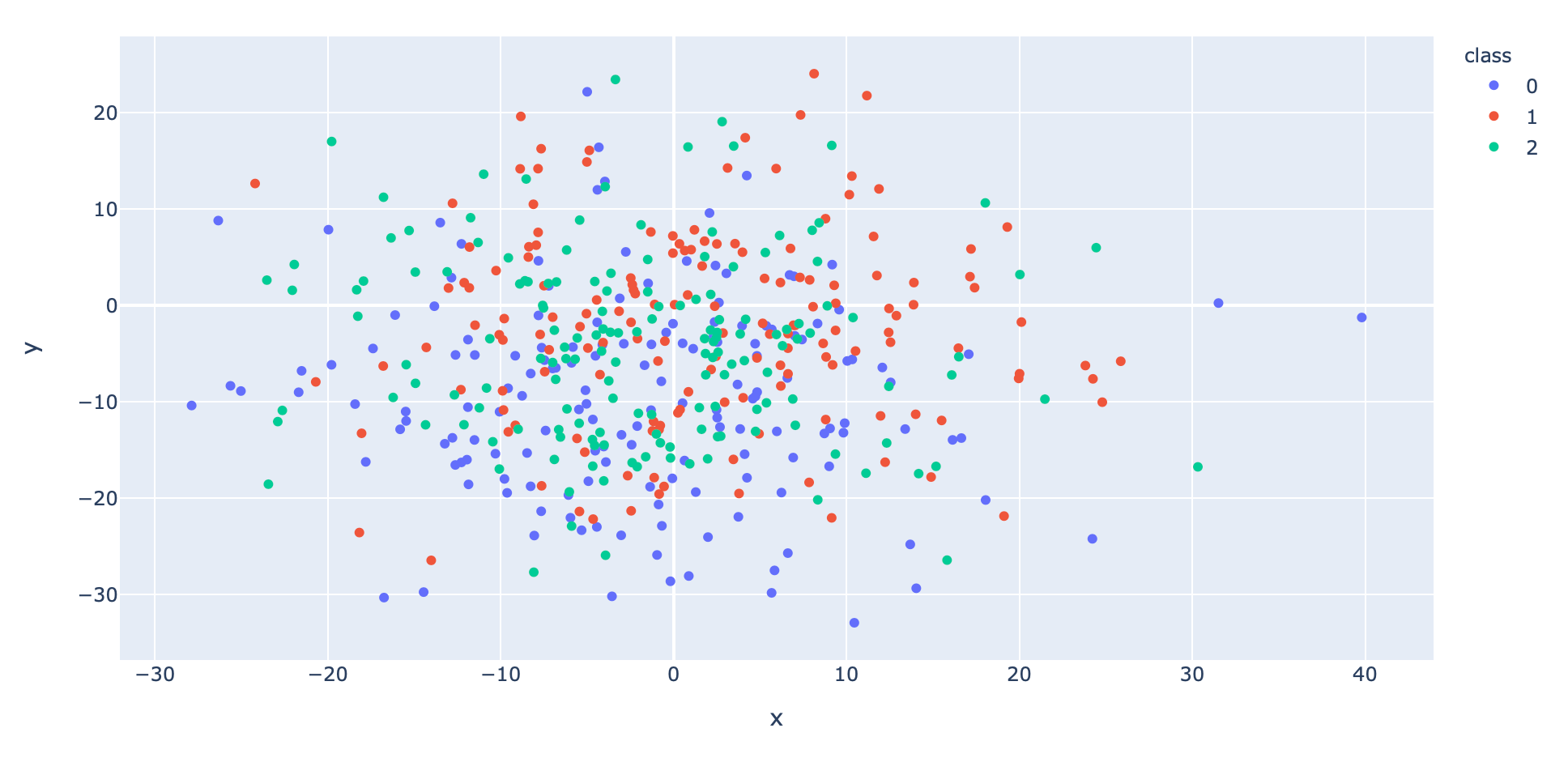
- เข้ารหัสผลเฉลย แบบ One-Hot Encoding เพื่อที่ว่าเมื่อ Model มีการ Predict ว่าเป็น Class ไหน มันจะให้ค่าความมั่นใจ (Confidence) กลับมาด้วย
y_train = to_categorical(y_train)
y_val = to_categorical(y_val)- นิยาม Model
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(tf.keras.layers.Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])- Train Model
history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=200, verbose=1)
- Plot Loss
h1 = go.Scatter(y=history.history['loss'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="loss"
)
h2 = go.Scatter(y=history.history['val_loss'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_loss"
)
data = [h1,h2]
layout1 = go.Layout(title='Loss',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Unrepresentative Validation Dataset')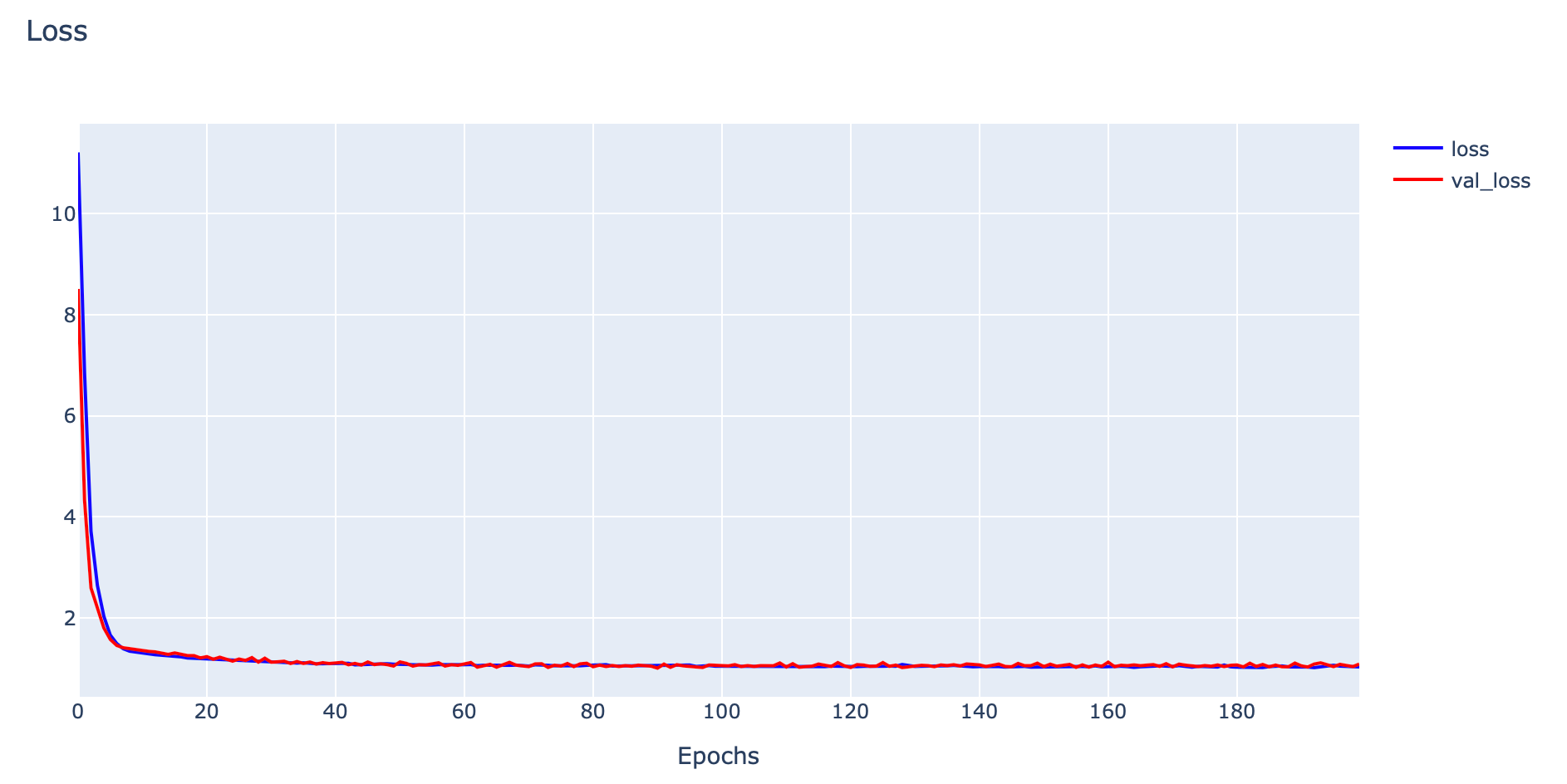
- Plot Accuracy
h1 = go.Scatter(y=history.history['accuracy'],
mode="lines", line=dict(
width=2,
color='blue'),
name="acc"
)
h2 = go.Scatter(y=history.history['val_accuracy'],
mode="lines", line=dict(
width=2,
color='red'),
name="val_acc"
)
data = [h1,h2]
layout1 = go.Layout(title='Accuracy',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Unrepresentative Validation Dataset')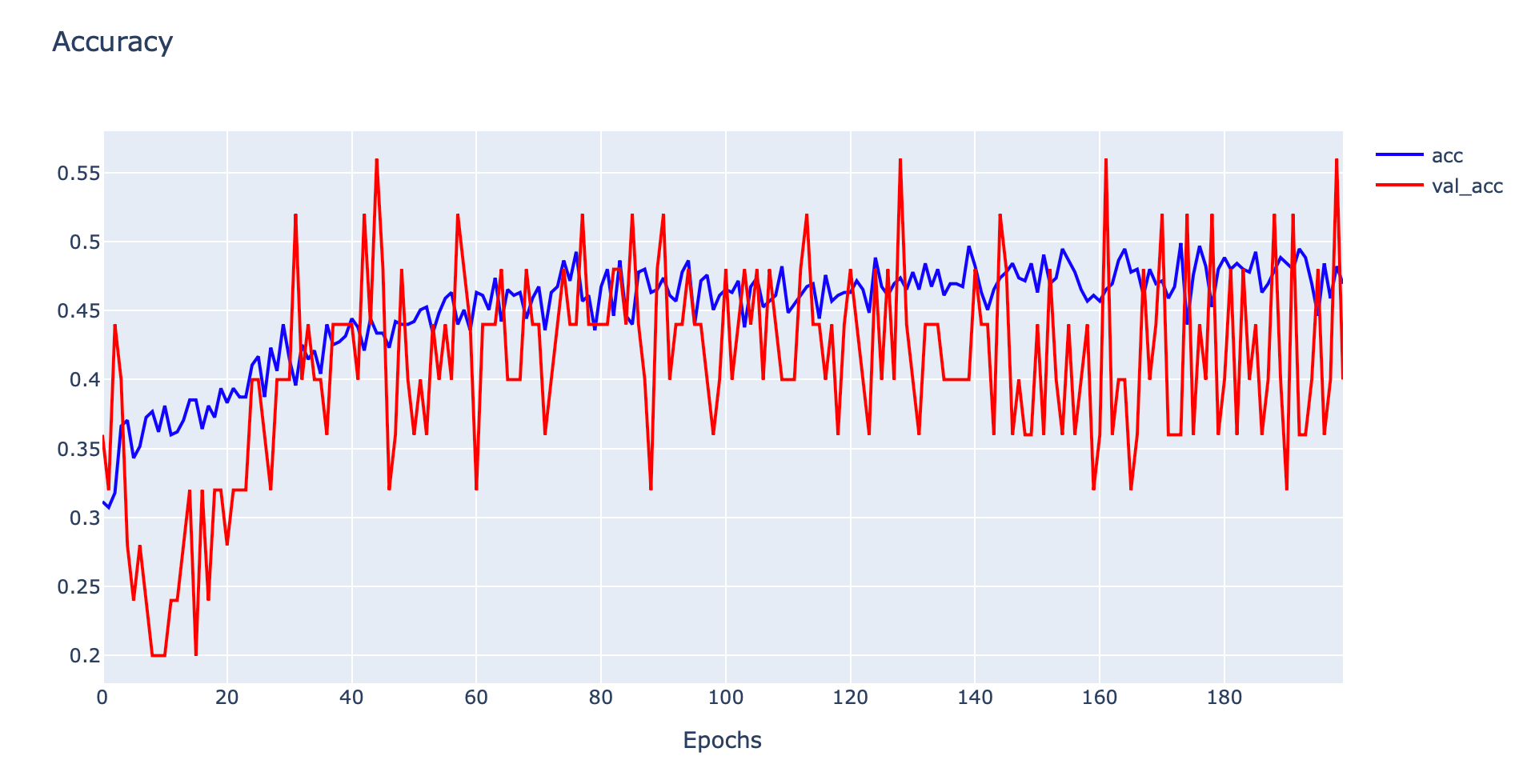
ในกรณีที่ Validation Dataset น้อย และไม่สามารถเป็นตัวแทนของ Validation Dataset ได้ เราจะเห็นค่า Training Loss ค่อยๆ ลดลงแบบเดียวกับในกรณี Good Fitting แต่ Validation Loss จะแกว่งไปมาเหมือนการสุ่มอยู่รอบๆ กราฟ Training Loss เช่นเดียวกันกับที่เมื่อพิจารณาจากกราฟ Accuracy จะพบว่าค่า Validation Accuracy จะแกว่งไปมาเหมือนการสุ่มอยู่รอบๆ กราฟ Training Accuracy
สถานการณ์ที่ 2 (Validation Dataset น้อย และง่ายเกินไป) มีขั้นตอนการทดลองดังต่อไปนี้
- สร้าง Dataset แบบ 3 Class โดยใช้ Function make_blobs ของ Sklearn
x, y = make_blobs(n_samples=400, centers=3, n_features=2, cluster_std=2, random_state=2)- แบ่งข้อมูลสำหรับ Train และ Validate ด้วยการสุ่มในสัดส่วน 97:3
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.03, shuffle= True)
x_train.shape, x_val.shape, y_train.shape, y_val.shape((485, 2), (15, 2), (485,), (15,))
- นำ Dataset ส่วนที่ Train มาแปลงเป็น DataFrame โดยเปลี่ยนชนิดข้อมูลใน Column "class" เป็น String เพื่อทำให้สามารถแสดงสีแบบไม่ต่อเนื่องได้ แล้วนำไป Plot
x_train_pd = pd.DataFrame(x_train, columns=['x', 'y'])
y_train_pd = pd.DataFrame(y_train, columns=['class'])
df = pd.concat([x_train_pd, y_train_pd], axis=1)
df["class"] = df["class"].astype(str)fig = px.scatter(df, x="x", y="y", color="class")
fig.show()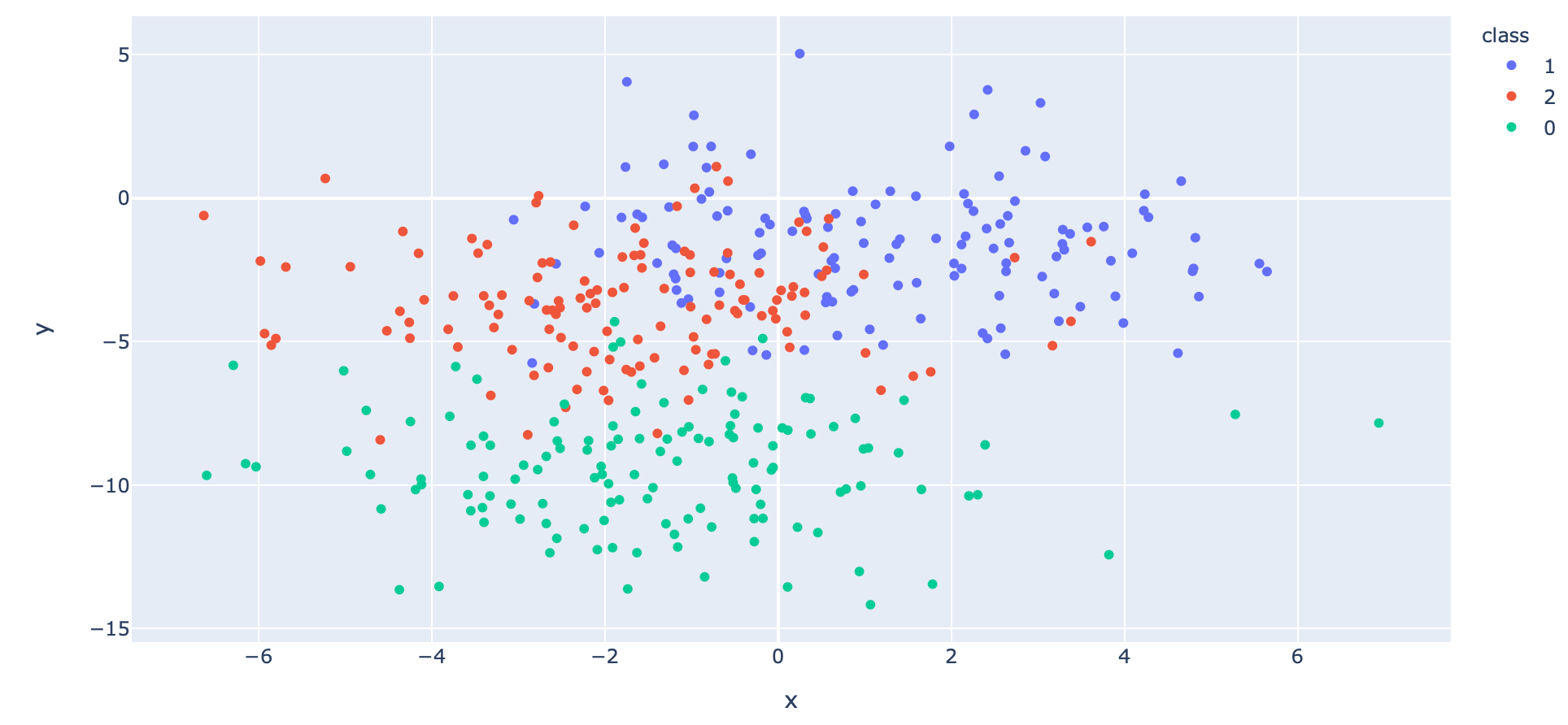
- เข้ารหัสผลเฉลย แบบ One-Hot Encoding เพื่อที่ว่าเมื่อ Model มีการ Predict ว่าเป็น Class ไหน มันจะให้ค่าความมั่นใจ (Confidence) กลับมาด้วย
y_train = to_categorical(y_train)
y_val = to_categorical(y_val)- นิยาม Model
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(50, input_dim=2, activation='relu', kernel_initializer='he_uniform'))
model.add(tf.keras.layers.Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])- Train Model
history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=200, verbose=1)
- Plot Loss
h1 = go.Scatter(y=history.history['loss'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="loss"
)
h2 = go.Scatter(y=history.history['val_loss'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_loss"
)
data = [h1,h2]
layout1 = go.Layout(title='Loss',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Unrepresentative Validation Dataset')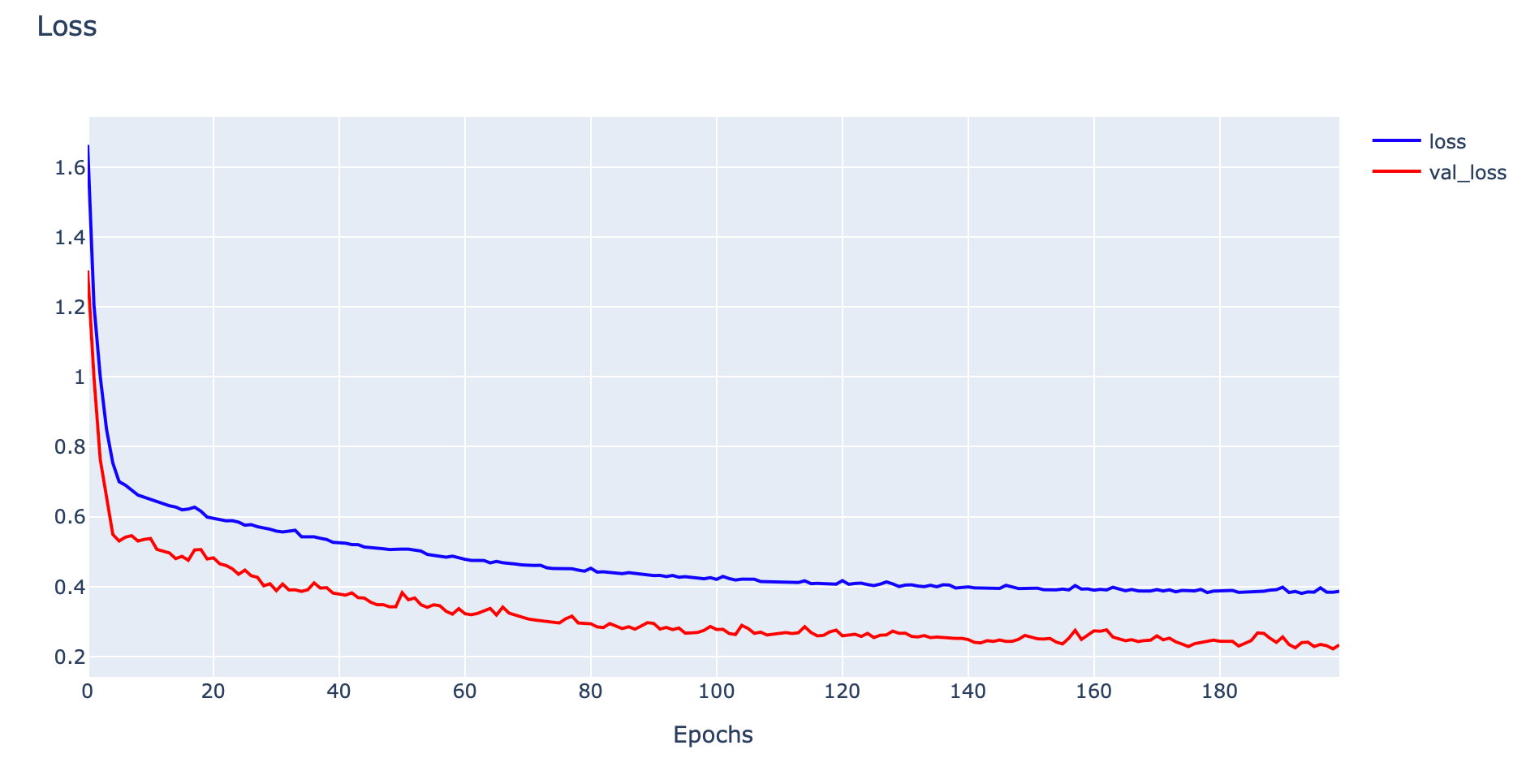
- Plot Accuracy
h1 = go.Scatter(y=history.history['accuracy'],
mode="lines",
line=dict(
width=2,
color='blue'),
name="acc"
)
h2 = go.Scatter(y=history.history['val_accuracy'],
mode="lines",
line=dict(
width=2,
color='red'),
name="val_acc"
)
data = [h1,h2]
layout1 = go.Layout(title='Accuracy',
xaxis=dict(title='Epochs'),
yaxis=dict(title=''))
fig1 = go.Figure(data = data, layout=layout1)
plotly.offline.iplot(fig1, filename='Unrepresentative Validation Dataset')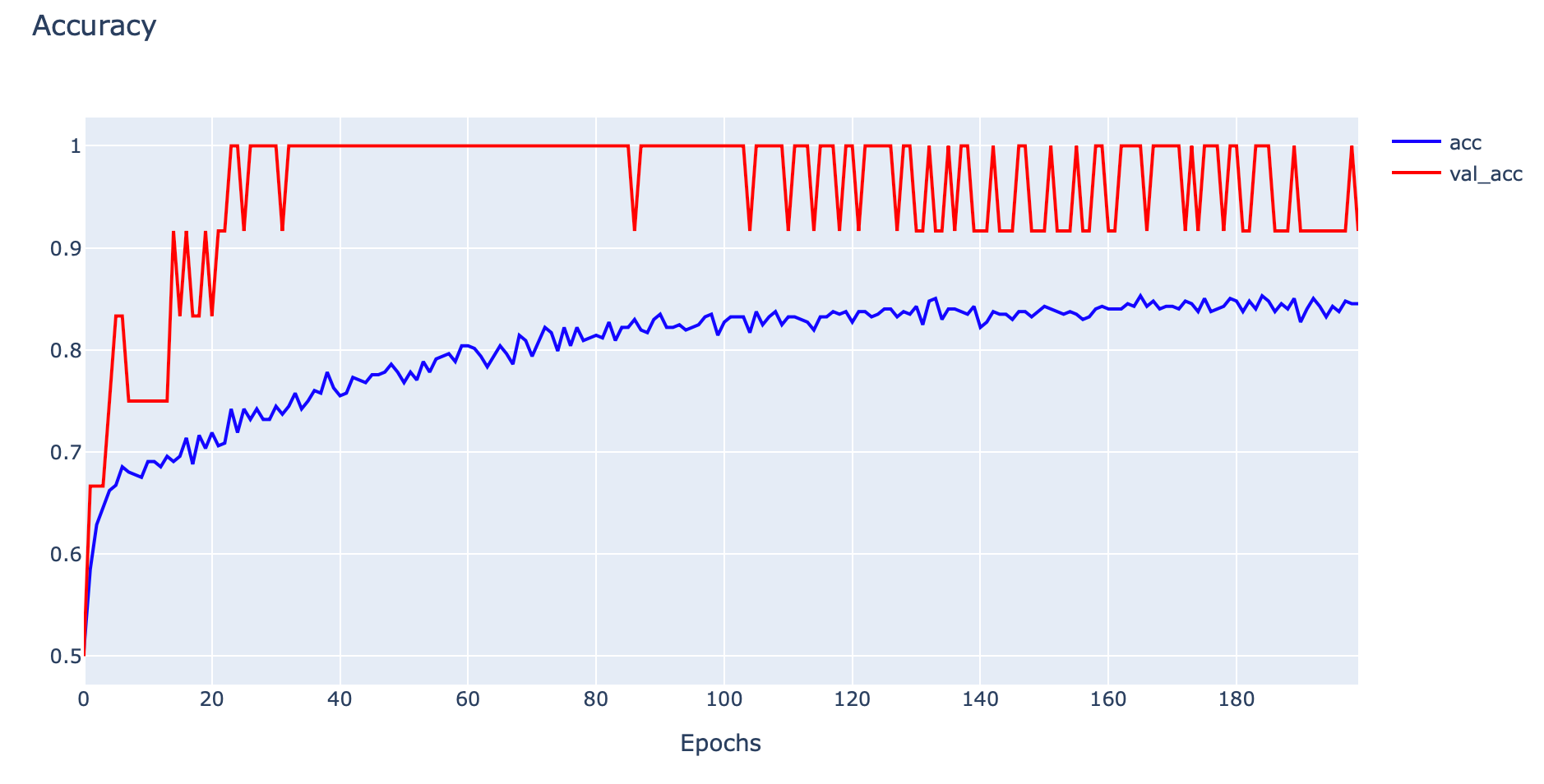
ในกรณีที่ Validation Dataset น้อย และง่ายจนเกินไป เราจะเห็นค่า Training Loss และ Validate Loss ลดลง โดยที่ค่า Validate Loss จะต่ำกว่า Training Lossในทางตรงกันข้าม เมื่อพิจารณาจากกราฟ Accuracy จะพบว่าค่า Training Accuracy และ Validate Accuracy จะเพิ่มขึ้น โดยที่ค่า Validate Accuracy จะสูงกว่า Training Accuracy ครับ